不久前,Facebook 在首届 PyTorch 开发者大会发布了 PyTorch1.0 预览版,标志着这一框架更为稳定可用。从去年年初发布以来,PyTorch 已经成为明星框架,发展速度甚至有力压 TensorFlow 的趋势。据网友统计,在最新的 ICLR 2019 提交论文中,提及 TensorFlow 的论文数量从 228 升到了 266,而提及 PyTorch 的论文数量从 2018 年的 87 激增到了 252,这是否也是 PyTorch 即将赶超 TensorFlow 的又一证明?
ICLR 提交论文提及频率
不久前,Reddit 上的一条帖子吸引了大家的关注:有网友统计,相比于 2018 年,在 ICLR 2019 提交论文中,提及不同框架的论文数量发生了极大变化。
首先,说下 2018 年和 2019 年论文提交数量。ICLR 2019 将于明年 5 月 6 日-9 日在美国新奥尔良举行,今年 9 月 27 日下午 18 时,大会论文提交截止。据统计,ICLR 2019 共收到 1591 篇论文投稿,相比去年的 1000 余篇增长了 60%。
其次,介绍下统计方法,相当简单。在 Frankensteinian search 搜索框下分别搜索提及不同框架的论文结果,如下:
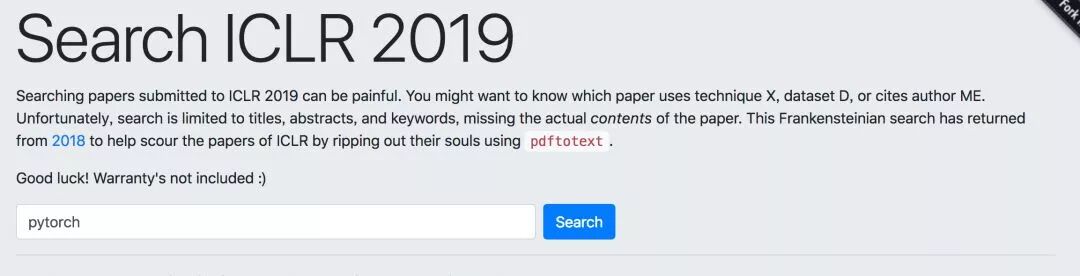
网友发现,提及 TensorFlow 的论文数量从 2018 年的 228 篇略微提升到了 266 篇,Keras 从 42 升到 56,但 Pytorch 的数量从 87 篇提升到了 252 篇。从数据上可以明显看出,采用 PyTorch 的 ICLR 论文在这一年内几乎要超越 TensorFlow。
TensorFlow:228→266
Keras: 42→56
Pytorch:87→252
在 PyTorch 1.0 推出之际,这样的数据统计让我们不得不联想到:TensorFlow 的深度学习框架霸主地位是否还保得住?既然 PyTorch 1.0 预览版已经发布,那么让我们再把两个框架放在一起对比下,看哪一款才是适合你的深度学习框架。
TensorFlow VS PyTorch
自 2015 年开源以来,深度学习框架的天下就属于 TensorFlow。不论是 GitHub 的收藏量或 Fork 量,还是业界使用量都无可比拟地位列第一。

TensorFlow 的版本迭代
但是 TensorFlow 有一个令人诟病的劣势,即它和 Theano 一样采用的是静态计算图,这令神经网络的搭建和入门学习都变得更加困难。因此在 2017 年 1 月,Torch7 团队开源了 PyTorch,它的宗旨是尽可能令深度学习建模更加简单。
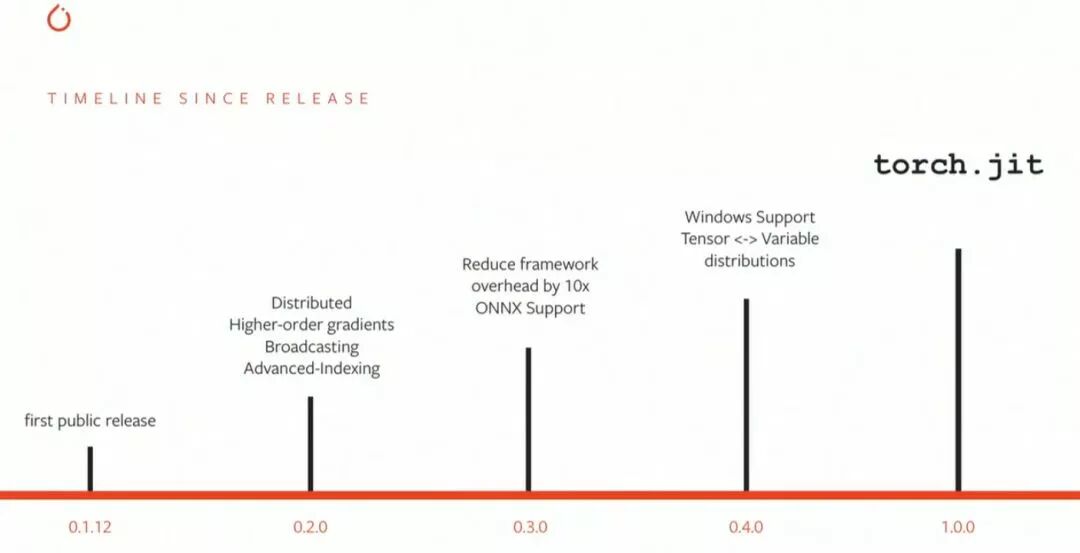
PyTorch 的版本迭代
其实数学君们在很多对比文章中都发现 TensorFlow 的使用在目前来说还是最为广泛的,但是 PyTorch 的发展势头非常迅猛,尤其是在学术研究领域的应用上。那么为什么新近开源的 PyTorch 会那么受欢迎呢,首先我们需要了解深度学习框架的关键点:
在后两项中,基本上 TensorFlow 和 PyTorch 都能实现高效的自动微分机制和并行运算机制。但是在第一项中,PyTorch 的哲学是解决当务之急,也就是说即时构建和运行计算图,这与 TensorFLow 先建立静态计算图再发生实际运算相比要简单地多。因此在第一项上,PyTorch 具备很大优势,但是 TensorFlow 的静态计算图更有利于部署模型,且现在同样也非常关注动态计算图。
工业化的缺陷
PyTorch 最开始发布以来,大家都偏向于使用它做学术研究,而不是用于实际生产。主要的原因可能有两点:首先它比较新,还不太成熟,因此很多 API 接口和结构也都不太稳定;其次是动态计算图在部署上不太方便,而像 TensorFlow 这样的静态图可以在不同的环境下调用计算图和对应参数,因此很容易部署到各种产品中。
由于 PyTorch 与 Python 有着紧密的结合,因此将这种动态计算图部署到其它产品会比较困难。不论是训练脚本还是预训练模型,我们经常需要将研究代码转换为 Caffe2 中的计算图表征,从而实现生产规模上的高效使用。其中 Caffe2 项目是两年前提出的,其目的是标准化 AI 模型的生产工具,目前该框架在 Facebook 服务器以及超过 10 亿台手机上运行,横跨了八代 iPhone 和六代安卓 CPU 架构。
之前,从 PyTorch 到 Caffe2 的迁移过程是手动的,耗时间且容易出错。为了解决这个问题,Facebook 与主要的硬件和软件公司合作创建了 ONNX(开放神经网络交换格式),这是一种用于表示深度学习模型的开放格式。通过 ONNX,开发者能在不同的框架间共享模型,例如我们可以导出由 PyTorch 构建的模型,并将它们导入到 Caffe2。
通过 ONNX 和 Caffe2,使用 PyTorch 构建的研究结果可以快速地转化到生产中。而且昨日发布的 PyTorch 1.0 预览版也标志着 PyTorch 开始走向成熟,很多 API 接口和框架结构也都会变得更加稳定,这些都非常有利于将 PyTorch 应用于实际生产中。
性能对比
这两种深度学习框架都有各自的特点,那么它们在相同硬件(GPU)上运行相同神经网络的性能又怎么样?Ilia Karmanov 在 GitHub 上开源了一项测试,他在相同的环境下测试由不同框架编写的相同模型,并借此讨论不同框架的性能。从这些数据中,我们可以了解到在性能上,TensorFlow 和 PyTorch 并不会有显著的差别,不过在特定的任务上还是有一些不同。
项目地址:https://github.com/ilkarman/DeepLearningFrameworks
以下展示了使用 VGG 在 CIFAR-10 上实现图像分类的速度:
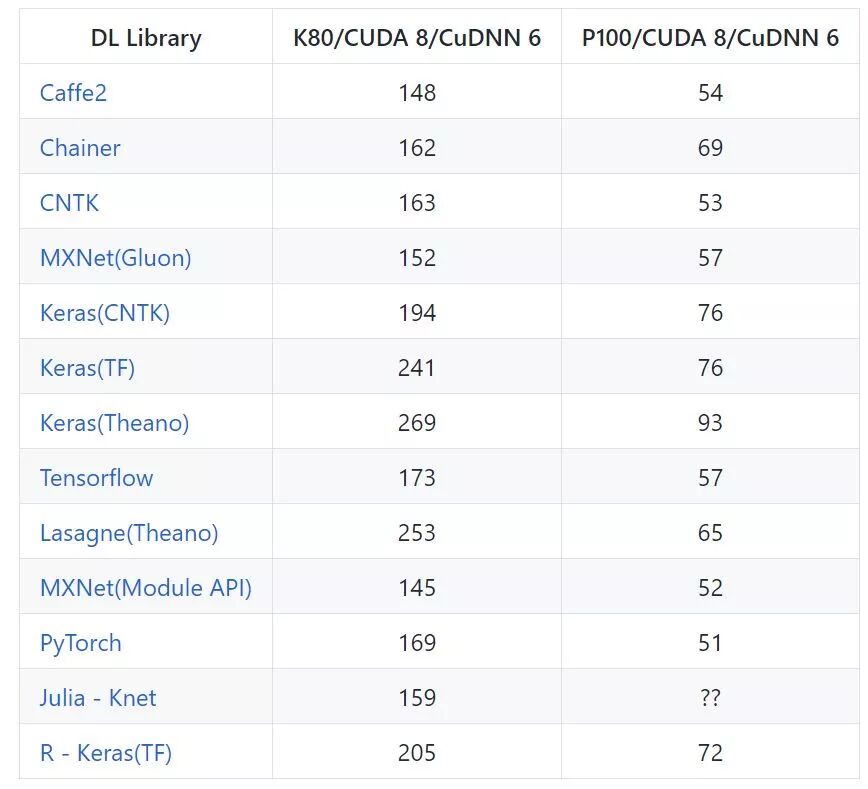
以下展示了 DenseNet-121 在 ChestXRay 数据集上的训练速度,在这个图像识别任务中,PyTorch 要比 TensorFlow 表现得更好一些:
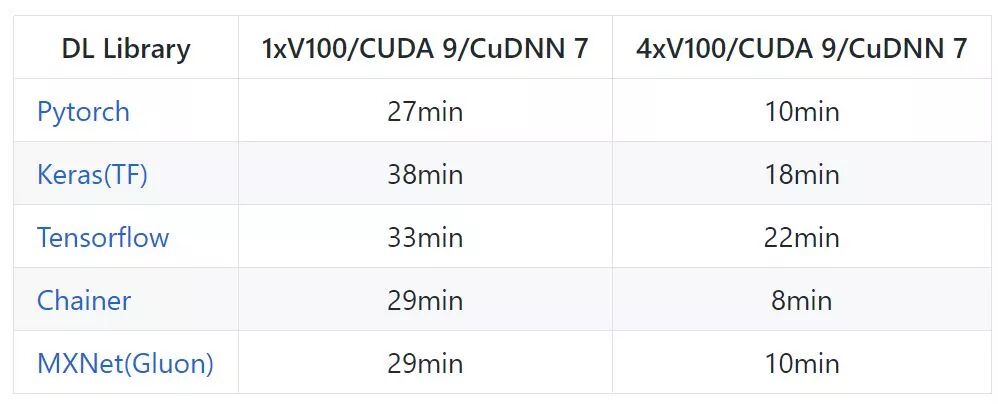
