作者:苏克,零基础、转行python爬虫与数据分析
博客:https://www.makcyun.top
摘要: 现在很多网页都采取JavaScript进行动态渲染,其中包括Ajax技术。有的网页虽然也用Ajax技术,但接口参数可能是加密的无法直接获得,比如淘宝;有的动态网页也采用JavaScript,但不是Ajax技术,比如Echarts官网。所以,当遇到这两类网页时,需要新的采取新的方法,这其中包括干脆、直接、好用的的Selenium大法。东方财富网的财务报表网页也是通过JavaScript动态加载的,本文利用Selenium方法爬取该网站上市公司的财务报表数据。
1. 实战背景 2. 网页分析 3. Selenium知识 4. 编码实现 4.1. 思路 4.2. 爬取单页表格 4.3. 分页爬取 4.4. 通用爬虫构造 4.5. 完整代码
1. 实战背景
很多网站都提供上市公司的公告、财务报表等金融投资信息和数据,比如:腾讯财经、网易财经、新浪财经、东方财富网等。这之中,发现东方财富网的数据非常齐全。
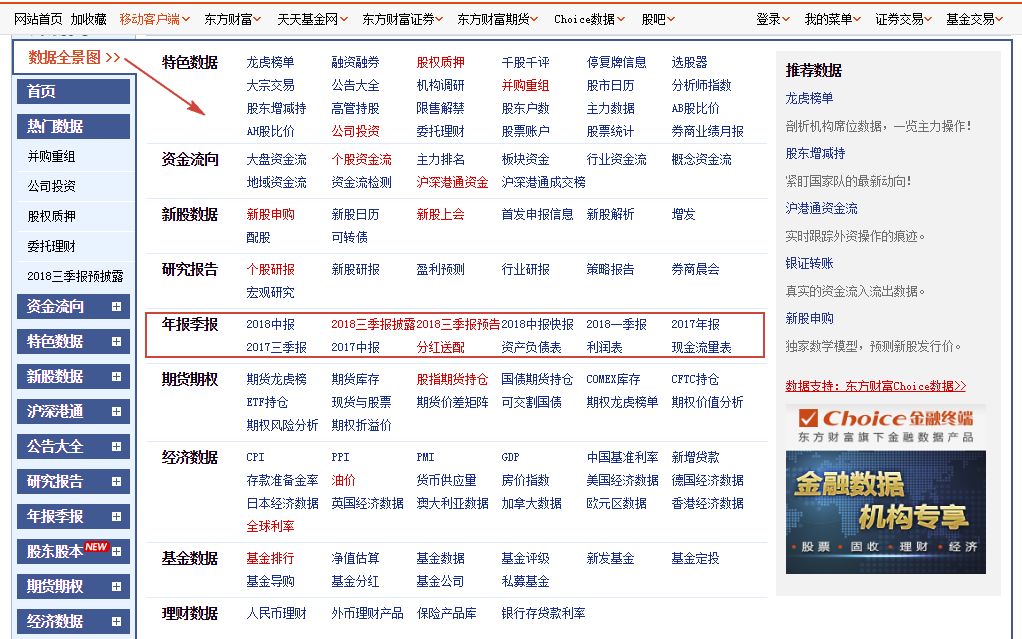
东方财富网有一个数据中心:http://data.eastmoney.com/center/,该数据中心提供包括特色数据、研究报告、年报季报等在内的大量数据(见下图)。
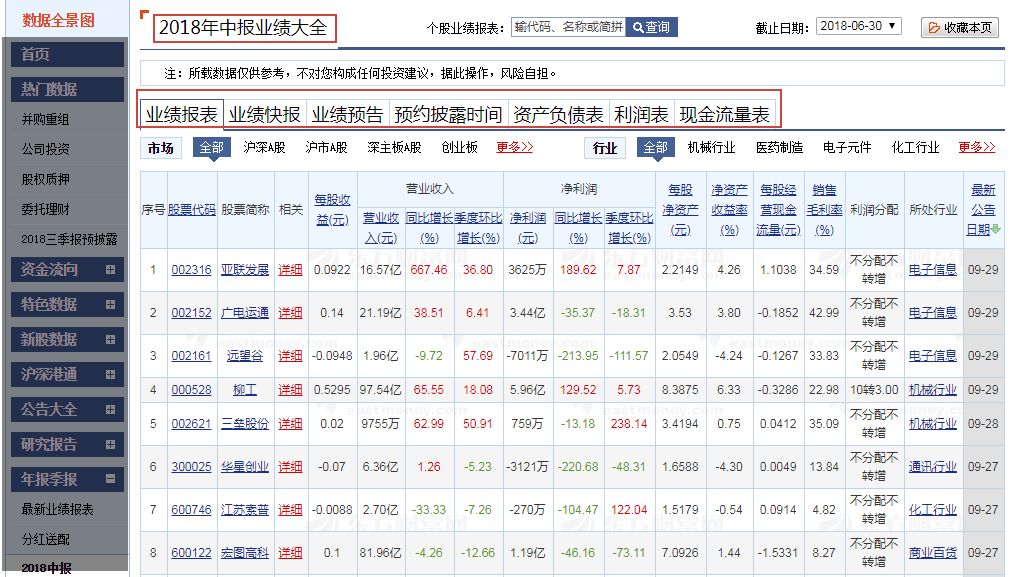
以年报季报类别为例,我们点开该分类查看一下2018年中报(见下图),可以看到该分类下又包括:业绩报表、业绩快报、利润表等7个报表的数据。以业绩报表为例,报表包含全部3000多只股票的业绩报表数据,一共有70多页。
假如,我们想获取所有股票2018年中的业绩报表数据,然后对该数据进行一些分析。采取手动复制的方法,70多页可以勉强完成。但如果想获取任意一年、任意季度、任意报表的数据,要再通过手动复制的方法,工作量会非常地大。举个例子,假设要获取10年间(40个季度)、所有7个报表的数据,那么手动复制的工作量大约将是:40×7×70(每个报表大约70页),差不多要重复性地复制2万次!!!可以说是人工不可能完成的任务。所以,本文的目标就是利用Selenium自动化技术,爬取年报季报类别下,任意一年(网站有数据至今)、任意财务报表数据。我们所需要做的,仅是简单输入几个字符,其他就全部交给电脑,然后过一会儿打开excel,就可以看到所需数据"静静地躺在那里",是不是挺酷的?
