论智 授权
禁止二次转载
编者按:入门深度学习的方法有很多,其中最便捷的是在线课程。但是,从做出这项选择起,新手要面临的就不仅是全新的知识体系,还有无数的陌生术语。在开始阅读前,请自问自答:什么是Adam、ReLU、YOLO?什么是AdaGrad、Dropout、Xavier Initialization?如果发现这很困难,请跟随Jan Zawadzki的脚步,有条理地去回顾自己的记忆碎片。

本文旨在解释深度学习的一些常用术语,尤其是吴恩达在deeplearning.ai的Coursera课程中会频繁提到的重要词汇。每个词条包含意义阐释、图片和相关链接(公众号读者请点击原文查看),希望能对深度学习初学者和从业者有所帮助。
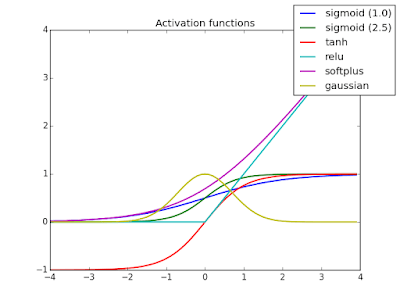
Activation Function(激活函数)
激活函数的作用是对输入执行非线性变换,将输入乘以权重并添加到偏置项中。目前最常用的激活函数有ReLU、tanh和sigmoid。
Adam Optimization (Adam优化)
Adam优化可以代替随机梯度下降,用来迭代调整网络权重。根据论文Adam: A Method for Stochastic Optimization的说法,Adam在计算上是高效的,适用于大数据集,并且几乎不需要超参数调整。它也没有预定义的、固定的学习率,而是采用自适应学习率。在实际应用中,Adam现在是深度学习模型中的一种默认优化算法。
Adaptive Gradient Algorithm (自适应梯度算法)
AdaGrad是一种梯度下降优化算法,它根据参数在训练期间的更新频率进行自适应调整,更新幅度小、频率快。它在非常稀疏的数据集上表现良好,如用于在自然语言处理任务中调整词嵌入。相关论文:Adaptive Subgradient Methods for Online Learning and Stochastic Optimization。
Average Pooling(平均池化)
平均池化指的是对卷积操作的结果计算平均值,并把这个值作为图像区域池化后的值。它通常用于缩小输入的大小,主要出现在比较老的卷积神经网络体系结构中,在现在流行的CNN里,更常见的是maximum pooling(最大池化)。

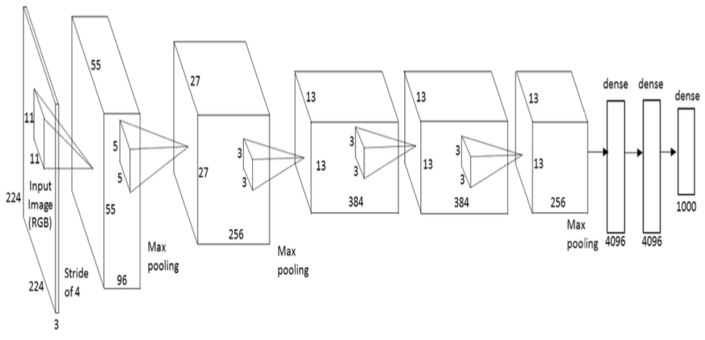
AlexNet
AlexNet是一个流行的CNN架构,有八层,它比LeNet更广泛,因此训练用时也更长。2012年,AlexNet赢得了ImageNet图像分类挑战。相关论文:ImageNet Classification with Deep Convolutional Neural Networks。