如下展示了在 IMDB 数据集上训练门控循环单元(GRU)的速度,它们实现的是情感分析任务。对于循环神经网络,PyTorch 和 TensorFlow 的性能差不多,不过 PyTorch 在 P100 芯片上普遍表现得比 TensorFlow 好。
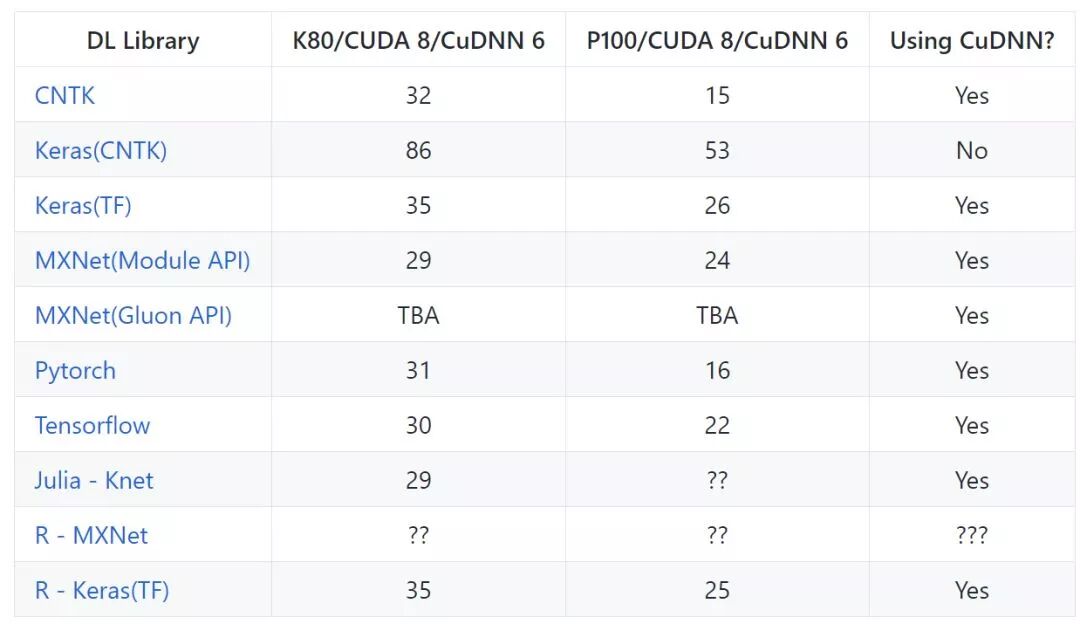
该项目还有更多的对比与分析,感兴趣的读者可查看原 GitHub 项目。
2017年1月,Facebook人工智能研究院(FAIR)团队在GitHub上开源了PyTorch,并迅速占领GitHub热度榜榜首。
作为一个2017年才发布,具有先进设计理念的框架,PyTorch的历史可追溯到2002年就诞生于纽约大学的Torch。Torch使用了一种不是很大众的语言Lua作为接口。Lua简洁高效,但由于其过于小众,用的人不是很多,以至于很多人听说要掌握Torch必须新学一门语言就望而却步(其实Lua是一门比Python还简单的语言)。

考虑到Python在计算科学领域的领先地位,以及其生态完整性和接口易用性,几乎任何框架都不可避免地要提供Python接口。终于,在2017年,Torch的幕后团队推出了PyTorch。PyTorch不是简单地封装Lua Torch提供Python接口,而是对Tensor之上的所有模块进行了重构,并新增了最先进的自动求导系统,成为当下最流行的动态图框架。
PyTorch一经推出就立刻引起了广泛关注,并迅速在研究领域流行起来。图1所示为Google指数,PyTorch自发布起关注度就在不断上升,截至2017年10月18日,PyTorch的热度已然超越了其他三个框架(Caffe、MXNet和Theano),并且其热度还在持续上升中。
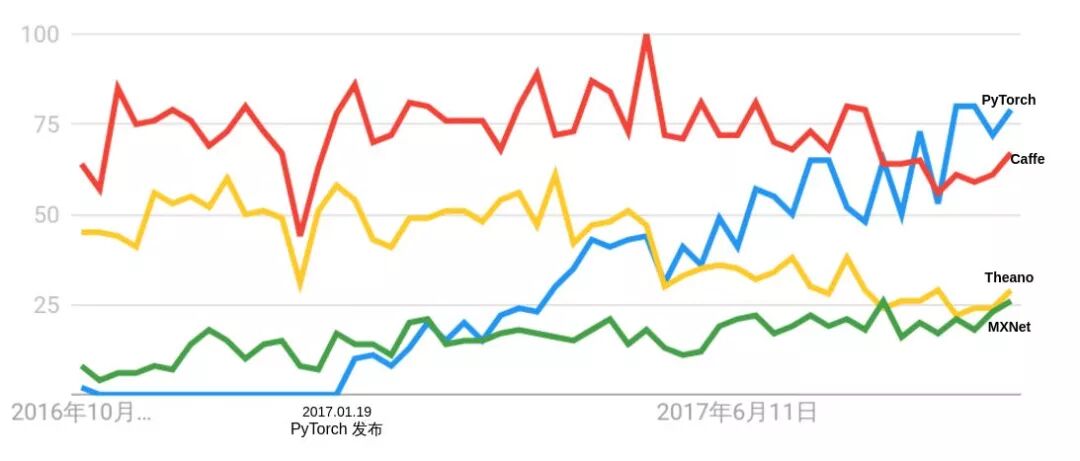
图 1 PyTorch 和 Caffe、Theano、MXNet 的 Google 指数对比(类别为科学)
随着深度学习的发展,深度学习框架如雨后春笋般诞生于高校和公司中。尤其是近两年,Google、Facebook、Microsoft等巨头都围绕深度学习重点投资了一系列新兴项目,他们也一直在支持一些开源的深度学习框架。
目前研究人员正在使用的深度学习框架不尽相同,有 TensorFlow 、Caffe、Theano、Keras等,常见的深度学习框架如图2所示。这些深度学习框架被应用于计算机视觉、语音识别、自然语言处理与生物信息学等领域,并获取了极好的效果。本部分主要介绍当前深度学习领域影响力比较大的几个框架,限于笔者个人使用经验和了解程度,对各个框架的评价可能有不准确的地方。

图 2 常见的深度学习框架
1 . Theano
Theano最初诞生于蒙特利尔大学 LISA 实验室,于2008年开始开发,是第一个有较大影响力的Python深度学习框架。