好,下面我们就开始实操一下。首先,需要分析要爬取的网页对象。
2. 网页分析
之前,我们已经爬过表格型的数据,所以对表格数据的结构应该不会太陌生,如果忘了,可以再看一下这篇文章:https://www.makcyun.top/web_scraping_withpython2.html
我们这里以上面的2018年中报的业绩报表为例,查看一下表格的形式。
网址url:http://data.eastmoney.com/bbsj/201806/lrb.html,bbsj代表年报季报,201803代表2018年一季报,类似地,201806表示年中报;lrb是利润表的首字母缩写,同理,yjbb表示业绩报表。可以看出,该网址格式很简单,便于构造url。
接着,我们点击下一页按钮,可以看到表格更新后url没有发生改变,可以判定是采用了Javscript。那么,我们首先判断是不是采用了Ajax加载的。方法也很简单,右键检查或按F12,切换到network并选择下面的XHR,再按F5刷新。可以看到只有一个Ajax请求,点击下一页也并没有生成新的Ajax请求,可以判断该网页结构不是常见的那种点击下一页或者下拉会源源不断出现的Ajax请求类型,那么便无法构造url来实现分页爬取。
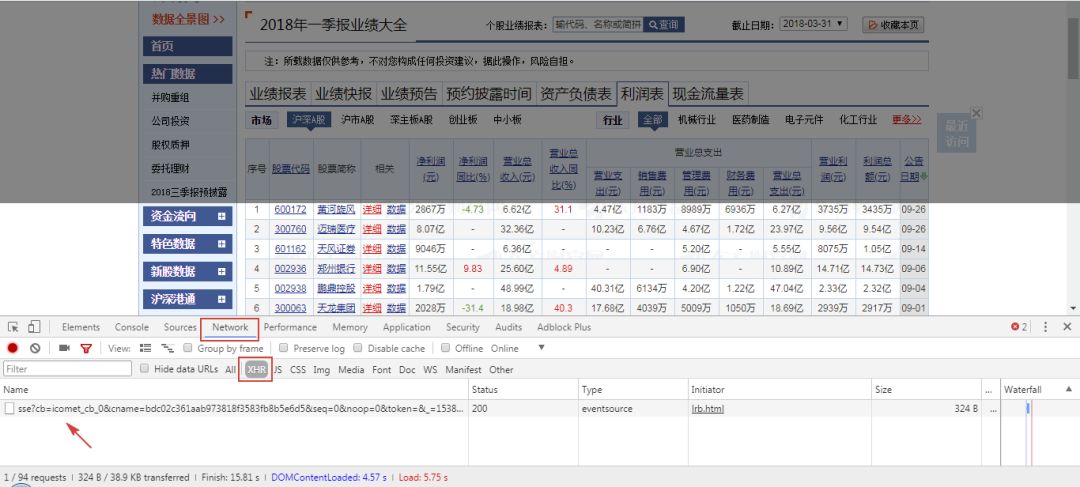
XHR选项里没有找到我们需要的请求,接下来试试看能不能再JS里找到表格的数据请求。将选项选为JS,再次F5刷新,可以看到出现了很多JS请求,然后我们点击几次下一页,会发现弹出新的请求来,然后右边为响应的请求信息。url链接非常长,看上去很复杂。好,这里我们先在这里打住不往下了。
可以看到,通过分析后台元素来爬取该动态网页的方法,相对比较复杂。那么有没有干脆、直截了当地就能够抓取表格内容的方法呢?有的,就是本文接下来要介绍的Selenium大法。
3. Selenium知识
Selenium 是什么?一句话,自动化测试工具。它是为了测试而出生的,但在近几年火热的爬虫领域中,它摇身一变,变成了爬虫的利器。直白点说, Seleninm能控制浏览器, 像人一样"上网"。比如,可以实现网页自动翻页、登录网站、发送邮件、下载图片/音乐/视频等等。举个例子,写几行python代码就可以用Selenium实现登录IT桔子,然后浏览网页的功能。
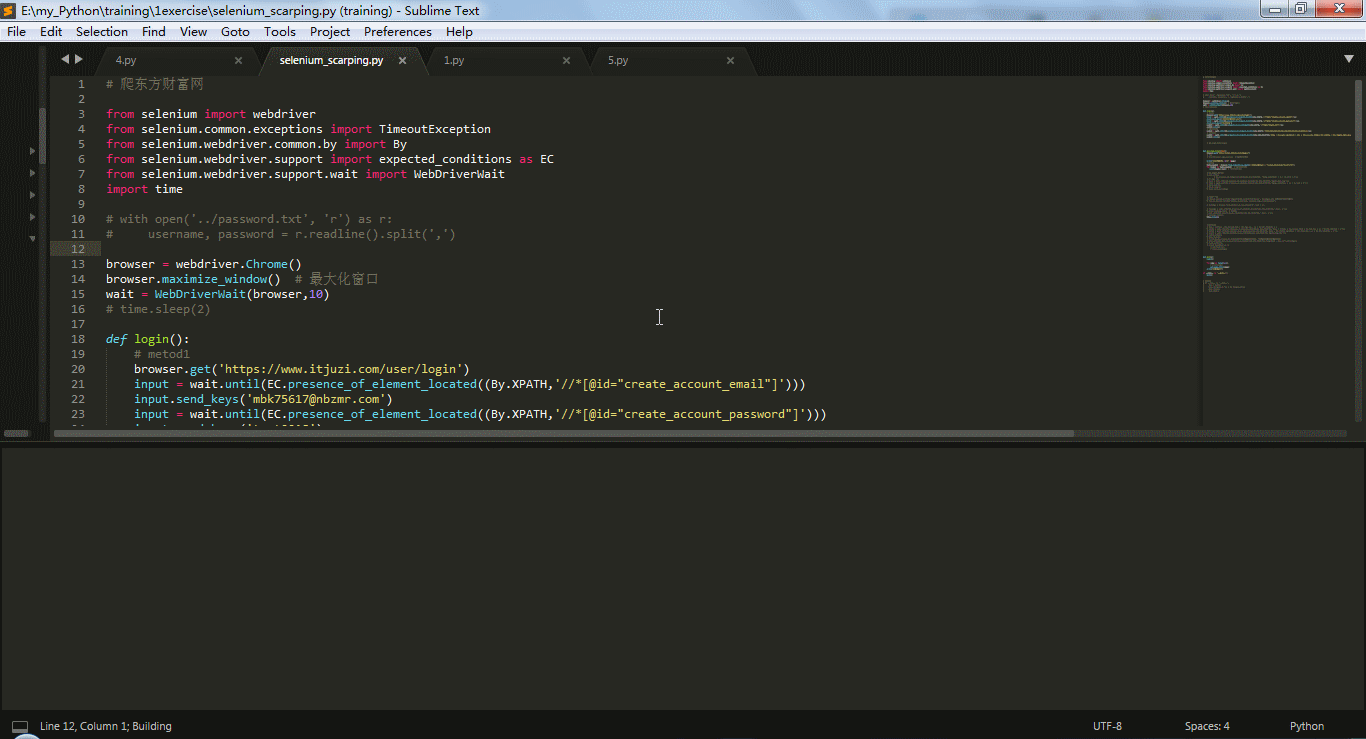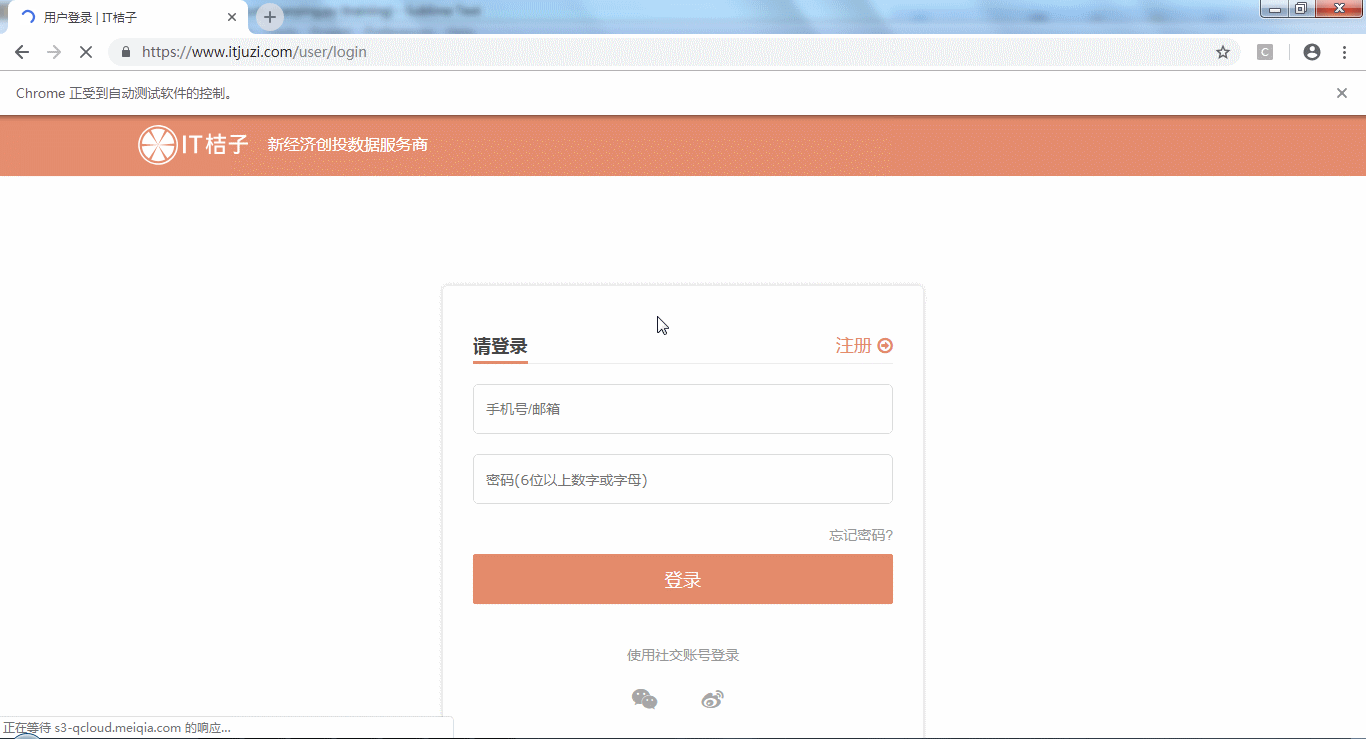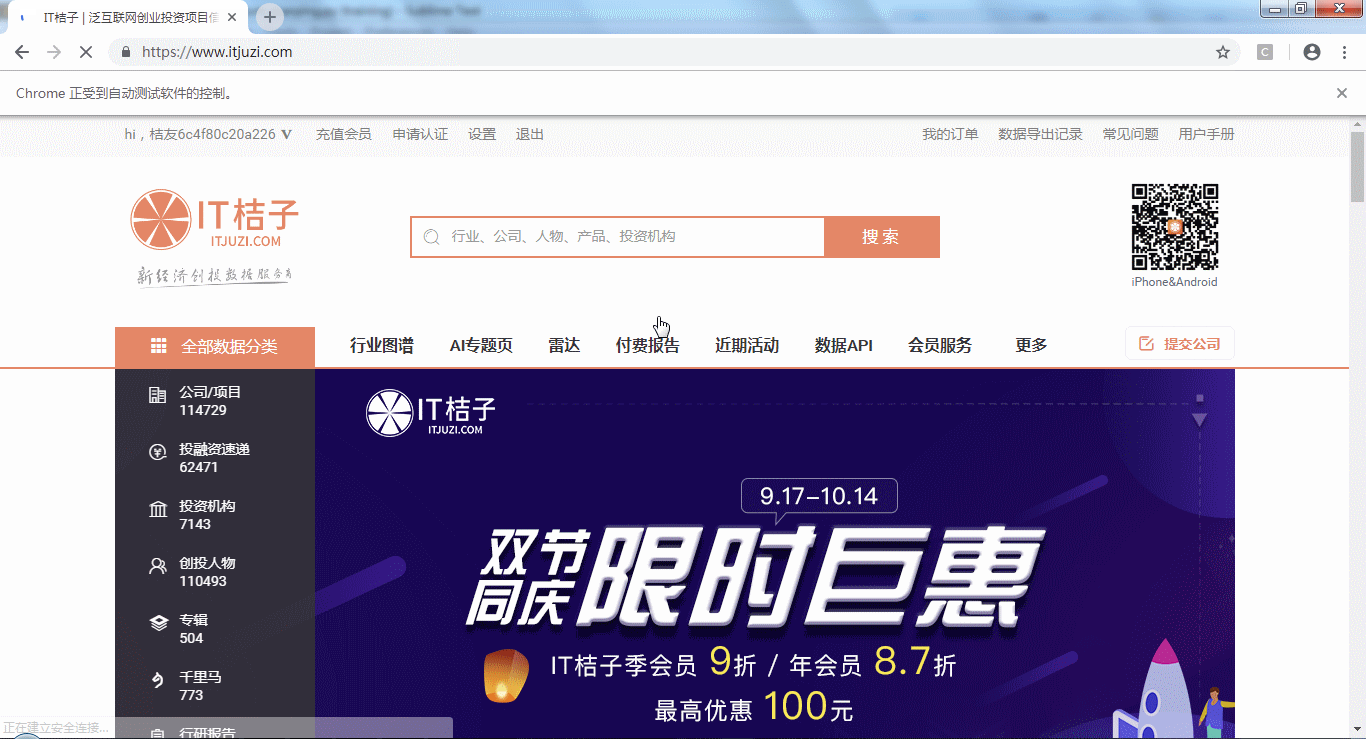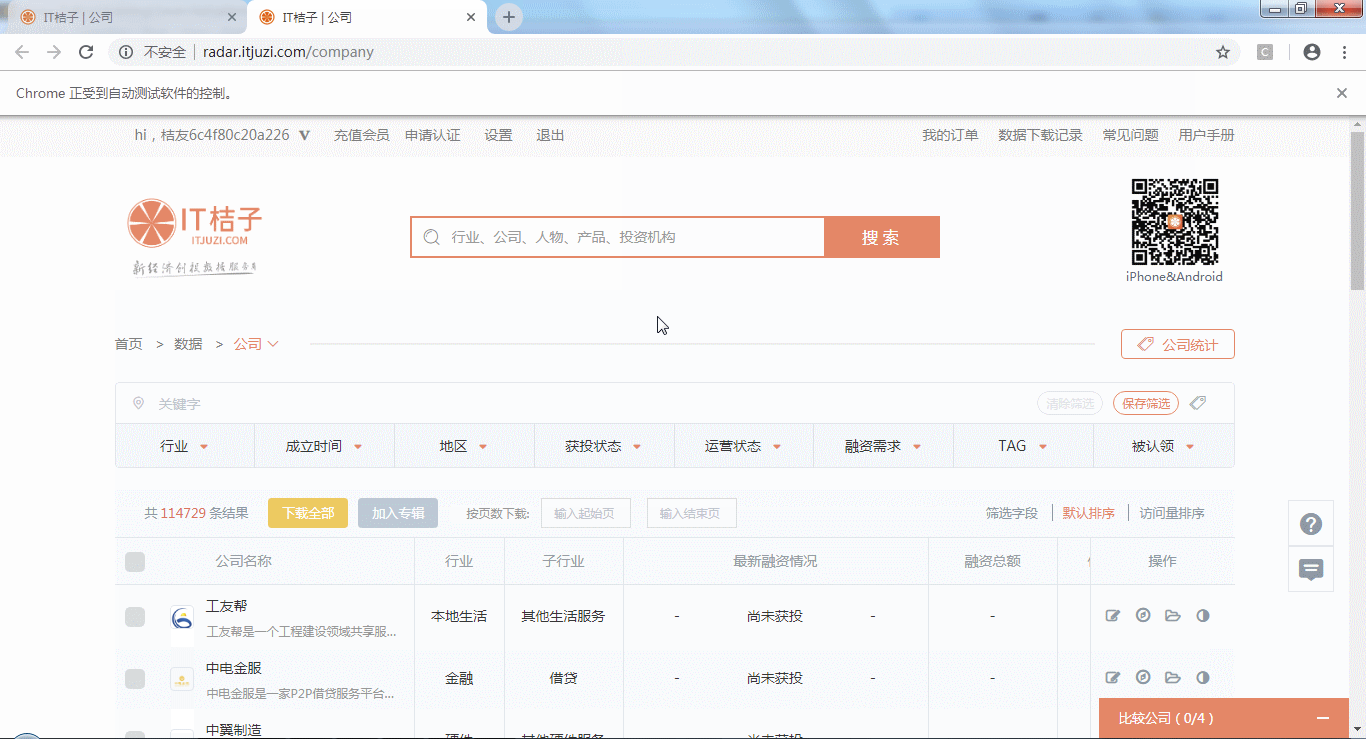
怎么样,仅用几行代码就能实现自动上网操作,是不是挺神奇的?当然,这仅仅是Selenium最简单的功能,还有很多更加丰富的操作,可以参考以下几篇教程:
参考网站:
Selenium官网: https://selenium-python.readthedocs.io/
SeleniumPython文档(英文版):http://selenium-python.readthedocs.org/index.html
