
如果你的主要编程语言是python,那一定听说过IPython这个增强交互式编程环境(REPL)。IPython不仅仅是一个交互式编程环境(REPL),随着IPython集成库的更新,如今可以将其用于辅助高级计算任务。在这篇文章中,我们将看到多语言支持及分布式计算两项功能。
IPython提供了对文档的便捷访问,与matplotlib的集成,持久历史以及许多其他功能,可以极大地简化Python的交互式工作。IPython还附带了一系列“magic”命令,可以改变单行或代码块的效果;例如:您只需在输入Python语句之前在提示符下键入%% time,即可为代码计时。当使用带有IPython内核的Jupyter notebook时,所有这些功能也还有效,这样,就可以在使用相同命令的同时,在终端和基于浏览器的界面之间自由切换。
多语言计算
没有一种语言可以适合一切。IPython和Jupyter notebook允许在单个note或交互式会话中体现多种语言支持的优势。
下图,是一个Jupyter notebook片段,以最简单的方式体现了多语言功能。%% ruby 这个magic命令(双%%表示magic命令将应用于整个代码块)使得代码块的内容由Ruby解释器处理。--out标志将代码块的输出存储到命名变量中,并且这个全局变量可用于其他基于Python内核的代码块。接下来代码将Ruby的字符串输出转换为整数(注意,int()是合法的Python函数,但不是Ruby函数)。Ruby代码简单地将整数从1加到100;最终结果存储在a中。

这可以在不安装任何IPython或Jupyter内核扩展的情况下完成,仅需要安装Ruby。使用Perl,Bash或sh可以完成同样的事情,可以通过编辑 path to IPython]/core/magics/script.py 源文件中的列表来添加其他解释语言。
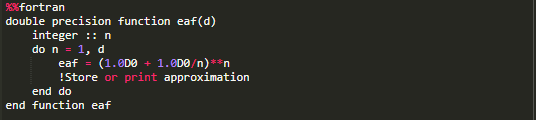
F2PY是NumPy / SciPy的一个组件,它可以编译和包装Fortran子例程,以便Fortran可以与Python一起使用。如果能够充分利用Fortran的快速数值运算以及Python的高级便利性和交互性,这将非常可人。使用F2PY需要几个手动步骤,但是,一个名为Fortran magic的第三方扩展(可以用pip安装)提供了一个在底层使用F2PY进行编译和界面创建的magic。所需要的只是Fortran代码块中的某一行或者一个函数(如果系统中尚不存在Fortran编译器,则可能需要安装Fortran编译器)。
下图显示了该过程。首先,定义一个名为eap()的python函数,该函数用于收敛到自然数e,它计算d个连续近似值,最后返回结果。接下来加载Fortran magic,这将生成一个用户警告(已折叠省略),因为这是为旧版本的IPython / Jupyter开发的(但一切仍然有效)。load命令定义我们在之后代码块中使用的代码块magic,这个代码块是一个相同功能的Fortran函数,称为eaf()。执行该代码块时,IPython会编译代码并生成Python接口。最后两步,在打开定时的情况下调用这两个程序,输出两个程序的执行时间,明显Fortran版本的速度提高了大约24倍。


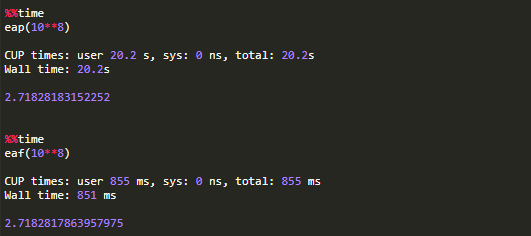
只需一个magic命令,就可以打包编译的Fortran命令,以便在终端或Jupyter notebook中交互式使用。由于程序的数字部分都是最容易翻译成Fortran的,这个过程受益最大,也是加速计算最简单方法,同时这也是IPython生态系统强大功能的一个很好的证明。
并行和分布式计算
IPython提供了许多方便的解决方案,用于在单个机器或多个联网计算机的处理核心之间分布计算。IPython并行计算工具可以完成大部分设置; 在简单的情况下,它允许在交互式上下文中执行并行计算,几乎与正常的单处理器计算一样简单。
在多个处理器上运行代码通常是为了加快速度或提高吞吐量。但是,这仅适用于某些类型的问题,并且只有在节省算法的时间超过在处理器之间移动数据的开销时才有效果。
如果你为了实现最大计算速度,那么在尝试利用并行或分布式计算之前,你必须尽可能地提高串行性能(在单个处理核心上的速度)。