Backpropagation(反向传播)
反向传播是一种用于调整网络权重以最小化神经网络损失函数的常用方法,它在神经网络中从后向前计算,通过对每个激活函数进行梯度下降重新调整权重。
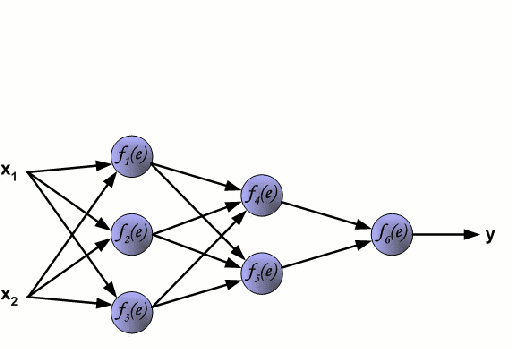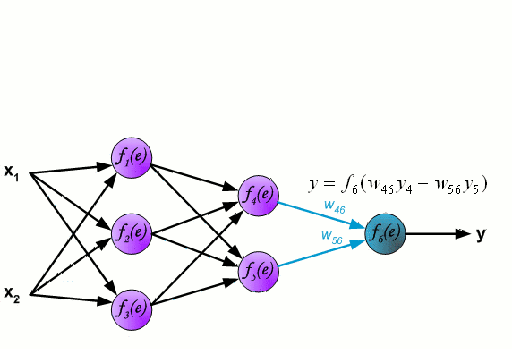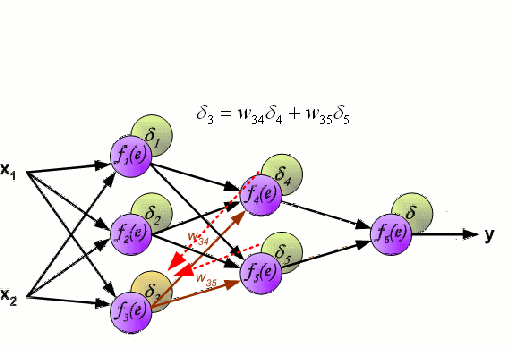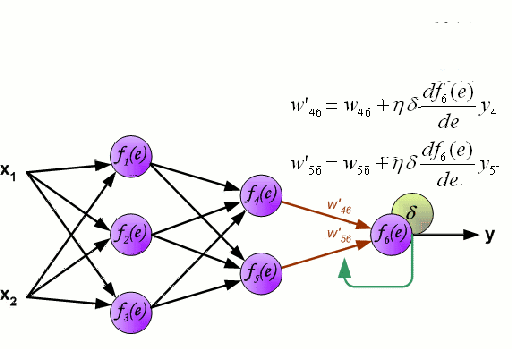
Batch Gradient Descent(BGD)
BGD是一种常规的梯度下降优化算法,它更新的是整个训练集的参数。在更新参数前,它必须计算整个训练集的梯度,因此如果数据集很大,BGD可能会很慢。
Batch Normalization
Batch Normalization指的是把神经网络层中的值归一化为0到1之间的值,方便更快训练神经网络。
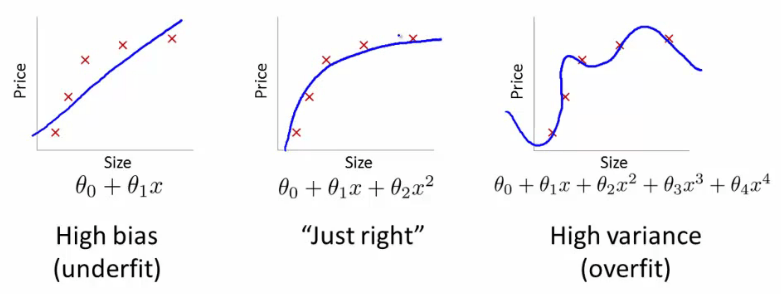
Bias (偏差)
当模型在训练集上精度欠佳时,它被称为欠拟合。当模型具有高偏差时,它通常不会在测试集上又高准确率。
Classification (分类)
分类指目标变量属于不同的类,它们不是连续变量。常见的分类任务有图像分类、欺诈检测、自然语言处理的某些问题等。
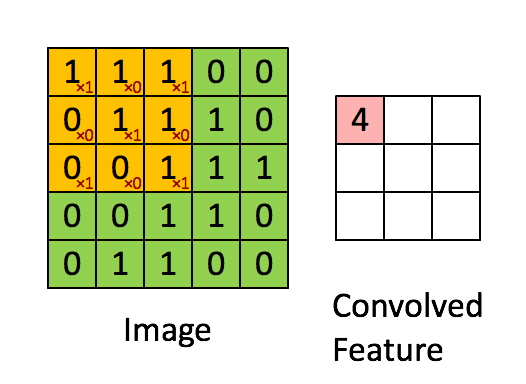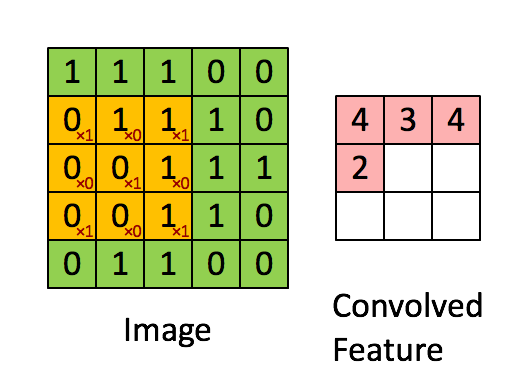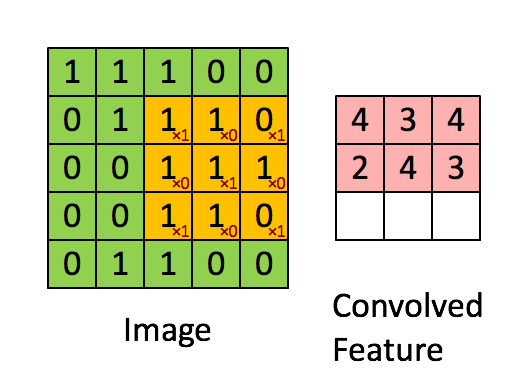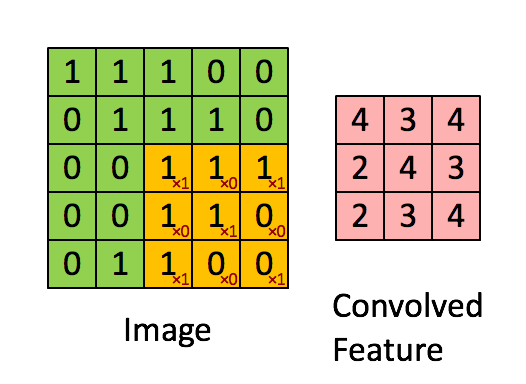
Convolution (卷积)
卷积指的是将输入与filter相乘的操作。它是卷积神经网络的基础,在识别图像中的边缘和物体方面表现出色。
Cost Function (损失函数)
损失函数又称loss function,指的是模型的输出与实际情况之间的差异,这是深度神经网络学习的关键要素之一,因为它们构成了参数更新的基础。通过将前向传播的结果与真实结果相比较,神经网络能相应地调整网络权重以最小化损失函数,从而提高准确率。常用的损失函数有均方根误差。
Deep Neural Network(深度神经网络)
深度神经网络是具有许多隐藏层(通常超过5层)的神经网络,但具体以多少层为界,学界还没有定义。这是机器学习算法的一种强大形式,它在自动驾驶、发现行星等任务中已有应用。
