转眼又到了十一黄金婚礼季
说到婚礼,最不可或缺的是什么?
是房子吗?是车子吗?
No No No
房车是加分项
但一颗blingbling的钻戒可是送命题呀!

那么广大的朋友们
你们具备鉴别钻石真实价值的火眼金睛吗?
如何获取24K大钻石的真实价值?
接下来,就由魔术师带领大家一起学习吧!
(详情代码请关注公众号,回复“钻石”即可获得)
案例背景
数据集中有53940条钻石各类属性以及其成交价格的记录,我们想利用上述信息,使用数据处理的方法估计给定属性的钻石的合理价格。
01
数据结构与分析
数据来源于kaggle网站中来自印度的用户shivamagrawa的分享
数据的下载链接https://www.kaggle.com/shivam2503/diamonds/data
从FL(完美无瑕),IF, VVS1, VVS2, VS1, VS2, SI1, SI2, I1, I2, I3(三级夹杂物)
钻石朝上时,可见的表面的宽度,以其平均直径的百分比表示(数字)
STEP1:
通过比较简单的线性回归模型找出众多属性中对价格影响比较大的因素,进一步确定价格和各个主要因素之间的可能关系(通过将价格取对数以及在线性回归模型中添加交互项、平方项等)。
STEP2:
取出主要因素,使用决策树、随机森林以及神经网络模型来构建价格估计的模型,对比三者的误差衡量指标NMSE(Normalized Mean Square Error,标准均方误差)评估各个模型的优劣。
NMSE(Normalized Mean SquareError 标准均方误差):
NMSE是一种比较常用的指标,他通过对比实际值 和预测值
和预测值 来确定预测的准确程度。其计算公式为:
来确定预测的准确程度。其计算公式为:
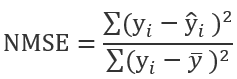
NMSE的值大于1,证明简单的求平均运算的预测效果都要好于当前的预测模型,也就是预测的效果比较差。所以NMSE越小,证明模型的拟合效果越好。
02
探索性分析
首先将数据载入R中,在R console界面可以使用对应语句读入数据,将当前工作目录设置为数据文件所在的文件夹。(参考:机器学习| 一个简单的入门实例-员工离职预测)
使用read.table命令读入数据:

使用View(head(da,50))概览数据前20条:
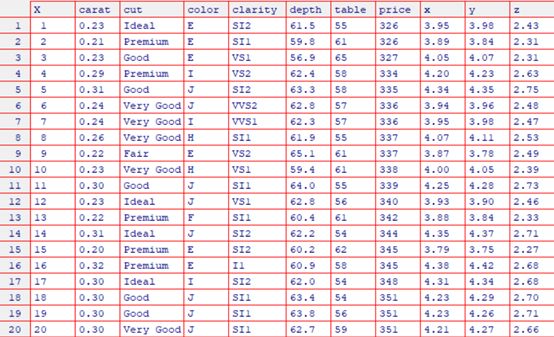
我们比较关心的是数据集种有没有缺失值和异常值。
① 检查缺失值:
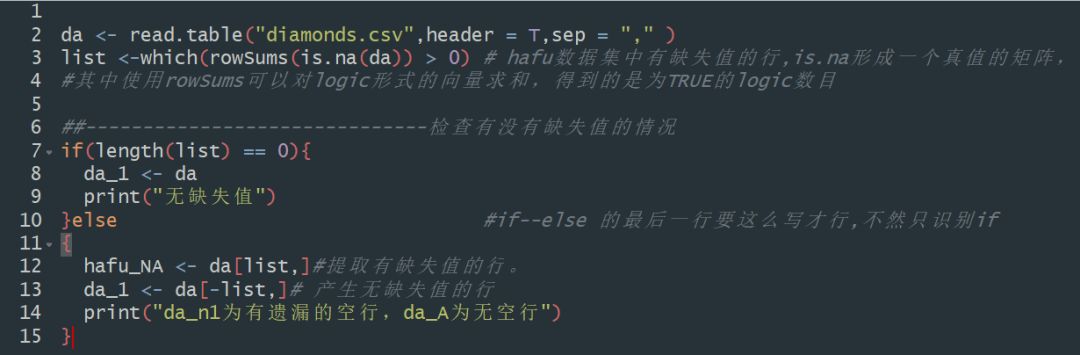
其中is.na(da) 返回的是一个矩阵,然后使用rowSums可以自动计算一行中为TRUE的个数,也就是计出一行有多少个空值,which可以自动返回行号。
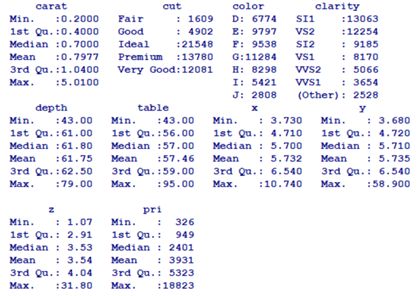
② 检查异常值:使用 summary(da_1) 检查有没有异常值,该函数可以自动描述对象中数据的性质。
经检验数据集中没有缺失部分。总体的描述如下:
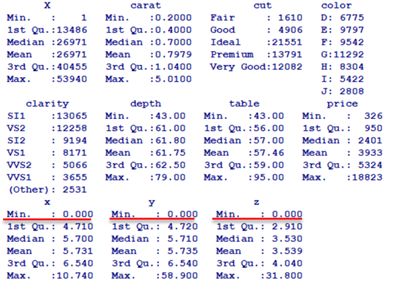
发现该数据集中,有x,y,z同时为零的情况,我们认为这个情况属于记录丢失。去掉这些记录,重新看总体描述,实际上去掉这些样本对整体情况的影响不大。
对这些异常数据的处理是:

去掉同时为0的数据,在data.frame格式中,索引行或列号为负的操作为:取出除了目标行或列外其他所有行或列。
再次使用summary函数查看数据全貌。(是的,summary函数真的很好用,table函数也很好用)
03
探索各变量和价格的关系
作图分析部分
(这一部分主要是使用作图的方法来考察不同变量与价格关系,初步确定线性方程的可能形式)
首先对钻石行内非常看重的4C(color,clarity,cut,carat)进行分析,因为carat是数值型变量,在这里就不作图展示了,下面作图使用的是R中自带的plot函数。(其中col参数可以改变图形颜色)
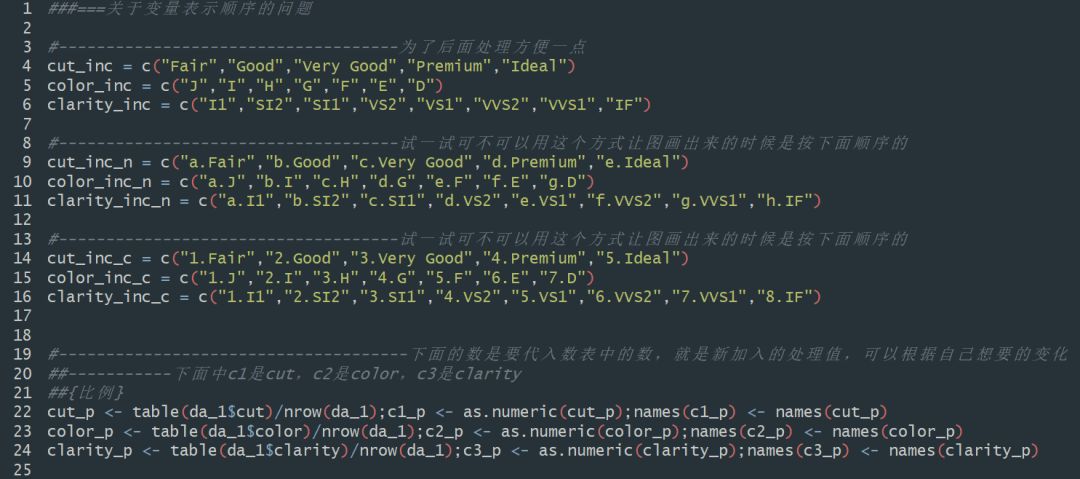
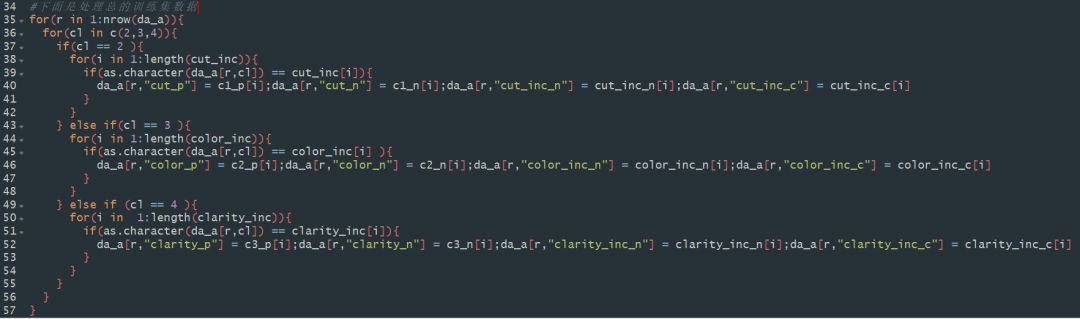
STEP1 :给标签加上序号
原来的数据中,数据的标签格式是没有序号的,在绘图过程中,会按照其字母顺序排列,这个顺序往往不是我们想要的,所以,在这里我们给不同标签的品质按从差到好的顺序加上序号。
代码逻辑比较直接就是找出来每个记录对应的属性,然后新生成一个标签放入我想要的对应的新标签(这里包括加上序号的操作,以及使类别变量数量化的操作):