SeleniumPython文档(中文版):https://selenium-python-zh.readthedocs.io/en/latest/faq.html
Selenium 基本操作:https://www.yukunweb.com/2017/7/python-spider-Selenium-PhantomJS-basic/
Selenium爬取淘宝信息实战:https://cuiqingcai.com/2852.html
只需要记住重要的一点就是:Selenium能做到"可见即可爬"。也就是说网页上你能看到的东西,Selenium基本上都能爬取下来。包括上面我们提到的东方财富网的财务报表数据,它也能够做到,而且非常简单直接,不用去后台查看用了什么JavaScript技术或者Ajax参数。下面我们就实际来操练下吧。
4. 编码实现
4.1. 思路
安装配置好Selenium运行的相关环境,浏览器可以用Chrome、Firefox、PhantomJS等,我用的是Chrome;
东方财富网的财务报表数据不用登录可直接获得,Selenium更加方便爬取;
先以单个网页中的财务报表为例,表格数据结构简单,可先直接定位到整个表格,然后一次性获取所有td节点对应的表格单元内容;
接着循环分页爬取所有上市公司的数据,并保存为csv文件。
重新构造灵活的url,实现可以爬取任意时期、任意一张财务报表的数据。
根据上述思路,下面就用代码一步步来实现。
4.2. 爬取单页表格
我们先以2018年中报的利润表为例,抓取该网页的第一页表格数据,网页url:http://data.eastmoney.com/bbsj/201806/lrb.html
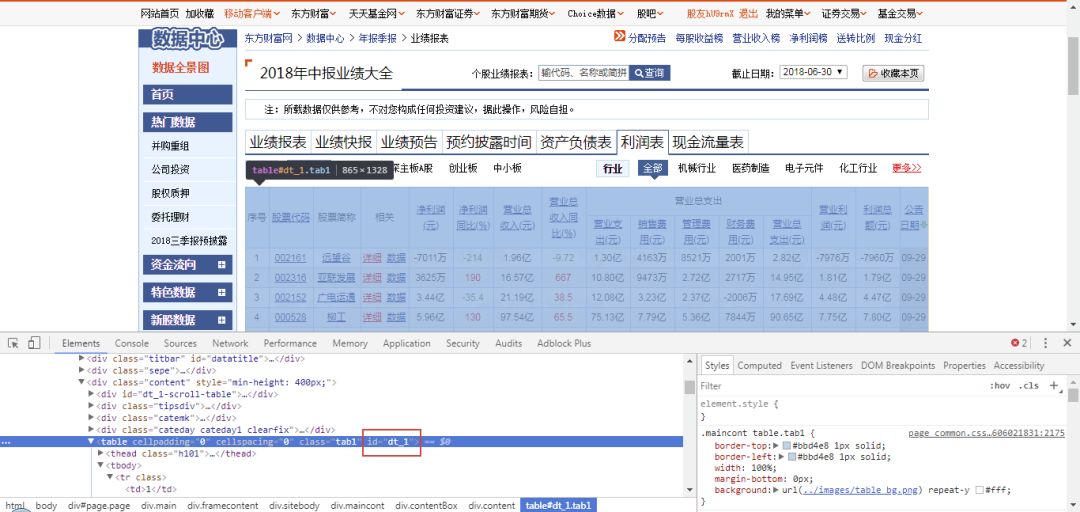
快速定位到表格所在的节点:id = dt_1,然后可以用Selenium进行抓取了,方法如下:
1from selenium import webdriver
2browser = webdriver.Chrome()
3# 当测试好能够顺利爬取后,为加快爬取速度可设置无头模式,即不弹出浏览器
4# 添加无头headlesss 1使用chrome headless,2使用PhantomJS
5# 使用 PhantomJS 会警告高不建议使用phantomjs,建议chrome headless
6
# chrome_options = webdriver.ChromeOptions()
7# chrome_options.add_argument('--headless')
8# browser = webdriver.Chrome(chrome_options=chrome_options)
9# browser = webdriver.PhantomJS()
10# browser.maximize_window() # 最大化窗口,可以选择设置
11
12browser.get('http://data.eastmoney.com/bbsj/201806/lrb.html')