Derivative (导数)
数是特定点处函数的斜率。计算导数的作用是用梯度下降算法将权重参数调整到局部最小值。
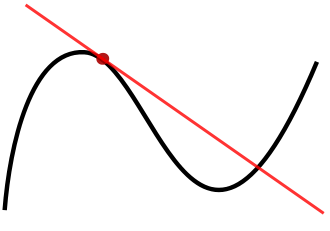
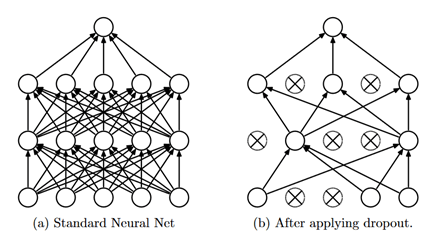
Dropout
Dropout是一种在深度神经网络中随机消除节点及其连接的正则化技术。它可以防止模型过拟合,同时加快深度神经网络的训练速度。每次更新参数时,Dropout会在训练期间丢弃不同的节点,这就迫使相邻节点之间避免过多依赖,并始终保持自身的正确表示。它已经在一些分类任务上明显改善了模型精度,相关论文:Dropout: A Simple Way to Prevent Neural Networks from Overfitting。
End-to-End Learning (端到端学习)
端到端学习指的是算法能够自行解决整个任务,不需要额外的人为干预(如模型切换或新数据标记)。案例:NVIDIA前年发表了一篇论文End to End Learning for Self-Driving Cars,他们训练了一个只需根据单个前置摄像头的原始图像就能让自动驾驶汽车自行转向的CNN。
Epoch
一个Epoch表示训练集中的每个样本都已经进行过一次完整的前向传播和反向传播。单个Epoch涉及每个训练样本的迭代。
Forward Propagation (前向传播)
前向传播就是数据被输入神经网络后,经过隐藏层、激活函数,最后形成输出的过程。当节点权重经过训练后,前向传播能预测输入样本的结果。
Fully-Connected layer (全连接层)
全连接层指的是和上一层的节点完全连接的神经网络层,它把上一层的输出作为输入,并用其权重转换输入,将结果传递给下一层。
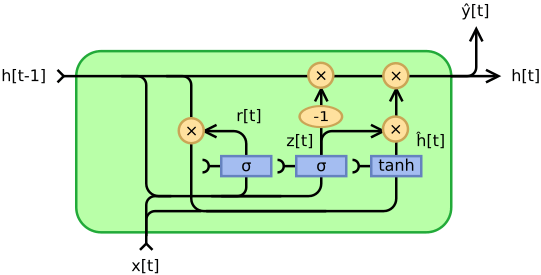
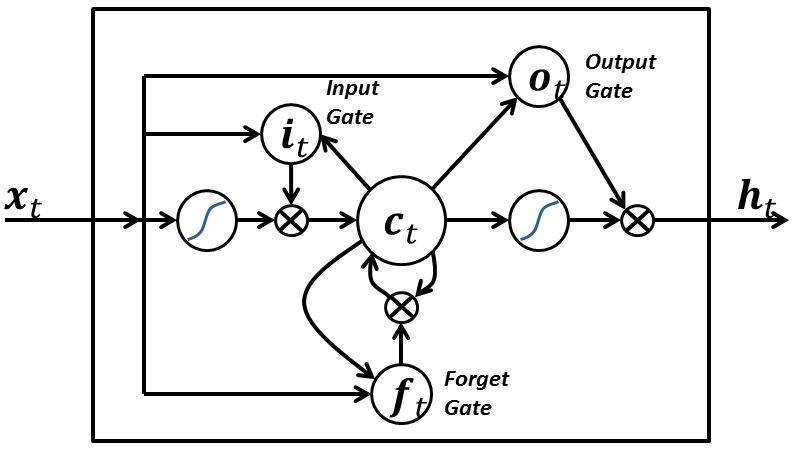
Gated Recurrent Unit(GRU)
GRU是RNN的一种,主要用于自然语言处理任务,作用是对给定输入进行多次变换。和LSTM一样,GRU可以避免RNN中的梯度消失问题,不同的是它只有两个门(没有遗忘门),因此在实现类似性能时计算效率更高。相关论文:Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation。
Human-Level Performance
Human-Level Performance从字面上理解就是人类级别的表现,它表示一组人类专家的最佳表现。作为神经网络性能的一种常用衡量标准,人类表现在改进神经网络的过程中一直发挥着作用。