最后我们发现使用序数就可以得到我们想要的绘图顺序了(而具体的类别变量的取舍是由后面的线性回归确定的,最后确定下来的是给统一标签下的不同级别赋予不同的得分级别可以更好的拟合,得分级别的确定主要从后面的气泡图中得到)
STEP2: 作图分析clarity、Color、Cut与price的关系

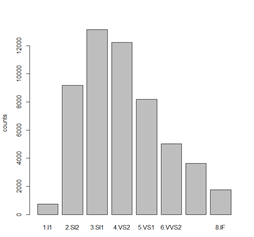
Clarity

Color
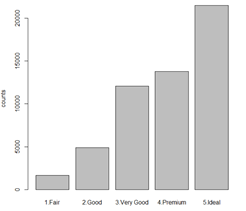
Cut
从整体上来说,因为color和clarity主要是钻石自然形成的指标所以表现出了一定的正态分布态势,而cut可以人为控制,表现出了集中在比较理想水平的情况。
我们使用的是ggplot2包绘制柱状图 ggplot2包是使用R进行数据可视化的重要工具。在调用ggplot2函数前需要下载并安装该包(install.packages(“ggplot2”)),第一次使用前还需要进行加载(library(ggplot2)
)
最后再调用Rmisc包中的multiplot()函数将这三幅图合并在一个绘图区域,col参数代表排版时一行放置几列,缺省时为1。所以合并之前请先下载和安装Rmisc包。(install.packages(“Rmisc”)),第一次使用前还需要进行加载(library(Rmisc)