13element = browser.find_element_by_css_selector('#dt_1') # 定位表格,element是WebElement类型
14# 提取表格内容td
15td_content = element.find_elements_by_tag_name("td") # 进一步定位到表格内容所在的td节点
16lst = [] # 存储为list
17for td in td_content:
18 lst.append(td.text)
19print(lst) # 输出表格内容
这里,使用Chrome浏览器构造一个Webdriver对象,赋值给变量browser,browser调用get()方法请求想要抓取的网页。接着使用find_element_by_css_selector方法查找表格所在的节点:'#dt_1'。
这里推荐一款小巧、快速定位css/xpath的Chrome插件:SelectorGadget,使用这个插件就不用再去源代码中手动定位节点那么麻烦了。
插件地址:https://chrome.google.com/webstore/detail/selectorgadget/mhjhnkcfbdhnjickkkdbjoemdmbfginb
紧接着再向下定位到td节点,因为网页中有很多个td节点,所以要用find_elements方法。然后,遍历数据节点存储到list中。打印查看一下结果:
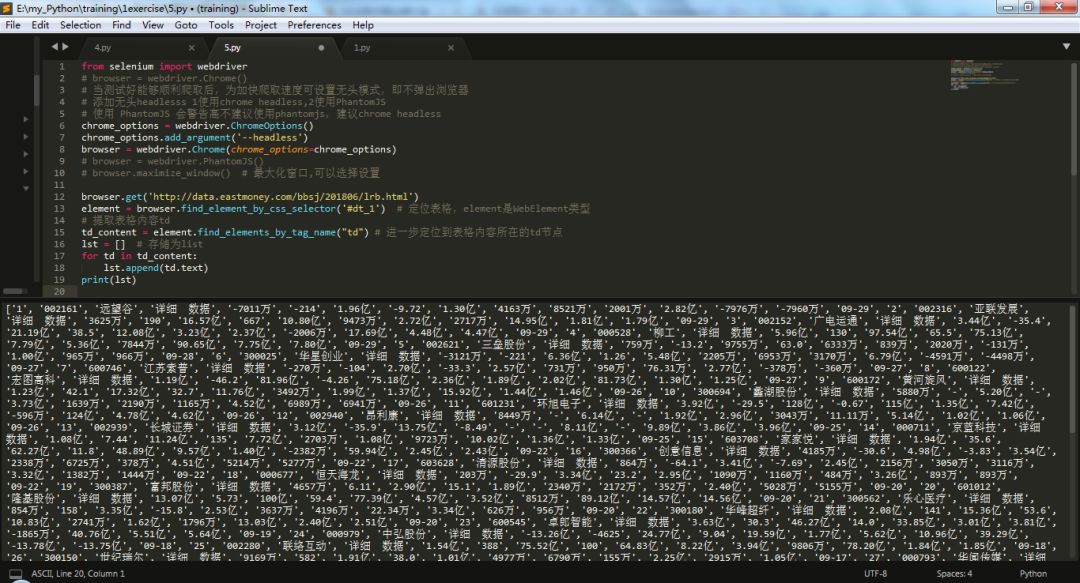
1# list形式:
2['1', '002161', '远望谷', ...'-7960万', '09-29',
3 '2','002316', '亚联发展', ...'1.79亿', '09-29',
4 '3',...
5 '50', '002683', '宏大爆破',...'1.37亿', '09-01']
是不是很方便,几行代码就能抓取下来这一页表格,除了速度有点慢。
为了便于后续存储,我们将list转换为DataFrame。首先需要把这一个大的list分割为多行多列的子list,实现如下:
1import pandas as pd
2# 确定表格列数
3col = len(element.find_elements_by_css_selector('tr:nth-child(1) td'))
4# 通过定位一行td的数量,可获得表格的列数,然后将list拆分为对应列数的子list
5lst = [lst[i:i + col] for i in range(0, len(lst), col)]
6# 原网页中打开"详细"链接可以查看更详细的数据,这里我们把url提取出来,方便后期查看
7lst_link = []
8links = element.find_elements_by_css_selector('#dt_1 a.red')
9for link in links:
10 url = link.get_attribute('href')
11 lst_link.append(url)
12lst_link = pd.Series(lst_link)
13# list转为dataframe