Hyperparameters (超参数)
超参数决定的神经网络的性能,常见的超参数有学习率、梯度下降迭代次数、隐藏层的数量和激活函数。不要将DNN自学的参数、权重和超参数混淆。
ImageNet
ImageNet是一个包含上千个图像及其注释的数据集,它是非常有用的图像分类任务资源。

Iteration (迭代)
迭代指的是神经网络前向传播和反向传播的总次数。例如,假设你的训练集有5个batch,一共训练了2个epoch,那么你就一共进行了10次迭代。
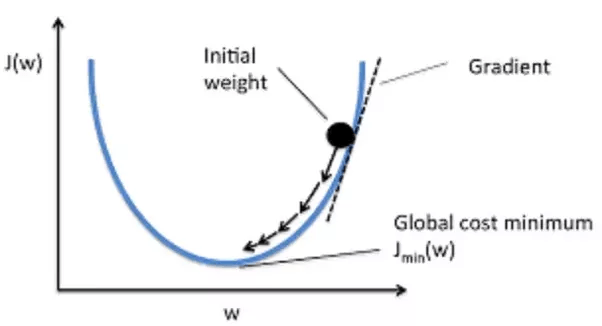
Gradient Descent (梯度下降)
梯度下降是一种帮助神经网络决定如何调整参数以最小化损失函数的方法。我们可以用它重复调整参数,直到找到全局最小值。CSDN上翻译了Sebastian Ruder的《梯度下降优化算法综述》,非常值得阅读。
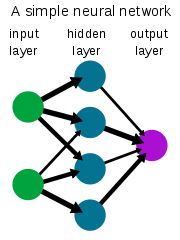
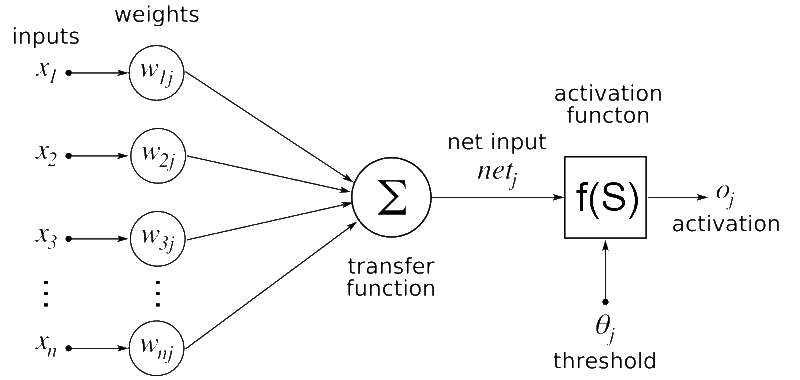
Layer
Layer指的是一组转换输入的激活函数。如下图所示,神经网络通常会使用多个隐藏层来创建输出,常见的有输入层、隐藏层和输出层。
Learning Rate Decay(学习率衰减)
学习率衰减指的是在训练期间改变神经网络的学习率,它反映了学习的灵活性。在深度学习实践中,随着训练进行,学习率一般是逐渐衰减的。
Maximum Pooling(最大池化)
最大池化表示只选择特定输入区域的最大值,它通常用于CNN。以减小输入的大小。
Long Short-Term Memory(LSTM)
LSTM是一种特殊的RNN,能够学习输入的上下文。当相应的输入远离彼此时,常规RNN会存在梯度消失问题,而LSTM可以学习这些长期依赖性。相关论文:LONG SHORT-TERM MEMORY。
Mini-Batch Gradient Descent
Mini-Batch Gradient Descent是一种优化算法,它先把训练数据分成一系列子集,再在上面进行梯度下降。由于这个过程是可以并行的,各个worker可以同时分别迭代不同的mini batch,因此它计算效率更高、收敛更稳健,是batch和SGD的一种有效组合。
Momentum(动量)
Momentum也是一种梯度下降优化算法,用于平滑随机梯度下降法的振荡。它先计算先前采取的步骤的方向的平均方向,并在此方向上调整参数更新。这一术语来自经典物理学中的动量概念,当我们沿着一座小山坡向下扔球时,球在沿着山坡向下滚动的过程中收集动量,速度不断增加。参数更新也是如此。