Theano 是一个 Python 库,可用于定义、优化和计算数学表达式,特别是多维数组(numpy.ndarray)。在解决包含大量数据的问题时,使用 Theano 编程可实现比手写 C 语言更快的速度,而通过 GPU 加速,Theano 甚至可以比基于 CPU 计算的 C 语言快上好几个数量级。Theano 结合了计算机代数系统(Computer Algebra System,CAS)和优化编译器,还可以为多种数学运算生成定制的 C 语言代码。对于包含重复计算的复杂数学表达式的任务而言,计算速度很重要,因此这种 CAS 和优化编译器的组合是很有用的。对需要将每一种不同的数学表达式都计算一遍的情况,Theano 可以最小化编译/解析的计算量,但仍然会给出如自动微分那样的符号特征。
Theano诞生于研究机构,服务于研究人员,其设计具有较浓厚的学术气息,但在工程设计上有较大的缺陷。一直以来,Theano因难调试、构建图慢等缺点为人所诟病。为了加速深度学习研究,人们在它的基础之上,开发了Lasagne、Blocks、PyLearn2和Keras等第三方框架,这些框架以Theano为基础,提供了更好的封装接口以方便用户使用。
2017年9月28日,在Theano 1.0正式版即将发布前夕,LISA实验室负责人,深度学习三巨头之一的Yoshua Bengio 宣布Theano即将停止开发:“Theano is Dead”。尽管Theano即将退出历史舞台,但作为第一个Python深度学习框架,它很好地完成了自己的使命,为深度学习研究人员的早期拓荒提供了极大的帮助,同时也为之后深度学习框架的开发奠定了基本设计方向: 以计算图为框架的核心,采用GPU加速计算。
2017年11月,LISA实验室在 GitHub 上开启了一个初学者入门项目,旨在帮助实验室新生快速掌握机器学习相关的实践基础,而该项目正是使用PyTorch作为教学框架。
点评:由于Theano已经停止开发,不建议作为研究工具继续学习。
2 TensorFlow
2015年11月10日,Google宣布推出全新的机器学习开源工具TensorFlow。 TensorFlow 最初是由 Google 机器智能研究部门的 Google Brain 团队开发,基于Google 2011年开发的深度学习基础架构DistBelief构建起来的。TensorFlow主要用于进行机器学习和深度神经网络研究, 但它是一个非常基础的系统,因此也可以应用于众多领域。由于Google在深度学习领域的巨大影响力和强大的推广能力,TensorFlow一经推出就获得了极大的关注,并迅速成为如今用户最多的深度学习框架。
TensorFlow在很大程度上可以看作Theano的后继者,不仅因为它们有很大一批共同的开发者,而且它们还拥有相近的设计理念,都是基于计算图实现自动微分系统。TensorFlow 使用数据流图进行数值计算,图中的节点代表数学运算, 而图中的边则代表在这些节点之间传递的多维数组(张量)。
TensorFlow编程接口支持Python和C++。随着1.0版本的公布,Java、Go、R和Haskell API的alpha版本也被支持。此外,TensorFlow还可在Google Cloud和AWS中运行。TensorFlow还支持 Windows 7、Windows 10和Windows Server 2016。由于TensorFlow使用C++ Eigen库,所以库可在ARM架构上编译和优化。这也就意味着用户可以在各种服务器和移动设备上部署自己的训练模型,无须执行单独的模型解码器或者加载Python解释器。