14df_table = pd.DataFrame(lst)
15# 添加url列
16df_table['url'] = lst_link
17print(df_table.head()) # 查看DataFrame
这里,要将list分割为子list,只需要确定表格有多少列即可,然后将每相隔这么多数量的值划分为一个子list。如果我们数一下该表的列数,可以发现一共有16列。但是这里不能使用这个数字,因为除了利润表,其他报表的列数并不是16,所以当后期爬取其他表格可能就会报错。这里仍然通过find_elements_by_css_selector方法,定位首行td节点的数量,便可获得表格的列数,然后将list拆分为对应列数的子list。同时,原网页中打开"详细"列的链接可以查看更详细的数据,这里我们把url提取出来,并增加一列到DataFrame中,方便后期查看。打印查看一下输出结果:
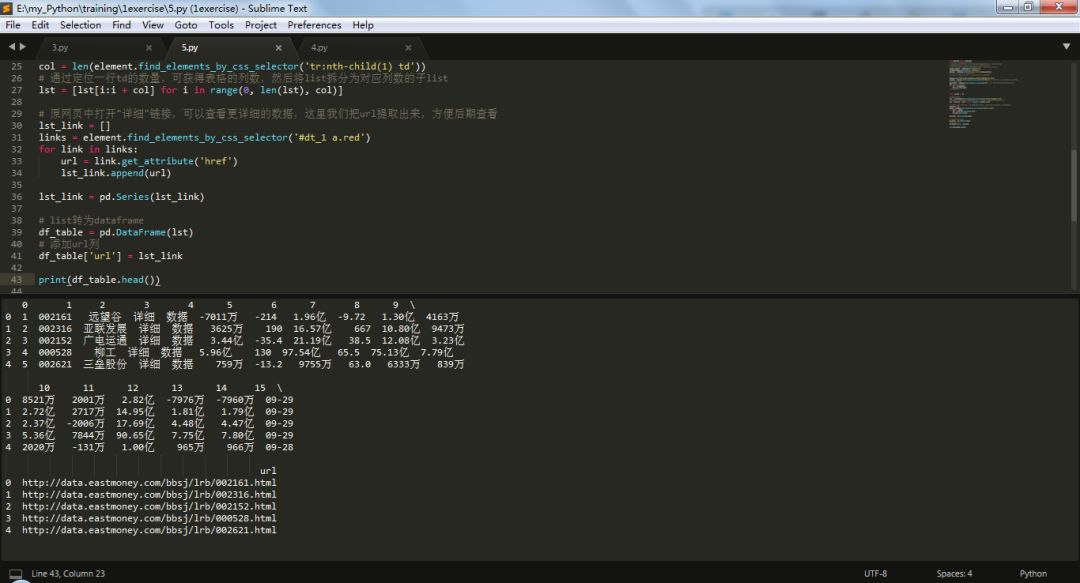
可以看到,表格所有的数据我们都抓取到了,下面只需要进行分页循环爬取就行了。
这里,没有抓取表头是因为表头有合并单元格,处理起来就非常麻烦。建议表格抓取下来后,在excel中复制表头进去就行了。如果,实在想要用代码完成,可以参考这篇文章:https://blog.csdn.net/weixin_39461443/article/details/75456962
4.3. 分页爬取
上面完成了单页表格的爬取,下面我们来实现分页爬取。
首先,我们先实现Selenium模拟翻页跳转操作,成功后再爬取每页的表格内容。
1from selenium import webdriver
2from
selenium.common.exceptions import TimeoutException
3from selenium.webdriver.common.by import By
4from selenium.webdriver.support import expected_conditions as EC
5from selenium.webdriver.support.wait import WebDriverWait
6import time
7
8browser = webdriver.Chrome()
9browser.maximize_window() # 最大化窗口,可以选择设置
10wait = WebDriverWait(browser, 10)
11def index_page(page):
12 try:
13 browser.get('http://data.eastmoney.com/bbsj/201806/lrb.html')
14 print('正在爬取第: %s 页' % page)
15 wait.until(
16 EC.presence_of_element_located((By.ID, "dt_1")))
17 # 判断是否是第1页,如果大于1就输入跳转,否则等待加载完成。
18 if page > 1:
19 # 确定页数输入框
20 input = wait.until(EC.presence_of_element_located(