Neural Network(神经网络)
神经网络是一种转换输入的机器学习模型,最基础的NN具有输入层、隐藏层和输出层,随着技术的不断发展,它现在已经成为查找数据中复杂模式的首选工具。
Non-Max Suppression(非极大抑制)
非极大抑制是物体检测领域的一种常用算法,它也是YOLO的一部分。它能消除多余的框,找到最佳的物体检测的位置。相关论文:Learning non-maximum suppression。

Recurrent Neural Networks (RNN)
RNN允许神经网络“理解”语音、文本和音乐的上下文。它通过让信息循环通过网络,从而在较早和较晚的层之间保持输入的重要特征。
ReLU
ReLU是一个简单的线性变换单元,如果输入小于零,则输出为零,否则输出等于输入。它通常是现在首选的激活函数,可以帮助更快地训练。
Regression(回归)
和分类相对应,回归也是统计学习的一种形式,只不过它的输出是连续的变量,而不是分类值。分类为输入变量分配了一个类,但回归为输入变量分配的是无限多个可能的值,而且它通常是一个数字。常见的回归任务有房价预测和客户年龄预测。
Root Mean Squared Propagation(RMSProp)
RMSProp随机梯度下降优化方法的扩展,它以每个参数的学习率为特征,根据参数在先前迭代中的变化速度来调整学习率。
Parameters (参数)
参数即在应用激活函数之前转换输入的DNN的权重。神经网络的每一层都有自己的一组参数。利用反向传播算法,我们可以通过调整参数最小化损失函数。
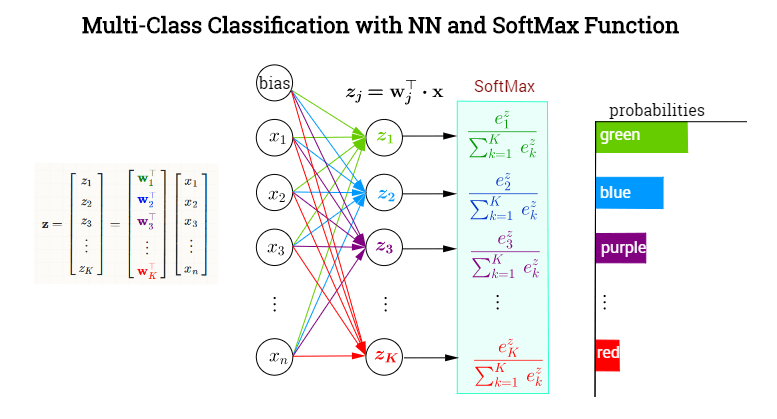
Softmax
Softmax函数,或称归一化指数函数,是逻辑函数的一种推广,常用于DNN的最后一层。它的本质就是将一个K维的任意实数向量压缩(映射)成另一个K维的实数向量,其中向量中的每个元素取值都介于(0,1)之间。它非常适合有两个以上输出的分类任务。
Stochastic Gradient Descent (随机梯度下降)
随机梯度下降法是梯度下降法在机器学习领域的一个变种,它通过抽样的梯度来近似表示真实的梯度,从而避免大量的计算。
Supervised Learning(监督学习)
监督学习是机器学习的一种形式,其中每个输入样本都包含经注释的标签。这些标签的作用是将DNN的输出和真实结果做对比,并最小化损失函数。
Transfer Learning (迁移学习)
