0X00 前言
最近使用iPhone x,把人脸识别代入了我们的生活中。前段时间了解了一个Python的一个开元函数库,并对其进行了分析、学习和实践,那么今天我们就来讲解一下如何使用face_recognition这个库来实现简单的人脸识别。
注:以下文章的所有操作都是Windows下实现的。
0×01 正文
人脸识别主要步骤:
face_recognition 库的安装
安装此库,首先需要安装编译dlib,此处我们偷个懒,安装软件Anaconda(大牛绕过),此软件预装了dlib.
安装好后,我们直接通过pip 安装face_recognition库,命令如下
python -m pip install face_recognition
调用一下库,检查是否成功导入

没报错,就是安装成功了。
按照以上办法在安装numpy 和python-opencv 两个库就可以了
通过face_recognition库实现人脸识别
代码如下
# -*- coding: UTF-8 -*-
import face_recognition
import cv2
import os
# 这是一个超级简单(但很慢)的例子,在你的网络摄像头上实时运行人脸识别
# PLEASE NOTE: This example requires OpenCV (the `cv2` library) to be installed only to read from your webcam.
# 请注意:这个例子需要安装OpenCV
# 具体的演示。如果你安装它有困难,试试其他不需要它的演示。
# 得到一个参考的摄像头# 0(默认)
video_capture = cv2.VideoCapture(0)
# 加载示例图片并学习如何识别它。
path ="images"#在同级目录下的images文件中放需要被识别出的人物图
total_image=[]
total_image_name=[]
total_face_encoding=[]
for fn in os.listdir(path): #fn 表示的是文件名
total_face_encoding.append(face_recognition.face_encodings(face_recognition.load_image_file(path+"/"+fn))[0])
fn=fn[:(len(fn)-4)]#截取图片名(这里应该把images文件中的图片名命名为为人物名)
total_image_name.append(fn)#图片名字列表
while True:
# 抓取一帧视频
ret, frame = video_capture.read()
# 发现在视频帧所有的脸和face_enqcodings
face_locations = face_recognition.face_locations(frame)
face_encodings = face_recognition.face_encodings(frame, face_locations)
# 在这个视频帧中循环遍历每个人脸
for (top, right, bottom, left), face_encoding in zip(face_locations, face_encodings):
# 看看面部是否与已知人脸相匹配。
for i,v in enumerate(total_face_encoding):
match = face_recognition.compare_faces([v], face_encoding,tolerance=0.5)
name = "Unknown"
if match[0]:
name = total_image_name[i]
break
# 画出一个框,框住脸
cv2.rectangle(frame, (left, top), (right, bottom), (0, 0, 255), 2)
# 画出一个带名字的标签,放在框下
cv2.rectangle(frame, (left, bottom - 35), (right, bottom), (0, 0, 255), cv2.FILLED)
font = cv2.FONT_HERSHEY_DUPLEX
cv2.putText(frame, name, (left + 6, bottom - 6), font, 1.0, (255, 255, 255), 1)
# 显示结果图像
cv2.imshow('Video', frame)
# 按q退出
if cv2.waitKey(1) & 0xFF == ord('q'):
break
# 释放摄像头中的流
video_capture.release()
cv2.destroyAllWindows()
其次还要准备一个images文件夹进行摄像头的人脸比对

成功的效果图我就不贴了。
加薇信:mmp9972 即可获取数十套PDF哦!
原理如下:
1.遍历images文件中的图片
2.提取特征脸
3.摄像头每帧提取图片,提取特诊脸
4.遍历特征列表,找出符合特征脸
5.输出名字
1、从特征中找出图片中的人脸
import face_recognition
image = face_recognition.load_image_file("your_file.jpg")
face_locations = face_recognition.face_locations(image)
2、找到并且控制图像中的脸部特征
import face_recognition
image = face_recognition.load_image_file("your_file.jpg")
face_landmarks_list = face_recognition.face_landmarks(image)
3、识别照片中的人脸
import face_recognition
known_image = face_recognition.load_image_file("biden.jpg")
unknown_image = face_recognition.load_image_file("unknown.jpg")
biden_encoding = face_recognition.face_encodings(known_image)
[0]unknown_encoding = face_recognition.face_encodings(unknown_image)
[0]results = face_recognition.compare_faces([biden_encoding], unknown_encoding)
0×02 总结
总的来说,该开源库使得人脸识别的普及实现不再那么的遥远。调用该库,只需几行代码,便可实现人脸识别。有什么问题可以在下面评论讨论哦,各路大牛勿喷。
Python+树莓派+YOLO打造一款人工智能相机
2018年1月2日 BY ALPHA_H4CK·PYTHON+树莓派+YOLO打造一款人工智能相机
已关闭评论
不久之前,亚马逊刚刚推出了DeepLens。这是一款专门面向开发人员的全球首个支持深度学习的摄像机,它所使用的机器学习算法不仅可以检测物体活动和面部表情,而且还可以检测类似弹吉他等复杂的活动。虽然DeepLens还未正式上市,但智能摄像机的概念已经诞生了。

