
作者:量化小白H Python爱好者社区专栏作者
个人公众号:量化小白上分记
前文传送门:
【Python金融量化】VaR系列(一):HS,WHS,RM方法估计VaR
【Python金融量化】VaR系列(二):CF,Garch,EVT方法估计VaR
【Python金融量化】VaR系列(三):DCC模型估计组合VaR
【Python金融量化】VaR系列(四):蒙特卡洛方法估计VaR
之前总结的大部分模型都是基于正态性的假设,但实际上,正态性假设并不非常符合金融时间序列的特征。如果从其他分布假设出发,对于单个资产来说,已经有t-garch等模型可以用于波动率建模,相对容易,但对于资产组合来说,多元正态具有边际分布及线性组合也符合多元正态分布的良好性质,但多元t分布,多元渐进t分布等就不具有这么好的性质,因此需要一些新的模型来解决这一问题,本文总结一种可以用于资产组合分布建模的方法:Copula模型,通过Copula模型描述出组合的分布后,就可以利用之前蒙特卡洛的方法估计组合VaR。
1. 资产组合VaR建模方法回顾
文章中总结了通过DCC模型估计组合向前一日VaR的方法,整体思路如下:
通过Garch族模型估计各资产的波动率
通过DCC模型估计各资产间的相关系数,结合1得到资产组合的协方差矩阵
在各资产正态性假设的前提下,可以知道资产组合也服从正态分布,并且均值与协方差阵已在1,2中计算得到
在已知组合中各但资产权重w的情况下,根据下式计算组合VaR
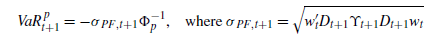
文章中总结了通过蒙特卡洛方法估计组合向前K日VaR的方法,也可以仅计算组合向前一日VaR(本文只考虑向前1日的情况),文章中也对比了蒙特卡洛方法与DCC方法得到的结果,差异并不大。蒙特卡洛方法的思路如下:
根据Garch族模型估计资产的波动率
根据DCC模型估计组合的相关系数
在1,2的基础上,在正态性假设前提下,得到组合的分布函数,对组合收益率进行模拟,在给定各资产权重w的情况下,可以得到组合的总收益
重复1-3若干次,可以得到组合总收益的模拟序列,类似HS方法,取p分位数即可
可以看出不论是DCC模型还是蒙特卡洛方法,都是在正态性假设的前提下,得到组合的分布函数再进行求解。事实上,也可以类比多元正态的概念构建多元t分布和多元渐进t分布,假设组合服从这样的分布,求出分布的参数后,再用蒙特卡洛方法进行模拟,这些理论依据已经很成熟,推导过程见文献[1],这里不再赘述。
但需要说明的是,多元t分布和多元渐近t分布都没有边际分布和线性组合依然多元t或者多元渐近t的性质。回忆多元正态的情况下,为了生成多元正态随机数,实际上是先产生不相关的n组一元正态随机数向量,然后通过cholesky分解转换为符合给定相关系数矩阵的组合收益率模拟序列。如果组合的分布不具有类似多元正态的性质,要根据分布函数模拟组合收益就比较困难,必须直接通过多元分布函数产生随机数,不能分解成单个资产去做,虽然也有相关的方法可以生成给定分布函数下随机数,但都比较麻烦,这是之前方法的一个局限性。
此外,多元正态假设所有的单个资产都是正态分布,多元t分布和多元渐近t分布的边际分布并非t分布或者渐近t分布,而不同的资产可能服从不同的分布,需要用不同方法去建模,已有的多元分布都不能满足这一条件,这是之前方法的另一局限性。
比较理想的状态是,我们可以用不同的方法对不同的单资产进行建模,最终n各资产具有不同的分布函数
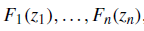
这种情况下,如果可以找到一个连接函数G,通过这n个边际分布得到组合的分布F,就可以解决上面所说的两种局限。
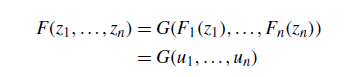
这也正是本文总结的Copula模型的逻辑。
2.Copula模型
Sklar定理