迁移学习是一种将一个神经网络的参数用于不同任务而无需重新训练整个网络的技术。它的具体方法是使用先前训练过的网络中的权重并删除输出层,然后用你自己的softmax或logistic图层替换最后一层,再次训练网络。之所以有效,是因为较低的层通常会检测到类似的边缘,这些边缘对其他图像分类任务也是有效的。
Unsupervised Learning(无监督学习)
无监督学习也是机器学习的一种形式,但是它的输出类是未知的。常见的无监督学习方法有GAN和VAE。
Validation Set(验证集)
验证集通常被用于寻找深度神经网络的最佳超参数。训练好DNN后,我们可以在验证集上测试不同的超参数组合,然后选择性能最好的组合在测试集上做最终预测。在使用过程中,注意平衡各集的数据占比,比如在有大量数据可用的情况下,训练集的数据占比应该高达99%,而验证集合测试集应该各占0.5%。
Vanishing Gradients(梯度消失)
梯度消失是神经网络到达一定深度后会出现的问题。在反向传播中,权重根据其梯度或衍生物进行调整,但在深度神经网络中,较早层的梯度可能会变得非常小,以至于权重根本不会更新。避免这个问题的一种做法是使用ReLU激活函数。
Variance(方差)
当DNN过拟合训练数据时,我们称这之中存在方差。DNN无法将噪声与模式区分开来,并对训练数据中的每个方差进行建模,具有高方差的模型通常无法准确推广到新数据。
VGG-16
VGG-16是一种CNN流行网络架构,它简化了AlexNet,总共有16层。一些研究已经证实,许多经预训练的VGG模型可以通过迁移学习被用于其他新任务。
Xavier Initialization (Xavier初始化)
Xavier初始化是我们在自编码器中会使用到一种参数初始化方法,它在第一个隐藏层中分配起始权重,以便输入信号深入神经网络。之后,它再根据节点和输出的数量来衡量权重,从而防止信号在网络中变得太小或太大。
YOLO
YOLO是是目前比较流行的对象检测算法,它把物体检测问题处理成回归问题,用一个卷积神经网络结构就可以从输入图像直接预测bounding box和类别概率。相关论文:YOLO9000: Better, Faster, Stronger。
希望本文能帮助你更深入地理解深度学习世界中使用的术语,在学习Coursera课程时,有需要的读者不妨把这篇文章放在一旁,更专业、更高效地掌握老师教授的内容。
原文地址:towardsdatascience.com/the-deep-learning-ai-dictionary-ade421df39e4
推荐阅读:
一大批历史精彩文章啦
EMNLP 2018 | 为什么使用自注意力机制?
xgboost的原理没你想像的那么难
免费公开课 | 送你两个知名AI企业深度学习岗位面试机会