21 (By.XPATH,
'//*[@id="PageContgopage"]')))
22 input.click()
23 input.clear()
24 input.send_keys(page)
25 submit = wait.until(EC.element_to_be_clickable(
26 (By.CSS_SELECTOR, '#PageCont > a.btn_link')))
27 submit.click()
28 time.sleep(2)
29 # 确认成功跳转到输入框中的指定页
30 wait.until(EC.text_to_be_present_in_element(
31 (By.CSS_SELECTOR, '#PageCont > span.at'), str(page)))
32 except Exception:
33 return None
34
35def main():
36 for page in range(1,5): # 测试翻4页
37 index_page(page)
38if __name__ == '__main__':
39 main()
这里,我们先加载了相关包,使用WebDriverWait对象,设置最长10s的显式等待时间,以便网页加载出表格。判断表格是否加载出来,用到了EC.presence_of_element_located条件。表格加载出来后,设置一个页面判断,如果在第1页就等待页面加载完成,如果大于第1页就开始跳转。
要完成跳转操作,我们需要通过获取输入框input节点,然后用clear()方法清空输入框,再通过send_keys()方法填写相应的页码,接着通过submit.click()方法击下一页完成翻页跳转。
这里,我们测试一下前4页跳转效果,可以看到网页成功跳转了。下面就可以对每一页应用第一页爬取表格内容的方法,抓取每一页的表格,转为DataFrame然后存储到csv文件中去。
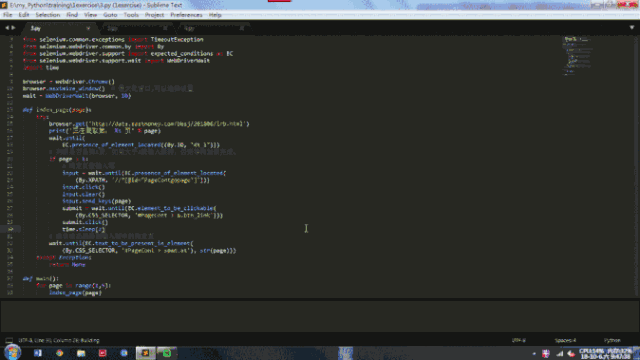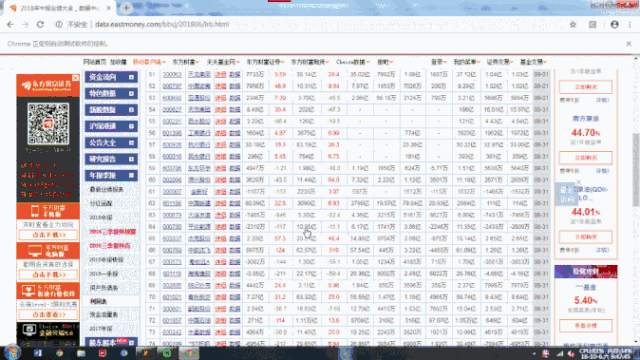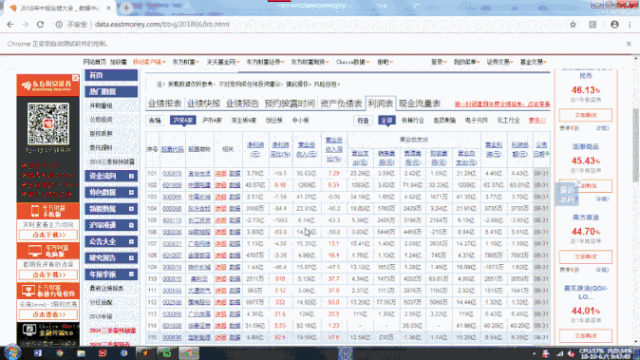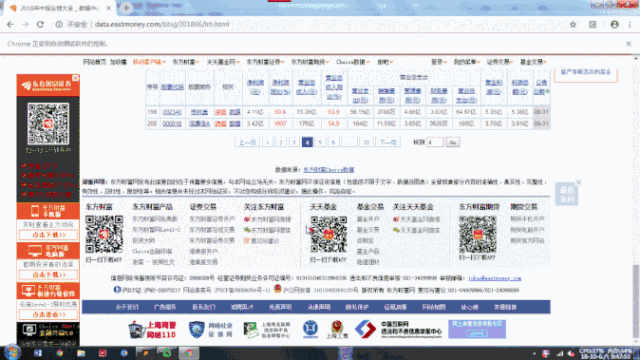
4.4. 通用爬虫构造
上面,我们完成了2018年中报利润表: http://data.eastmoney.com/bbsj/201806/lrb.html,一个网页表格的爬取。但如果我们想爬取任意时期、任意一张报表的表格,比如2017年3季度的利润表、2016年全年的业绩报表、2015年1季度的现金流量表等等。上面的代码就行不通了,下面我们对代码进行一下改造,变成更通用的爬虫。从图中可以看到,东方财富网年报季报有7张表格,财务报表最早从2007年开始每季度一次。基于这两个维度,可重新构造url的形式,然后爬取表格数据。下面,我们用代码进行实现:
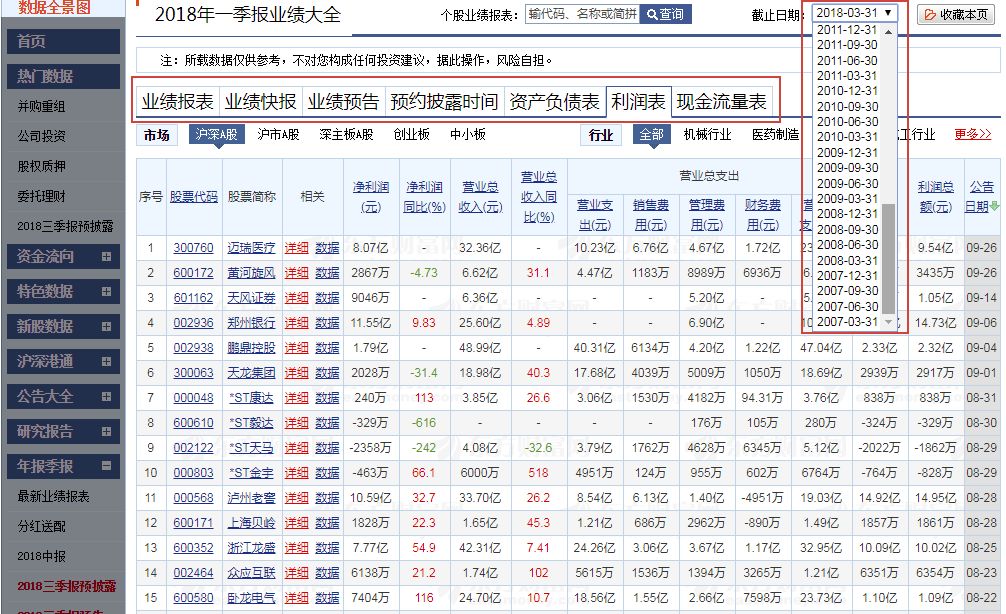
1# 重构url