Copula模型整体来说比较复杂,这里只对关键的部分加以说明,模型中最重要的定理是Sklar定理,也就是上面所说的理想情况,具体叙述如下

G称为copula CDF,在sklar定义的假设下,如果我们已经通过一些单变量模型得到了单资产的分布函数,只需要确定出copula函数G,就相当于知道了组合的分布函数,从而把估计组合分布函数的问题转化为估计copula函数的问题。当然copula函数也不是靠猜,有一些常用的copula函数可以选择,在确定了copula函数之后,可以通过MLE等方法估计参数。
参数估计(MLE)
对sklar定理两边求导得到密度函数之间的关系
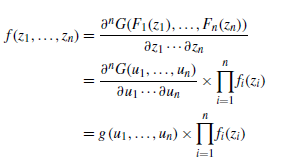
从而
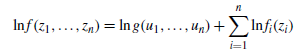
对数似然函数为
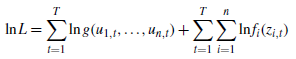
通过最大化对数似然函数L得到参数的估计量,这当中f都是已知的,g通过G进行计算。copula函数大致可以分为三类,以二元情况为例:
多元正态copula函数
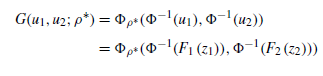
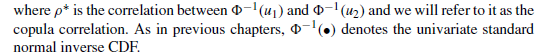
模型中唯一需要估计的参数为rho-star,g为对G求导的结果
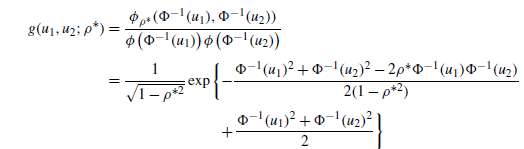
此时对数似然函数可以表示为

可以留意下这个式子,实证部分用到这个
多元t-copula函数
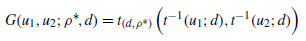
有rou-star和d两个待估参数
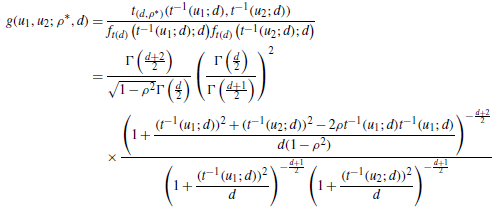
阿基米德copula函数
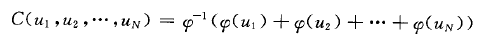
这里的C就是上文的G,见参考文献[2],二元情况下,可以细分为
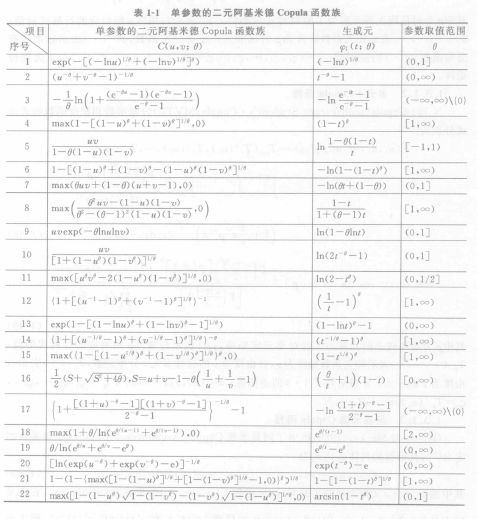
其中,序号1称为Gumbel Copula函数,序号2称为Clayton Copula函数,序号3称为Frank Copula函数,之所以说明这三个,是因为这三个实际应用中比较多,python的copulalib包中也只提供这三种方法,不过本文并未尝试这几种方法,有兴趣的可以自己尝试下。
VaR估计思路
从之前的叙述中可以看出,通过copula函数得到的组合分布函数没有非常好的解析表达式,所以直接通过定义计算VaR的方法行不通,一般采取与蒙特卡洛方法相结合的方式,生成给定copula函数下的随机数,模拟资产组合的收益序列,再根据组合权重得到组合总收益,重复若干次,取p分位数。
随机数构造
使用蒙特卡洛方法的难点在于生成给定copula函数下的随机数,需要用到Nelsen定理,详见参考文献[2]

用Nelson定理构造随机数的方法如下

看了下copulib的源码,就是用这种方法构造的。而如果是多元正态copula或者多元t-copula的话, 有更简便的方法。以二元为例,可以往更高维推广
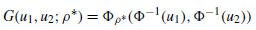
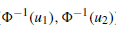 服从二元正态,可以直接模拟,然后再用标准正态分布函数作用,就可以得到符合给定多元正态copula的随机数,多元t-copula分布类似。
服从二元正态,可以直接模拟,然后再用标准正态分布函数作用,就可以得到符合给定多元正态copula的随机数,多元t-copula分布类似。
在得到符合给定copula分布的随机数u后,根据单个资产的分布F,可以得到单资产对应的随机数z
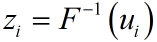
随后可以根据权重计算组合收益进而估计VaR。