这篇文章(https://hpc.nih.gov/training/handouts/171121_python_in_hpc.pdf)简明扼要地介绍了当核心语言是Python时可能遇到此问题的各种解决方法,并介绍了一些并行化策略。有很多方法可以加速Python,但这些方法都超出了本文的考虑范围(而且,无论语言如何,第一种方法都应该是对算法和数据结构的批判性研究)。
除了试图加快计算速度之外,网络化分布式计算的另一个目的是从计算机集群中收集信息或运行测试。例如,位于世界某地的一个Web服务器的管理员,可以利用下面的技术通过单个命令从所有服务器收集性能数据,并使用IPython会话作为中央控制中心。
首先是关于NumPy的说明。并行化Python计算的最简单方法就是在可能的情况下将其表示为NumPy数组上的一系列数组操作。这将自动在您的机器上的所有核心之间分配阵列数据,而且并行执行阵列算法(如果有任何疑问,请在观察CPU监视器(例如htop)时提交较长的NumPy计算,将看到所有核心都已启用)。并非每种计算都能以这种方式表达出来; 但如果程序已经允许并行执行的方式使用NumPy,而且尝试在多个核心上运行程序,这会引入不必要的进程间通信,减慢速度而不是加快速度。
如果程序不适合NumPy的阵列处理,IPython提供了其他几乎同样方便的方法来利用多个处理器。要使用这些工具,必须安装ipyparallel库(pip install ipyparallel)。
IPython和ipyparallel库支持并行和分布式计算的各种样式和范例。我已经构建了一些示例,并做了简单的演示。这只是一些提示,你可以立即开始实验,只需最少的设置,并了解可用的范围。要了解更多内容,请参阅文档(https://media.readthedocs.org/pdf/ipyparallel/latest/ipyparallel.pdf)。
第一个例子在每台机器的CPU核心上复制计算。如上所述,NumPy会自动在这些核心之间划分工作,但是使用IPython,您可以通过其他方式访问。首先,您必须创建一个计算“集群”。 随着IPython和ipyparallel的安装,有几个好用的命令。创建集群的命令是:
$ ipcluster start --n=x
通常,x设置为系统中的核心数;我的笔记本电脑有四个,所以--n = 4。该命令应该会生成一条消息,表明已创建集群。您现在可以在IPython或Jupyter notebook中与它进行交互。
下图显示了使用群集的Jupyter会话的一部分。前两行导入ipyparallel库并实例化客户端。第三行检查所有四个核心是否实际可用,显示Client实例的ID列表。接着导入choice()函数,它从一个集合中随机选择一个元素,用于绘图的pylab,并配置matplotlib。


请注意%% px 这个magic命令。这个命令位于代码块顶部,将单元格中的计算复制到每个核心的单独进程中。由于我们使用四个核心启动了我们的集群,因此将有四个进程,每个进程都有自己的所有变量的私有版本,并且每个进程独立于其他变量运行。
接下来的两个代码块计算一个具有一百万步的2D随机游走。它们都由%% timeit magic命令装饰,用于计算算法次数。第一个单元使用--targets参数将计算限制为单个核心上的单个进程(核心“0”; 我们可以选择0到3之间的任何数字); 第二个使用%% px表示使用所有核心。注意,在这种并行计算方式中,每个变量(包括每个列表)都在核心之间进行复制。这与NumPy中的数组计算形成对比,NumPy中的数组在核心之间分配,每个核心都处理一个较大问题的一部分。而在此示例中,每个核心将单独的计算所有百万步随机游走。
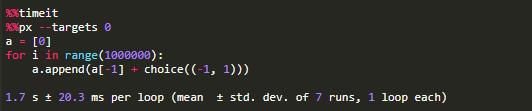
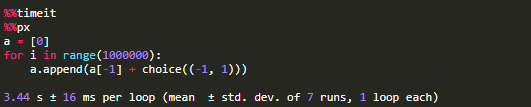
按照输出的计时数据,实际上第二种情况下,在相同的时间内完成了四倍的工作,因为计算完成了四次。然而,第二个程序实际上花了两倍多的时间,这意味着我们只实现了大约两倍的加速。这是由于进程间通信和设置的开销,并且随着计算变得更加冗长而减少。