今天,我们将自己动手打造出一款基于深度学习的照相机,当小鸟出现在摄像头画面中时,它将能检测到小鸟并自动进行拍照。最终成品所拍摄的画面如下所示:

相机不傻,它可以很机智
我们不打算将一个深度学习模块整合到相机中,相反,我们准备将树莓派“挂钩”到摄像头上,然后通过WiFi来发送照片。本着“一切从简”(穷)为核心出发,我们今天只打算搞一个跟DeepLens类似的概念原型,感兴趣的同学可以自己动手尝试一下。
接下来,我们将使用Python编写一个Web服务器,树莓派将使用这个Web服务器来向计算机发送照片,或进行行为推断和图像检测。
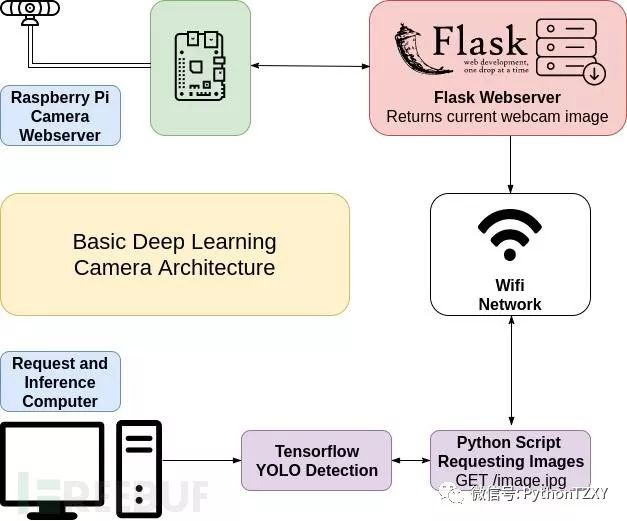
我们这里所使用的计算机其处理能力会更强,它会使用一种名叫YOLO的神经网络架构来检测输入的图像画面,并判断小鸟是否出现在了摄像头画面内。
我们得先从YOLO架构开始,因为它是目前速度最快的检测模型之一。该模型专门给Tensorflow(谷歌基于DistBelief进行研发的第二代人工智能学习系统)留了一个接口,所以我们可以轻松地在不同的平台上安装和运行这个模型。友情提示,如果你使用的是我们本文所使用的迷你模型,你还可以用CPU来进行检测,而不只是依赖于价格昂贵的GPU。
接下来回到我们的概念原型上… 如果像框内检测到了小鸟,那我们就保存图片并进行下一步分析。
检测与拍照