综上,可以将Copula函数估计VaR的过程总结如下
第一步:根据单变量模型对所有单资产进行建模,估计分布函数F;第二步:根据所有的分布函数F和给定copula函数,最大化对数似然函数估计参数;第三步:根据各资产权重得到组合收益序列,取p分位数作为VaR估计值
3.实证分析
数据:S&P500、US 10yr T-Note Fixed Term(同上一篇)
区间:2001-2010
蒙特卡洛模拟次数:10000次
数据和代码在后台回复“VaR5”获取
仅估计最后一天的VaR。代码中未给出太多注释,可以参见文献[1]第九章习题。
前两道题首先通过threshold correlation说明正态性假设并不符合实际,threshold correlation定义如下,r(p)表示r的p分位数

结果如下
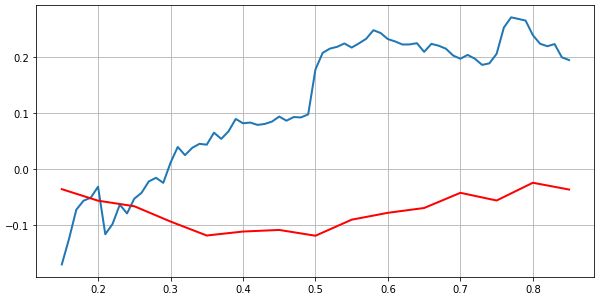
蓝色线为真实收益序列的threshold correlation,红色为标准正态的,如果将真实收益序列转化为标准收益,结果如下
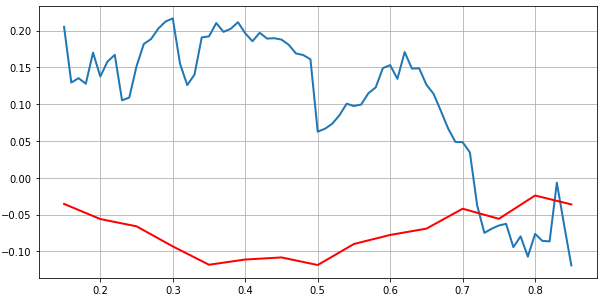
可以看出,二者相差很大,说明用多元正态进行建模并不符合实际。
1def getThre_cor(data,column1,column2,p):
2 cor = pd.DataFrame(p,columns = ['p'])
3 cor['thre_cor'] = 0
4 for i in range(cor.shape[0]):
5 if p[i] <=0.5:
6 condition1 = (data[column1] <= np.percentile(data[column1],p[i]*100))
7 condition2 = (data[column2] <= np.percentile(data[column2],p[i]*100))
8 else:
9 condition1 = (data[column1] > np.percentile(data[column1],p[i]*100))
10 condition2 = (data[column2] > np.percentile(data[column2],p[i]*100))
11 datas = data.loc[condition1 & condition2,:]
12 cor.loc[i,'thre_cor'] = np.corrcoef(datas[column1],datas[column2])[0,1]
13 return cor
14
15def Thre_cor_norm(num,rou):
16 np.random.seed(52)
17 data = pd.DataFrame(index = range(num))
18 data['r1'] = np.random.normal(size=(num,1))
19 data['r2'] = np.random.normal(size=(num,1))
20
21 data['r1_c'] = data['r1']
22 data['r2_c'] = data.r1*rou + data.r2*(1 - rou**2)**0.5
23 return data
24
25p = np.arange(0.15,0.90,0.05
)
26rou = np.corrcoef(data1.Log_Return_SP,data1.Log_Return_US)[0,1]
27data_norm = Thre_cor_norm(30000,rou)
28cor_norm = getThre_cor(data_norm,'r1_c','r2_c',p)
29
30p = np.arange(0.15,0.86,0.01)
31cor = getThre_cor(data1,'Log_Return_SP','Log_Return_US',p)