如果将一个绘图命令附加到上述程序中,看看随机行走是什么样的,会发生什么?下图显示了每个进程如何生成自己的绘图(使用自己的随机种子)。这种多处理方式可以是一种方便的方法,可以并排比较不同程序的计算,而无需一个接一个地运行。
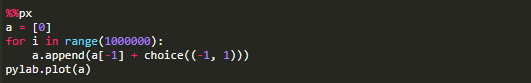
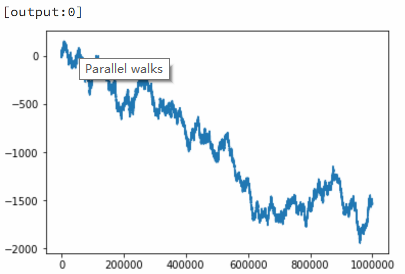
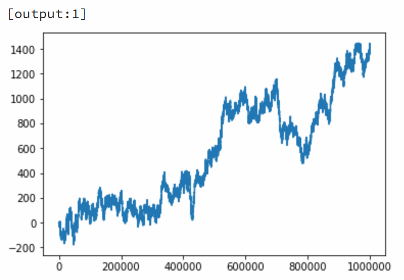
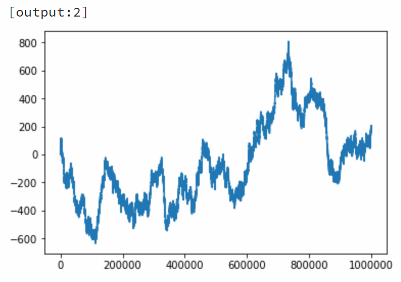
还可以使用%px在群集上执行“ one-liner ”命令,可以在代码块中混合串行和并行代码。如在导入随机整数函数(randint())之后:

输出单元按顺序标记并显示了四个计算核心中的每一个产生了的结果。
当希望每个处理器在其自己独立运行时,%% px和%px magic命令是在处理器集群之间复制计算的简便方法。使用多个处理器加速列表计算的经典技术遵循不同的模式:列表在处理器之间划分,每个处理器在其各个段上工作,并将结果重新组合成单个列表,如果每个数组元素的计算不依赖于其他元素,则此方法效果最佳。
IPython提供了一些便利功能,使这些计算易于表达。我们看看最有用的那个。
首先,考虑Python的map()函数:
list(map(lambda x:f(x), range(16)))
这将函数f()应用于列表[0..15]的每个元素并返回结果列表。它将在一个处理器上执行此操作,一次一个元素。但是,如果我们如上所述启动了一个集群,我们可以这样写:
rp[:].map_sync(lambda x:f(x), range(16))
这会将列表分成四个相等长度的段,将每个段发送到一个单独的处理器,然后将结果重新放在一起,替换原始列表。可以通过索引rp来控制使用哪些处理器,这样就可以轻松告诉rp [0:1]在一个数组上工作,而rp [2:3]则执行其他操作。
使用的处理器不必是本地计算机上的核心。它们可以是Internet或本地网络访问的任何计算机上。通过网络进行计算的最简单设置是使用SSH访问的计算机。当然,配置比简单地输入ipcluster命令要复杂一些。我写了一个文档(https://github.com/leephillips/ipyparallelSSHconfig/blob/master/advipSupp.pdf)来描述最小的示例配置,它将使您开始通过SSH在网络集群上进行计算。
20多年来,计算科学家依靠各种并行计算方法作为执行大型计算的唯一方法。随着对更准确气候建模的渴望,处理越来越大的机器学习数据集,更好地模拟星系演化,许多不同领域中需要超过单处理器的更强大的计算功能,采用并行处理可以打破这个瓶颈。这使得人们愿意重写算法以将特殊并行库合并到他们的Fortran或C程序中,以及根据个人超级计算机的特点定制他们的程序的专属领域。
使用ipyparallel库的IPython提供了前所未有的能力,将科学Python的探索能力与几乎即时访问多个计算核心相结合。系统可以直观地与本地或网络的计算节点集群进行交互,而不管集群的实现方式如何。这种易于交互使用帮助IPython和Python成为各种学科的科学计算和数据科学的流行工具。例如,这篇论文(https://link.springer.com/content/pdf/10.1007%2Fs10472-017-9556-8.pdf)提出了机器学习和生物化学交叉问题的研究,得益于ipyparallel的易用性。
有时,一种语言更容易表达,或者计算会以另一种语言更快地运行。以前多语言计算需要精心设计的接口来使用多个编译器或在单独的解释器中工作。通过允许用户随意使用不同语言进行编码,增强IPython和Jupyter计算的流动性和探索性的能力,实现了与计算机交互的真正新方法。
IPython和Jupyter不仅仅是解释器的接口。本文中描述的计算体验增强是相当新颖的,但不仅仅是软件开发人员的好奇——它们已经被科学家和工程师使用。诸如此类的工具是创造力的杠杆;有趣的事情将会很有趣。
英文原文:https://lwn.net/SubscriberLink/756192/ebada7ecad32f3ad/
译者:朱侨文