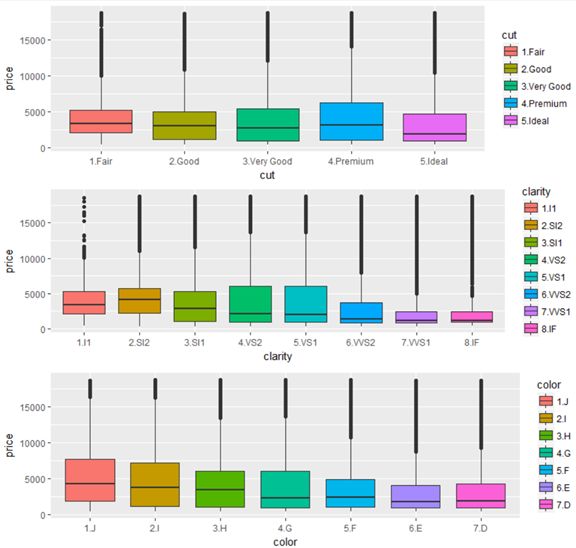
从图中可以看出来,每一个指标和价格的关系都相对比较复杂:
图中每个箱线图中的黑线为均值,其波动变化与各个指标相关性不明显。
color指标项更是表现出了颜色性状越好价格均值越低的反作用情况。
所以要进一步分析其他因素的作用,以解释这种异常。
制作carat和price的关系图,考虑到carat增长对price影响可能有边际贡献的变化,所以也制作一幅使用log(price)的图。这里用到的是plotly包。包括下面的3D气泡图也是使用这个包中的函数完成的,类似于Rmisc包,在调用时需要安装和调用。

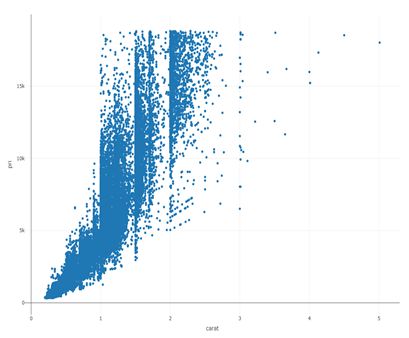
carat 与 price 关系散点图
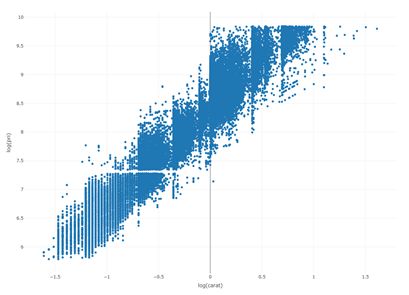
carat 与 log(price)关系图
在这里我们可以看出,carat和log(price)之间的关系呈现地比较明显的线性关系,然后有一定的区间波动。
所以在这里可以对前面color与price关系的异常现象做一个猜想解释:因为拥有color优良性状的钻石克拉数目都比较小,所以导致了整体的价格偏低,其他几个指标应该都有类似的情况。
为了证明这些情况也为了进一步挖掘信息,我们使用plotly包制作3D气泡图,plotly包的一个很大的优势在于可以制作可交互的图,包括旋转和放大缩小。
在作图之前先使用dplyr包中的group_by函数将数据按clarity,color,cut分组,计算每一组中的最大,最小,以及平均价格。
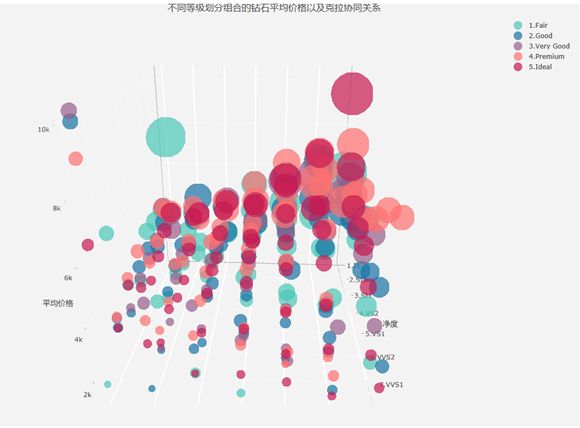
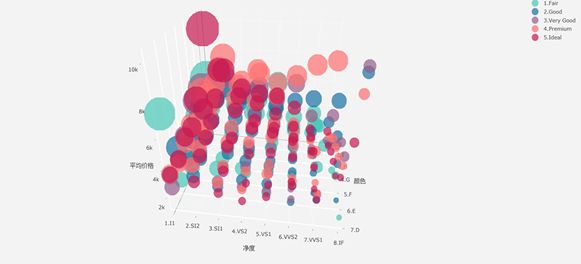
说明: 图中的z轴为各组的平均价格,x轴为不同color,y轴是不同净度,气泡大小代表了组内carat的大小(气泡越大组内平均的carat越大),而气泡的颜色代表了cut类别(原来使用颜色代表color,但是cut对price的影响没有color大,朱文斌老师建议我们小组使用color作为x轴,使图展示出来的趋势性更强)
可以看出随着color和clarity性状的提升,组内平均的carat下降得比较明显,整体的价格也在往下走,但是color和clarity最优质性状组合虽然克拉数目不高但是价格不低,所以也不能简单。
我们初步得到了如下的结论:
1、钻石克拉数对其价格影响是非常大的
2、其他各个性状对钻石价格影响不能忽视,对价格贡献方面,其他性状影响价格方式比较复杂
以上面的结论为指导我们就可以使用线性回归模型找出一些主要变量和变量的主要形式。
04
探索各变量和价格的关系
线性规划模型部分
在原有的将clarity、color、cut作为因子变量进行回归的思路上,我们根据朱文斌老师的建议,加入样本集中三者各自的比例,以及对不同级别赋不同的得分(级别越高得分越高)等新的变量。
在这里特别提一下一开始隐藏了1000条数据,是为了模拟实际情况,也就是实际中模型训练完毕后要使用非训练集和测试集数据进行测评,从一开始的数据生成中就把这一部分数据取出来,命名为da_hide , 留在最后得到最优模型时候检验模型效果。代码如下:

其中的变量也经过了和主要数据集一样的处理,这些在附带的代码中体现。选取了包括交互项、指数项、平方项在内的30多种变量组合的线性回归模型,使用performanceEstimation包中的performanceEstimation
,以hold out 方法以70%的数据作为训练集,30%的数据作为测试集,单个模型进行50次训练并计算对应的NMSE,进行模型训练和评价。
下图是我们最后选择的模型的代码例子:

将其中一部分模型的NMSE做成箱线图得到下面的结果:
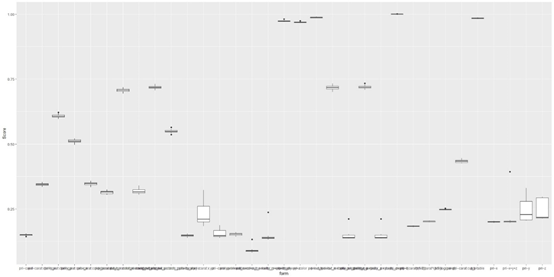
部分回归结果的NMSE
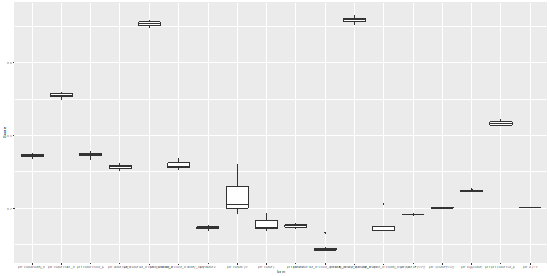
部分效果比较好的回归结果的NMSE
由于涉及的变量组合比较多,所以图就会比较紧凑,从中我们挑选出了一个性状最好的模型(本来应该挑选多个性状比较好的模型,当时时间不足只能选取一个性状最好的变量组合)
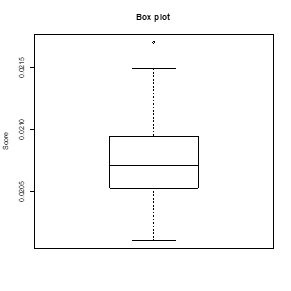
最优模型50次计算得到的NMSE得分箱线图
其变量组合为:
因变量:log(pri)
解释变量:log(carat),cut_n,color_n,clarity_n,x,y,z
线性关系的探索就到这一步为止,我们将在这个变量组合的基础上使用决策树和随机森林以及神经网络模型。
05
探索各变量和价格的关系
决策树模型部分
① 决策树简介
决策树:是一种基本的分类和回归方法。它是基于实例特征对实例进行分类的过程,我们可以认为决策树就是很多if-then的规则集合。
② 计算结果
数据按照holdout方法随机分出训练集和测试集,其中训练集占70%,测试集占30%。根据线性回归的结果选出最佳的回归模型Iog(carat) + cut_n+ color_n + clarity_n + x + y + z,基于此回归模型的基础上寻找最好的决策树模型。
使用
rpart、rpart.plot(使用方法参考:机器学习| 一个简单的入门实例-员工离职预测中有提到)得到下面的决策树图,因为节点比较多所以不能得到额外的分析指导。
不对cp决策树复杂度做限制,se从0到1每隔0.1取值一次,得到10个不同的决策树模型(se是模型中训练决策树确定形状时使用的参数,代表了综合评价不同减枝时,误差均值和误差方差的相对权重。),单个模型进行50次计算。
结果图如下:
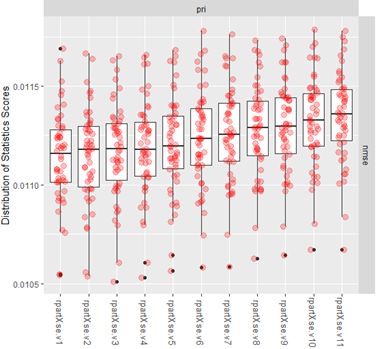
根据图形可知,在模型1与模型4的效果较好,se取值分别为0与0.3.具体模型结果如下表:
通过模型,我们发现实际上模型1至模型4效果均较好,即se取值偏小,不用过多考虑Xstd,而在决策树788个节点数据中我们也可以发现相对于Xerror,Xstd的变化并不太大(由于数据较多,此处未呈现788个点的具体结果)。