作为当前最流行的深度学习框架,TensorFlow获得了极大的成功,对它的批评也不绝于耳,总结起来主要有以下四点。
过于复杂的系统设计,TensorFlow 在GitHub代码仓库的总代码量超过100万行。这么大的代码仓库,对于项目维护者来说维护成为了一个难以完成的任务,而对读者来说,学习TensorFlow底层运行机制更是一个极其痛苦的过程,并且大多数时候这种尝试以放弃告终。
频繁变动的接口。TensorFlow的接口一直处于快速迭代之中,并且没有很好地考虑向后兼容性,这导致现在许多开源代码已经无法在新版的TensorFlow上运行,同时也间接导致了许多基于TensorFlow的第三方框架出现BUG。
接口设计过于晦涩难懂。在设计TensorFlow时,创造了图、会话、命名空间、PlaceHolder等诸多抽象概念,对普通用户来说难以理解。同一个功能,TensorFlow提供了多种实现,这些实现良莠不齐,使用中还有细微的区别,很容易将用户带入坑中。
文档混乱脱节。TensorFlow作为一个复杂的系统,文档和教程众多,但缺乏明显的条理和层次,虽然查找很方便,但用户却很难找到一个真正循序渐进的入门教程。
由于直接使用TensorFlow的生产力过于低下,包括Google官方等众多开发者尝试基于TensorFlow构建一个更易用的接口,包括Keras、Sonnet、TFLearn、TensorLayer、Slim、Fold、PrettyLayer等数不胜数的第三方框架每隔几个月就会在新闻中出现一次,但是又大多归于沉寂,至今TensorFlow仍没有一个统一易用的接口。
凭借Google着强大的推广能力,TensorFlow已经成为当今最炙手可热的深度学习框架,但是由于自身的缺陷,TensorFlow离最初的设计目标还很遥远。另外,由于Google对TensorFlow略显严格的把控,目前各大公司都在开发自己的深度学习框架。
点评:不完美但最流行的深度学习框架,社区强大,适合生产环境。
3 . Keras
Keras是一个高层神经网络API,由纯Python编写而成并使用TensorFlow、Theano及CNTK作为后端。Keras为支持快速实验而生,能够把想法迅速转换为结果。Keras应该是深度学习框架之中最容易上手的一个,它提供了一致而简洁的API, 能够极大地减少一般应用下用户的工作量,避免用户重复造轮子。
严格意义上讲,Keras并不能称为一个深度学习框架,它更像一个深度学习接口,它构建于第三方框架之上。Keras的缺点很明显:过度封装导致丧失灵活性。Keras最初作为Theano的高级API而诞生,后来增加了TensorFlow和CNTK作为后端。为了屏蔽后端的差异性,提供一致的用户接口,Keras做了层层封装,导致用户在新增操作或是获取底层的数据信息时过于困难。同时,过度封装也使得Keras的程序过于缓慢,许多BUG都隐藏于封装之中,在绝大多数场景下,Keras是本文介绍的所有框架中最慢的一个。