正如我们所说的,DeepLens的拍照功能是整合在计算机里的,所以它可以直接使用板载计算能力来进行基准检测,并确定图像是否符合我们的标准。
但是像树莓派这样的东西,我们其实并不需要使用它的计算能力来进行实时计算。因此,我们准备使用另一台计算机来推断出现在图像中的内容。
我使用的是一台简单的Linux计算机,它带有一个摄像头以及WiFi无线网卡(树莓派3+摄像头),而这个简单的设备将作为我的深度学习机器并进行图像推断。对我来说,这是目前最理想的解决方案了,这不仅大大缩减了我的成本,而且还可以让我在台式机上完成所有的计算。
当然了,如果你不想使用树莓派视频照相机的话,你也可以选择在树莓派上安装OpenCV 3来作为方案B,具体的安装方法请参考【这份文档】。友情提示,安装过程可谓是非常的麻烦!
接下来,我们需要使用Flask来搭建Web服务器,这样我们就可以从摄像头那里获取图像了。这里我使用了MiguelGrinberg所开发的网络摄像头服务器代码(Flask视频流框架),并创建了一个简单的jpg终端:
#!/usr/bin/envpython
from import lib import import_module
import os
from flask import Flask, render_template, Response
#uncomment below to use Raspberry Pi camera instead
#from camera_pi import Camera
#comment this out if you're not using USB webcam
from camera_opencv import Camera
app =Flask(__name__)
@app.route('/')
def index():
return "hello world!"
def gen2(camera):
"""Returns a single imageframe"""
frame = camera.get_frame()
yield frame
@app.route('/image.jpg')
def image():
"""Returns a single currentimage for the webcam"""
return Response(gen2(Camera()),mimetype='image/jpeg')
if __name__ == '__main__':
app.run(host='0.0.0.0', threaded=True)
如果你使用的是树莓派视频照相机,请确保没有注释掉上述代码中from camera_pi那一行,然后注释掉from camera_opencv那一行。
你可以直接使用命令python3 app.py或gunicorn来运行服务器,这跟Miguel在文档中写的方法是一样的。如果我们使用了多台计算机来进行图像推断的话,我们还可以利用Miguel所开发的摄像头管理方案来管理摄像头以及计算线程。
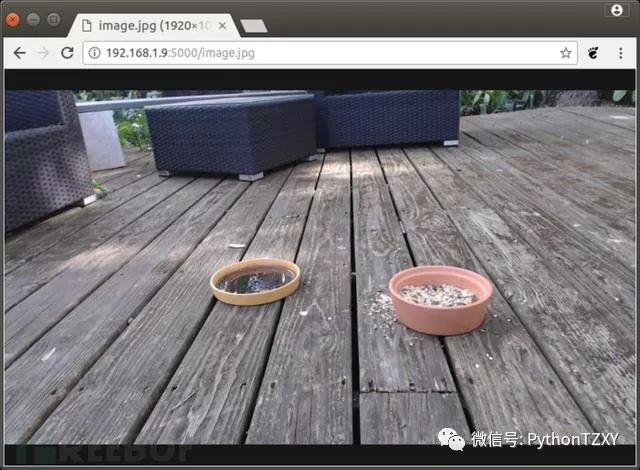
当我们启动了树莓派之后,首先需要根据IP地址来判断服务器是否正常工作,然后尝试通过Web浏览器来访问服务器。
URL地址格式类似如下:
http://192.168.1.4:5000/image.jpg
在树莓派中加载Web页面及图像来确定服务器是否正常工作:
图像导入及推断
既然我们已经设置好了终端来加载摄像头当前的图像内容,我们就可以构建一个脚本来捕捉图像并推断图像中的内容了。
这里我们需要用到request库(一个优秀的Python库,用于从URL地址获取文件资源)以及Darkflow(YOLO模型基于Tensorflow的实现)。
不幸的是,我们没办法使用pip之类的方法来安装Darkflow,所以我们需要克隆整个代码库,然后自己动手完成项目的构建和安装。安装好Darkflow项目之后,我们还需要下载一个YOLO模型。
因为我使用的是速度比较慢的计算机和板载CPU(而不是速度较快的GPU),所以我选择使用YOLO v2迷你网络。当然了,它的功能肯定没有完整的YOLO v2模型的推断准确性高啦!
配置完成之后,我们还需要在计算机中安装Pillow、numpy和OpenCV。最后,我们就可以彻底完成我们的代码,并进行图像检测了。
最终的代码如下所示:
from darkflow.net.build import TFNet
import cv2
from io import BytesIO
import time
import requests
from PIL import Image
import numpy as np
options= {"model": "cfg/tiny-yolo-voc.cfg", "load":"bin/tiny-yolo-voc.weights", "threshold": 0.1}
tfnet= TFNet(options)
birdsSeen= 0
def handleBird():
pass
whileTrue:
r =requests.get('http://192.168.1.11:5000/image.jpg') # a bird yo
curr_img = Image.open(BytesIO(r.content))
curr_img_cv2 =cv2.cvtColor(np.array(curr_img), cv2.COLOR_RGB2BGR)
result = tfnet.return_predict(curr_img_cv2)
print(result)
for detection in result:
if detection['label'] == 'bird':
print("bird detected")
birdsSeen += 1
curr_img.save('birds/%i.jpg' %birdsSeen)
print('running again')
time.sleep(4)
此时,我们不仅可以在命令控制台中查看到树莓派所检测到的内容,而且我们还可以直接在硬盘中查看保存下来的小鸟照片。接下来,我们就可以使用YOLO来标记图片中的小鸟了。
假阳性跟假阴性之间的平衡
我们在代码的options字典中设置了一个threshold键,这个阈值代表的是我们用于检测图像的某种成功率。在测试过程中,我们将其设为了0.1,但是如此低的阈值会给我们带来是更高的假阳性以及误报率。更糟的是,我们所使用的迷你YOLO模型准确率跟完整的YOLO模型相比,差得太多了,但这也是需要考虑的一个平衡因素。
降低阈值意味着我们可以得到更多的模型输出(照片),在我的测试环境中,我阈值设置的比较低,因为我想得到更多的小鸟照片,不过大家可以根据自己的需要来调整阈值参数。