Xstd的主要变化在前15个节点由0.00888377减小至0.00100157,15个点之后至第788个点由0.00100157减小至0.00051807,变化极小,因此se呈现取值较小的情况。综合之,选择se取值为0的模型。不需要考虑xstd的影响。
06
探索各变量和价格的关系
随机森林模型部分
① 方法简介
随机森林是一种比较新的机器学习模型,是用随机的方式建立一个森林,森林里面有很多的决策树组成,当有一个新的输入样本进入的时候,让森林中的每一棵决策树参与计算判断,综合整体的计算判断结果,得出最后的评价。
② 计算结果
我们根据线性回归得出的最佳公式,选用不同的决策树棵数进行实验,选用棵数依次为50、100、400、800、1600,每种情况重复进行50次。通过比较不同情况下得到的误差结果,以期找到最合适的树木棵树。下图为选用棵数为400时的情况,其他四种情况只需修改相应数字即可。

根据实验结果分别计算树木棵数为50、100、400、800、1600五种情况下的标准均方差,然后将这些均方差合并在一起。下图表示的是棵数为400时计算标准均方差的情况。


标准均方差越小,则误差越小,实验更符合我们的要求。正常来讲,树木棵树越多,误差越小,但是树木棵树增多会显著增加计算时间。
因此,从合并的箱型图可以看出,在树木棵数超过400之后,标准均方差虽然还有下降,但下降的幅度很小,对实验误差的减小帮助不大。而在400之前,下降的幅度比较大。因此,我们可以得出,随机森林树木棵数选择400是最合适的。
用ggplot()函数,画出数目颗数为400的随机森林的箱型图,横坐标表示树木棵数,纵坐标表示NMSE的值。
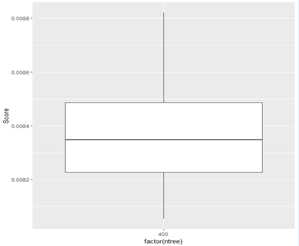
由图可知,此时标准均方差在0.0083至0.0084之间,优于决策树模型。
07
探索各变量和价格的关系
神经网络(ANN)部分
① 算法简介
它是一种模仿动物神经网络行为特征,进行分布式并行信息处理的算法数学模型。这种网络依靠系统复杂程度,通过调整内部大量节点之间相互连接的关系,从而达到处理信息的目的。
ANN 有能力学习和构建非线性的复杂关系的模型,这非常重要,因为在现实生活中,许多输入和输出之间的关系是非线性的、复杂的。ANN 可以推广,在从初始化输入及其关系学习之后,它也可以推断出从未知数据之间的未知关系,从而使得模型能够推广并且预测未知数据。与许多其他预测技术不同,ANN 不会对输入变量施加任何限制(例如:如何分布)。
② 计算过程
因为当时进行分析的时候没有找到合适的函数,所以我们自己定义了一个计算函数,workflowforANN,我们使用线性回归部分得出的最佳公式,即模型代入模型进行实验,并且使用holdout的部分计算,然后算出得到NSME的值。我们分别带入不同的参数,重复进行,然后将每次得到的结果保存并且记录下来,同时文本化模型的参数。

