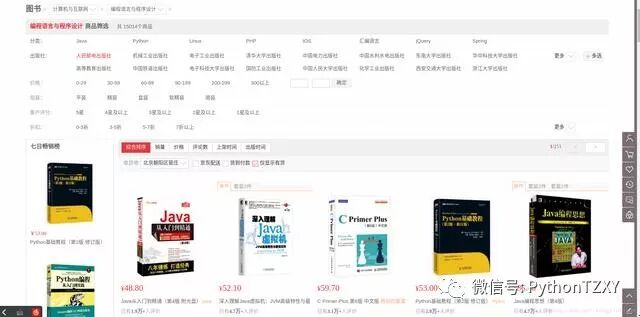
假如我们想把京东商城图书类的图片类商品图片全部下载到本地,通过手工复制粘贴将是一项非常庞大的工程,此时,可以用Python网络爬虫实现,这类爬虫称为图片爬虫,接下来,我们将实现该爬虫。


私信小编01.02.03.04即可获取数十套PDF哦!
在每页中,我们都要提取对应的图片,可以使用正则表达式匹配源码中图片的链接部分,然后通过urllib.request.urlretrieve()将对应链接的图片保存到本地。
但是这里有一个问题,该网页中的图片不仅包括列表中的商品图片,还包括旁边的一些无关图片,所以我们可以先进行一次信息过滤,第一次信息过滤将中间的商品列表部分数据留下,将其他部分的数据过滤掉。可以单击右键,然后查看网页的源代码,如图:
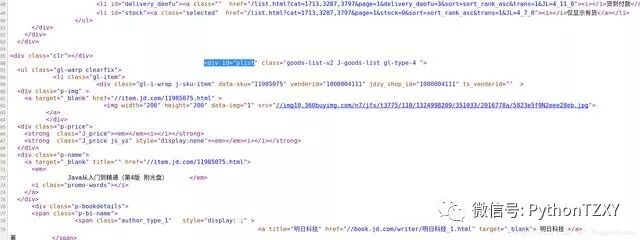
所以,如果要进行第一次过滤,我们的正则表达式可以构造为:
1
进行了第一次信息过滤后,留下来的图片链接就是我们想爬取的图片了,下一步需要在第一次过滤的基础上,再将图片链接信息过滤出来。
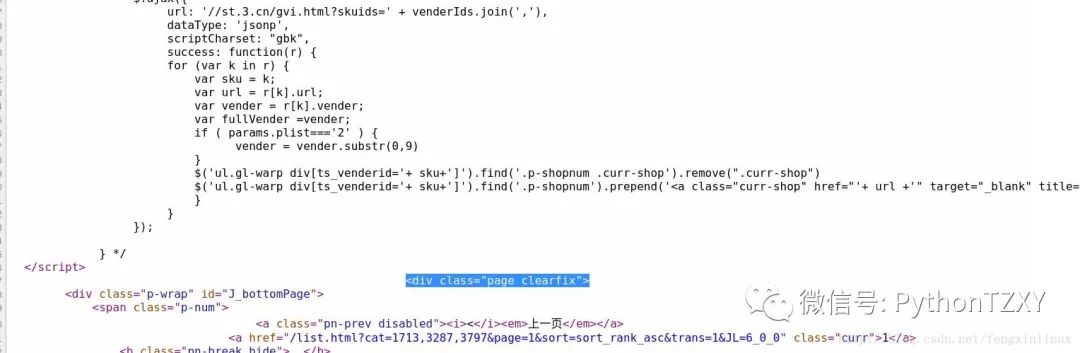
此时,需要观察网页中对应图片的源代码,我们观察到其中两张图片的对应源码:
图片1:

图片2:

对比两张图片代码,发现其基本格式是一样的,只是图片的链接网址不一样,所以此时,我们根据该规律构造出提取图片链接的正则表达式:
)
1
刚开始到这里,我以为就结束了,后来在爬取的过程中我发现每一页都少爬取了很多图片,再次查看源码发现,每页后面的几十张图片又是另一种格式:
![]()
1
所以,完整的正则表达式应该是这两种格式的或:
|![]()
1
到这里,我们根据该正则表达式,就可以提取出一个页面中所有想要爬取的图片链接。
所以,根据上面的分析,我们可以得到该爬虫的编写思路与过程,具体如下:
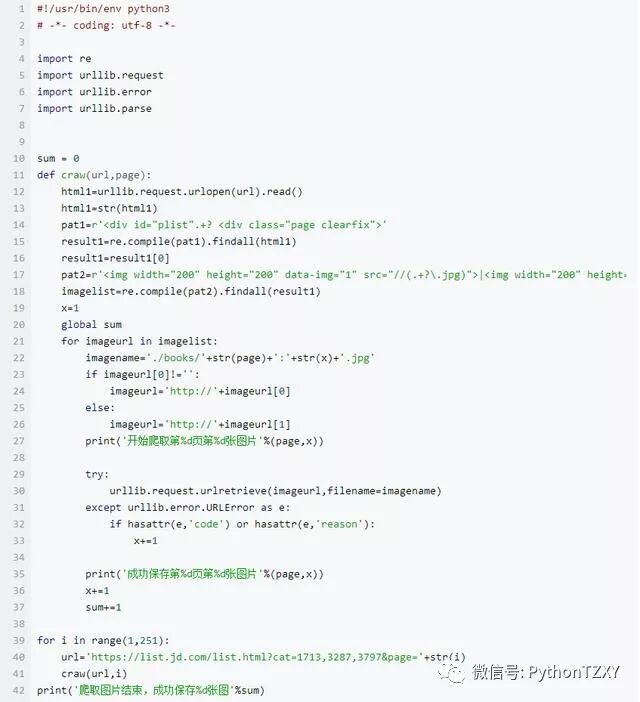
建立一个爬取图片的自定义函数,该函数负责爬取一个页面下的我们想爬取的图片,爬取过程为:首先通过urllib.request.utlopen(url).read()读取对应网页的全部源代码,然后根据上面的第一个正则表达式进行第一次信息过滤,过滤完成之后,在第一次过滤结果的基础上,根据上面的第二个正则表达式进行第二次信息过滤,提取出该网页上所有的目标图片的链接,并将这些链接地址存储的一个列表中,随后遍历该列表,分别将对应链接通过urllib.request.urlretrieve(imageurl,filename=imagename)存储到本地,为了避免程序中途异常崩溃,我们可以建立异常处理。
通过for循环将该分类下的所有网页都爬取一遍,链接可以构造为url='https://list.jd.com/list.html?cat=1713,3287,3797&page=' + str(i)
完整的代码如下:
运行结果如下:
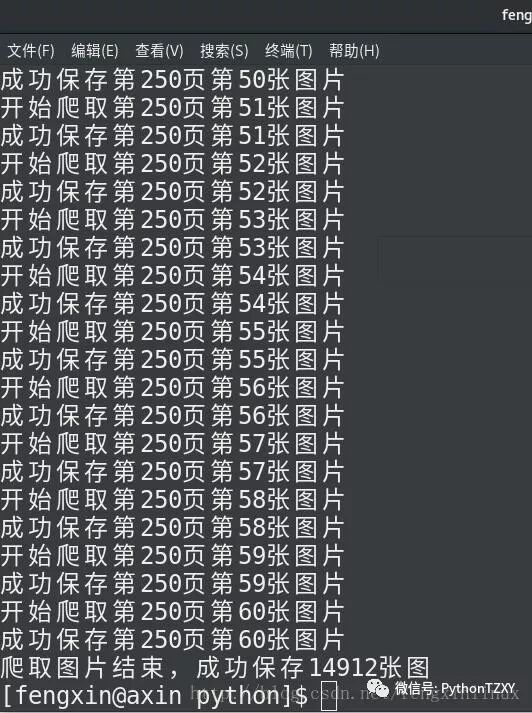
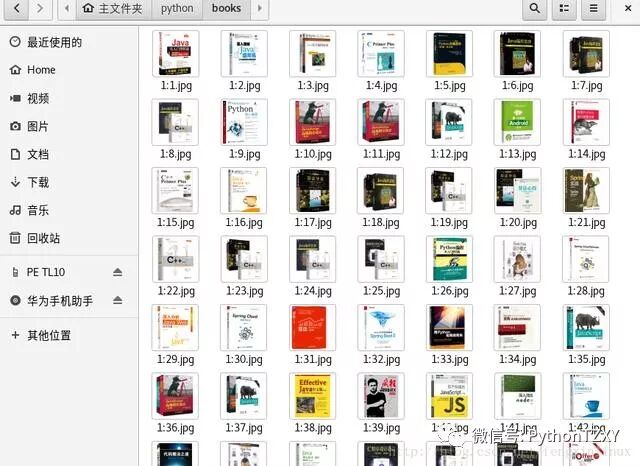
完美,到此结束!源码请私信我!~
长按二维码向我转账

受苹果公司新规定影响,微信 iOS 版的赞赏功能被关闭,可通过二维码转账支持公众号。










)