学习Keras十分容易,但是很快就会遇到瓶颈,因为它缺少灵活性。另外,在使用Keras的大多数时间里,用户主要是在调用接口,很难真正学习到深度学习的内容。
点评:入门最简单,但是不够灵活,使用受限。
4 . Caffe/Caffe2
Caffe的全称是Convolutional Architecture for Fast Feature Embedding,它是一个清晰、高效的深度学习框架,核心语言是C++,它支持命令行、Python和MATLAB接口,既可以在CPU上运行,也可以在GPU上运行。
Caffe的优点是简洁快速,缺点是缺少灵活性。不同于Keras因为太多的封装导致灵活性丧失,Caffe灵活性的缺失主要是因为它的设计。在Caffe中最主要的抽象对象是层,每实现一个新的层,必须要利用C++实现它的前向传播和反向传播代码,而如果想要新层运行在GPU上,还需要同时利用CUDA实现这一层的前向传播和反向传播。这种限制使得不熟悉C++和CUDA的用户扩展Caffe十分困难。
Caffe凭借其易用性、简洁明了的源码、出众的性能和快速的原型设计获取了众多用户,曾经占据深度学习领域的半壁江山。但是在深度学习新时代到来之时,Caffe已经表现出明显的力不从心,诸多问题逐渐显现(包括灵活性缺失、扩展难、依赖众多环境难以配置、应用局限等)。尽管现在在GitHub上还能找到许多基于Caffe的项目,但是新的项目已经越来越少。
Caffe的作者从加州大学伯克利分校毕业后加入了Google,参与过TensorFlow的开发,后来离开Google加入FAIR,担任工程主管,并开发了Caffe2。Caffe2是一个兼具表现力、速度和模块性的开源深度学习框架。它沿袭了大量的 Caffe 设计,可解决多年来在 Caffe 的使用和部署中发现的瓶颈问题。Caffe2的设计追求轻量级,在保有扩展性和高性能的同时,Caffe2 也强调了便携性。Caffe2 从一开始就以性能、扩展、移动端部署作为主要设计目标。Caffe2 的核心 C++ 库能提供速度和便携性,而其 Python 和 C++ API 使用户可以轻松地在 Linux、Windows、iOS、Android ,甚至 Raspberry Pi 和 NVIDIA Tegra 上进行原型设计、训练和部署。
Caffe2继承了Caffe的优点,在速度上令人印象深刻。Facebook 人工智能实验室与应用机器学习团队合作,利用Caffe2大幅加速机器视觉任务的模型训练过程,仅需 1 小时就训练完ImageNet 这样超大规模的数据集。然而尽管已经发布半年多,开发一年多,Caffe2仍然是一个不太成熟的框架,官网至今没提供完整的文档,安装也比较麻烦,编译过程时常出现异常,在GitHub上也很少找到相应的代码。
极盛的时候,Caffe占据了计算机视觉研究领域的半壁江山,虽然如今Caffe已经很少用于学术界,但是仍有不少计算机视觉相关的论文使用Caffe。由于其稳定、出众的性能,不少公司还在使用Caffe部署模型。Caffe2尽管做了许多改进,但是还远没有达到替代Caffe的地步。
点评:文档不够完善,但性能优异,几乎全平台支持(Caffe2),适合生产环境。