32ax = plt.figure(figsize=(10,5))
33plt.plot(cor.p,cor.thre_cor,linewidth = 2)
34plt.plot(cor_norm.p,cor_norm.thre_cor,linewidth = 2,color = 'red')
35plt.grid()
36plt.show()
第三道题为用t-garch分别对两个单资产进行建模,估计参数d,不再说明;
第四道题为用第三问的结果建立二元正态copula模型,估计组合VaR,过程前面已经说明,代码如下
估计copula函数的参数
1
def getNegativeLoglikelihood_copula(rou,r):
2 LogLikeLihood = -r.shape[0]*np.log(1 - rou**2)/2 - ((r.norm1**2 +r.norm2**2 - 2*rou*r.norm1*r.norm2)/(2*(1 - rou**2)) -
3 0.5*(r.norm1**2 + r.norm2**2)).sum()
4 return -LogLikeLihood
5
6rou_best = optimize.fmin(getNegativeLoglikelihood_copula,rou0, \
7 args=(copula_data,),ftol = 0.000000001)
8print('估计结果为:',rou_best)
模拟
1data4['u1c'] = data4['u1']
2data4['u2c'] = data4.u1*rou + data4.u2*(1 - rou**2)**0.5
3data4['F1'] = norm(0,1).cdf(data4['u1c'])
4data4['F2'] = norm(0,1).cdf(data4['u2c'])
5data4['z1'] = t(d_SP).ppf(data4.F1)*((d_SP-2)/d_SP)**0.5
6data4['z2'] = t(d_US).ppf(data4.F2)*((d_US-2)/d_US)**0.5
7data4['R1'] = data4.z1*sigma_SP**0.5
8data4['R2'] = data4.z2*sigma_US**0.5
9data4['R'] = 0.5*data4.R1 +0.5* data4.R2
10VaR = -np.percentile(data4.R,1)
最终估计结果为VaR = 0.0101,可以与上篇文章最后一日的结果相对比,基本上是一致的。
为了与文献[2]结果统一,代码中大部分地方用的参数都是直接从文献中取的,小部分参数估计结果与文献有差异,也直接用了文献的数字,对代码或者文章有疑问的,欢迎交流。
-END-
参考文献
1.Christoffersen, Peter F. Elements of financial risk management. Academic Press, 2011.
2.韦艳华, 张世英. Copula 理 论 及 其 在 金 融 分 析 上 的 应 用[J].

Python爱好者社区历史文章大合集:
Python爱好者社区历史文章列表(每周append更新一次)
 福利:文末扫码立刻关注公众号,“Python爱好者社区”
,开始学习Python课程:
福利:文末扫码立刻关注公众号,“Python爱好者社区”
,开始学习Python课程:
关注后在公众号内回复“课程”即可获取:
小编的Python入门免费视频课程!!!
【最新免费微课】小编的Python快速上手matplotlib可视化库!!!
崔老师爬虫实战案例免费学习视频。
陈老师数据分析报告制作免费学习视频。
玩转大数据分析!Spark2.X+Python 精华实战课程免费学习视频。