2# 1 设置财务报表获取时期
3year = int(float(input('请输入要查询的年份(四位数2007-2018): ')))
4# int表示取整,里面加float是因为输入的是str,直接int会报错,float则不会
5while (year 2007 or year > 2018):
6 year = int(float(input('年份数值输入错误,请重新输入:')))
7quarter = int(float(input('请输入小写数字季度(1:1季报,2-年中报,3:3季报,4-年报): ')))
8while (quarter 1 or quarter > 4):
9 quarter = int(float(input('季度数值输入错误,请重新输入: ')))
10# 转换为所需的quarter 两种方法,2表示两位数,0表示不满2位用0补充
11quarter = '{:02d}'.format(quarter * 3)
12
# quarter = '%02d' %(int(month)*3)
13date = '{}{}' .format(year, quarter)
14
15# 2 设置财务报表种类
16tables = int(
17 input('请输入查询的报表种类对应的数字(1-业绩报表;2-业绩快报表:3-业绩预告表;4-预约披露时间表;5-资产负债表;6-利润表;7-现金流量表): '))
18dict_tables = {1: '业绩报表', 2: '业绩快报表', 3: '业绩预告表',
19 4: '预约披露时间表', 5: '资产负债表', 6: '利润表', 7: '现金流量表'}
20dict = {1: 'yjbb', 2: 'yjkb/13', 3: 'yjyg',
21 4: 'yysj', 5: 'zcfz', 6: 'lrb', 7: 'xjll'}
22category = dict[tables]
23
24# 3 设置url
25
url = 'http://data.eastmoney.com/{}/{}/{}.html' .format('bbsj', date, category)
26print(url) # 测试输出的url
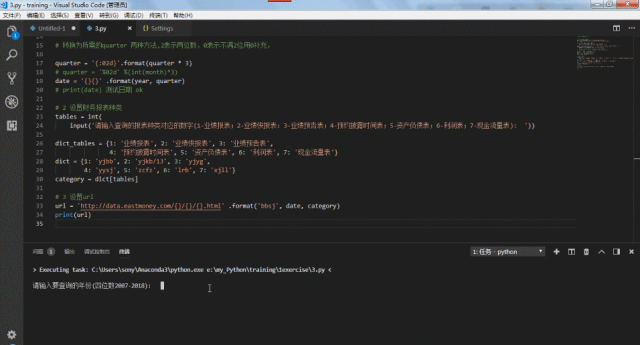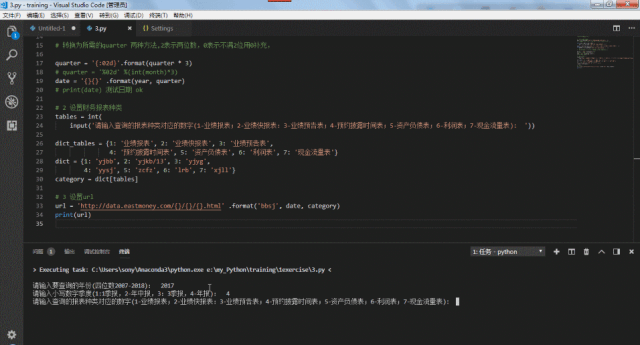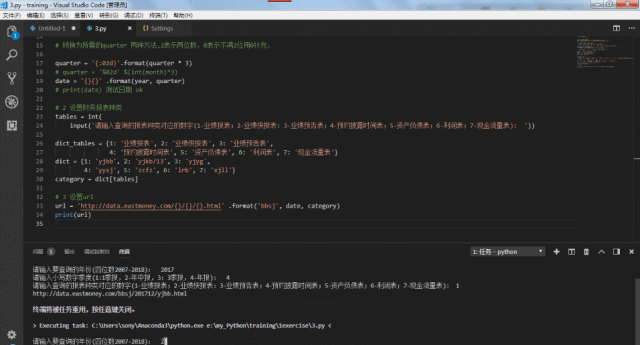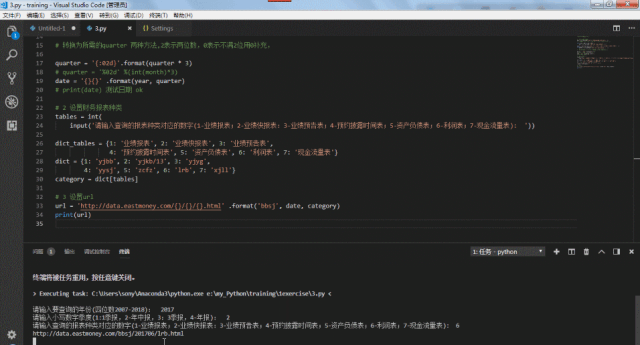
经过上面的设置,我们通过输入想要获得指定时期、制定财务报表类型的数值,就能返回相应的url链接。将该链接应用到前面的爬虫中,就可以爬取相应的报表内容了。
另外,除了从第一页开始爬取到最后一页的结果以外,我们还可以自定义设置想要爬取的页数。比如起始页数从第1页开始,然后爬取10页。
1# 4 选择爬取页数范围
2start_page = int(input('请输入下载起始页数:\n'))
3nums = input('请输入要下载的页数,(若需下载全部则按回车):\n')