5 . MXNet
MXNet是一个深度学习库,支持C++、Python、R、Scala、Julia、MATLAB及JavaScript等语言;支持命令和符号编程;可以运行在CPU、GPU、集群、服务器、台式机或者移动设备上。MXNet是CXXNet的下一代,CXXNet借鉴了Caffe的思想,但是在实现上更干净。在2014 年的NIPS 上,同为上海交大校友的陈天奇与李沐碰头,讨论到各自在做深度学习 Toolkits 的项目组,发现大家普遍在做很多重复性的工作,例如文件 loading 等。于是他们决定组建 DMLC【Distributied (Deep) Machine Learning Community】,号召大家一起合作开发 MXNet,发挥各自的特长,避免重复造轮子。
MXNet以其超强的分布式支持,明显的内存、显存优化为人所称道。同样的模型,MXNet往往占用更小的内存和显存,并且在分布式环境下,MXNet展现出了明显优于其他框架的扩展性能。
由于MXNet最初由一群学生开发,缺乏商业应用,极大地限制了MXNet的使用。2016年11月,MXNet被AWS正式选择为其云计算的官方深度学习平台。2017年1月,MXNet项目进入Apache基金会,成为Apache的孵化器项目。
尽管MXNet拥有最多的接口,也获得了不少人的支持,但其始终处于一种不温不火的状态。个人认为这在很大程度上归结于推广不给力及接口文档不够完善。MXNet长期处于快速迭代的过程,其文档却长时间未更新,导致新手用户难以掌握MXNet,老用户常常需要查阅源码才能真正理解MXNet接口的用法。
为了完善MXNet的生态圈,推广MXNet,MXNet先后推出了包括MinPy、Keras和Gluon等诸多接口,但前两个接口目前基本停止了开发,Gluon模仿PyTorch的接口设计,MXNet的作者李沐更是亲自上阵,在线讲授如何从零开始利用Gluon学习深度学习,诚意满满,吸引了许多新用户。
点评:文档略混乱,但分布式性能强大,语言支持最多,适合AWS云平台使用。
6 . CNTK
2015年8月,微软公司在CodePlex上宣布由微软研究院开发的计算网络工具集CNTK将开源。5个月后,2016年1月25日,微软公司在他们的GitHub仓库上正式开源了CNTK。早在2014年,在微软公司内部,黄学东博士和他的团队正在对计算机能够理解语音的能力进行改进,但当时使用的工具显然拖慢了他们的进度。于是,一组由志愿者组成的开发团队构想设计了他们自己的解决方案,最终诞生了CNTK。
根据微软开发者的描述,CNTK的性能比Caffe、Theano、TensoFlow等主流工具都要强。CNTK支持CPU和GPU模式,和TensorFlow/Theano一样,它把神经网络描述成一个计算图的结构,叶子节点代表输入或者网络参数,其他节点代表计算步骤。CNTK 是一个非常强大的命令行系统,可以创建神经网络预测系统。CNTK 最初是出于在 Microsoft 内部使用的目的而开发的,一开始甚至没有Python接口,而是使用了一种几乎没什么人用的语言开发的,而且文档有些晦涩难懂,推广不是很给力,导致现在用户比较少。但就框架本身的质量而言,CNTK表现得比较均衡,没有明显的短板,并且在语音领域效果比较突出。