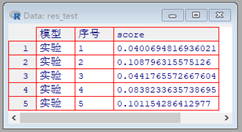
在这里代入不同的参数进行实验,只要改变size、decay、maxit的参数,然后重复运行即可,对不同参数情况下的结果进行比较,最后选出最优参数。上图是size=1000,decay=0.001,maxit=10000情况的实验结果,可以发现误差都比较大,因此该参数选择不予考虑。
pars = list(size =2000,decay = 0.01, maxit = 4000,linout = TRUE )
res_test 实验",pars,holdrate = 0.3)
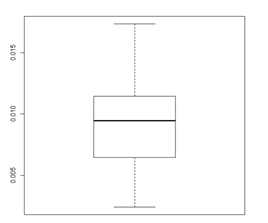
在这里代入参数为size = 2000,decay= 0.01, maxit =4000的情况,运行得到实验结果如上图所示。由图可知,标准均方差在0.010以下,理论上在这个参数下中间层神经元数目仍然太少,模型的性能还有比较大的提升空间(共有5万个左右的样本点),但是受限于计算设备,没有做进一步的深入。
08
结论
模型2(size = 2000,decay = 0.01, maxit = 4000)
通过上表我们可以看出,在我们的分析计算中,效果最好的模型是随机森林中的模型6这个公式,也就是取400棵时得出的结果更好,能更准确的评估出钻石的价格。
ps:再次强调受限于计算设备(也就是5000出头的小笔记本,他尽力了)所以神经网络不能在较好的参数下运行,所以表现比较一般。
作者简介:
陈郑逸帆华南理工技术经济及管理研二在读,目前师从工商管理学院许治老师,主要的研究兴趣和方向是创新生态理论,以及机器学习和大数据在创新管理中的应用。
文章简介:
这篇文章的研究内容是来自于我《大数据分析与数据挖掘》的课程设计,我主要负责数据的清洗和处理,数据可视化,建模和程序修改,课程设计的报告由我们小组成员共同完成,然后由我来将报告的主题内容精炼成这篇推文。我们小组还有三位同学,分别是华南理工大学工商管理学院尹潇(技术经济及管理),主要负责主要负责决策树建模过程;陈如洁(技术经济及管理)主要负责随机森林模型部分的实验调试;邱榕新(技术经济及管理)主要负责线性回归模型部分的实验调试和模型修正,以及后期课程报告的梳理。
感谢您,
支持学生们的原创热情!
郑重承诺
打赏是对工作的认可
所有打赏所得
都将作为酬劳支付给辛勤工作的学生
指导老师不取一文
- The END -
文案 / 陈郑逸帆(研二)
排版 / 周馨匀(研二)
代码 / 陈郑逸帆、尹潇、邱榕新、陈如洁(研二)
指导老师 / 朱文斌教授
如对文中内容有疑问,欢迎交流。PS:部分资料来自网络。
朱文斌(华南理工大学工商管理学院教授、i@zhuwb.com)
陈郑逸帆(华南理工大学管理学院研究生二年级、czyf_kaqixuong@163.com)
尹潇(华南理工大学经管理院研究生二年级、648293811@qq.com)
邱榕新 (华南理工大学经济学院研究生二年级、1945986579@qq.com)
陈如洁 (华南理工大学经济学院研究生二年级、447584228@qq.com)