4# 确定网页中的最后一页
5browser.get(url)
6# 确定最后一页页数不直接用数字而是采用定位,因为不同时间段的页码会不一样
7try:
8 page = browser.find_element_by_css_selector('.next+ a') # next节点后面的a节点
9except:
10 page = browser.find_element_by_css_selector('.at+ a')
11else:
12 print('没有找到该节点')
13# 上面用try.except是因为绝大多数页码定位可用'.next+ a',但是业绩快报表有的只有2页,无'.next+ a'节点
14end_page = int(page.text)
15
16if nums.isdigit():
17 end_page = start_page + int(nums)
18elif nums == '':
19 end_page = end_page
20else:
21 print('页数输入错误')
22# 输入准备下载表格类型
23print('准备下载:{}-{}' .format(date, dict_tables[tables]))
经过上面的设置,我们就可以实现自定义时期和财务报表类型的表格爬取了,将代码再稍微整理一下,可实现下面的爬虫效果:
视频截图:
背景中类似黑客帝国的代码雨效果,其实是动态网页效果。素材来源于下面这个网站,该网站还有很多酷炫的动态背景可以下载下来。
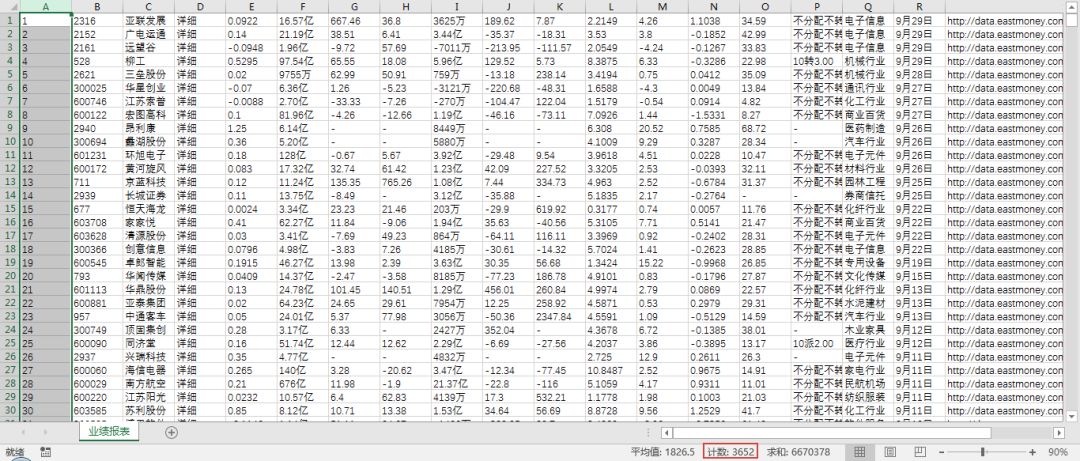
这里,我下载了所有上市公司的部分报表。
2018年中报业绩报表:
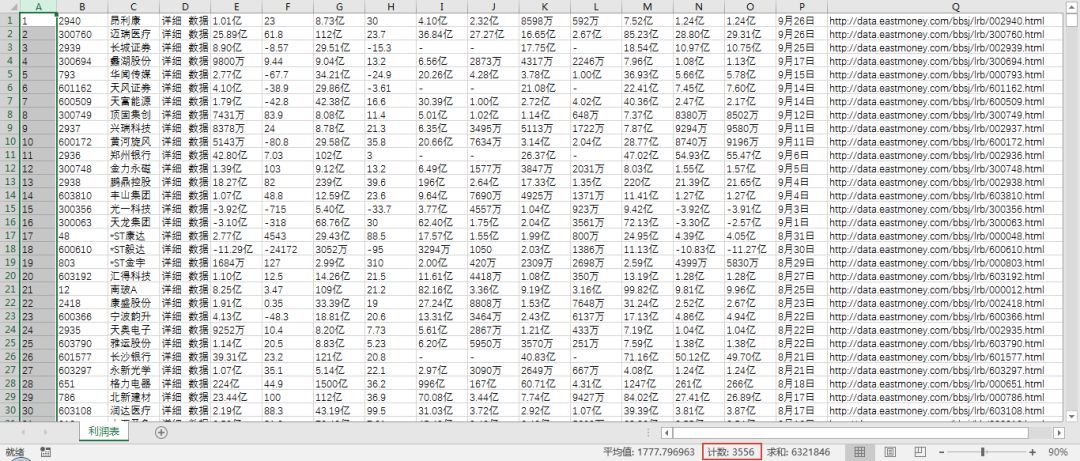
2017年报的利润表:
另外,爬虫还可以再完善一下,比如增加爬取上市公司的公告信息,设置可以爬任意一家(数家/行业)的公司数据而不用全部。
还有一个问题是,Selenium爬取的速度很慢而且很占用内存,建议尽量先尝试采用Requests请求的方法,抓不到的时候再考虑这个。文章开头在进行网页分析的时候,我们初步分析了表格JS的请求数据,是否能从该请求中找到我们需要的表格数据呢? 后续文章,我们换一个思路再来尝试爬取一次。
获取本文完整代码
请扫描下方二维码关注“数据科学俱乐部”后,回复“报表”二字获取

Python中文社区作为一个去中心化的全球技术社区,以成为全球20万Python中文开发者的精神部落为愿景,目前覆盖各大主流媒体和协作平台,与阿里、腾讯、百度、微软、亚马逊、开源中国、CSDN等业界知名公司和技术社区建立了广泛的联系,拥有来自十多个国家和地区数万名登记会员,会员来自以公安部、工信部、清华大学、北京大学、北京邮电大学、中国人民银行、中科院、中金、华为、BAT、谷歌、微软等为代表的政府机关、科研单位、金融机构以及海内外知名公司,全平台近20万开发者关注。
Python中文社区公众号底部回复“内推”
获取一周内推技术职位清单

▼ 点击下方阅读原文,学习网易云课堂数据分析师微专业