点评:社区不够活跃,但是性能突出,擅长语音方面的相关研究。
7 . 其他框架
除了上述的几个框架,还有不少的框架,都有一定的影响力和用户。比如百度开源的PaddlePaddle,CMU开发的DyNet,简洁无依赖符合C++11标准的tiny-dnn,使用Java开发并且文档极其优秀的Deeplearning4J,还有英特尔开源的Nervana,Amazon开源的DSSTNE。这些框架各有优缺点,但是大多流行度和关注度不够,或者局限于一定的领域。此外,还有许多专门针对移动设备开发的框架,如CoreML、MDL,这些框架纯粹为部署而诞生,不具有通用性,也不适合作为研究工具。
这么多深度学习框架,为什么选择PyTorch呢?
因为PyTorch是当前难得的简洁优雅且高效快速的框架。在笔者眼里,PyTorch达到目前深度学习框架的最高水平。当前开源的框架中,没有哪一个框架能够在灵活性、易用性、速度这三个方面有两个能同时超过PyTorch。下面是许多研究人员选择PyTorch的原因。
① 简洁:PyTorch的设计追求最少的封装,尽量避免重复造轮子。不像TensorFlow中充斥着session、graph、operation、name_scope、variable、tensor、layer等全新的概念,PyTorch的设计遵循tensor→variable(autograd)→nn.Module 三个由低到高的抽象层次,分别代表高维数组(张量)、自动求导(变量)和神经网络(层/模块),而且这三个抽象之间联系紧密,可以同时进行修改和操作。
简洁的设计带来的另外一个好处就是代码易于理解。PyTorch的源码只有TensorFlow的十分之一左右,更少的抽象、更直观的设计使得PyTorch的源码十分易于阅读。在笔者眼里,PyTorch的源码甚至比许多框架的文档更容易理解。
② 速度:PyTorch的灵活性不以速度为代价,在许多评测中,PyTorch的速度表现胜过TensorFlow和Keras等框架 。框架的运行速度和程序员的编码水平有极大关系,但同样的算法,使用PyTorch实现的那个更有可能快过用其他框架实现的。
③易用:PyTorch是所有的框架中面向对象设计的最优雅的一个。PyTorch的面向对象的接口设计来源于Torch,而Torch的接口设计以灵活易用而著称,Keras作者最初就是受Torch的启发才开发了Keras。PyTorch继承了Torch的衣钵,尤其是API的设计和模块的接口都与Torch高度一致。PyTorch的设计最符合人们的思维,它让用户尽可能地专注于实现自己的想法,即所思即所得,不需要考虑太多关于框架本身的束缚。
④活跃的社区:
PyTorch提供了完整的文档,循序渐进的指南,作者亲自维护的论坛 供用户交流和求教问题。Facebook 人工智能研究院对PyTorch提供了强力支持,作为当今排名前三的深度学习研究机构,FAIR的支持足以确保PyTorch获得持续的开发更新,不至于像许多由个人开发的框架那样昙花一现。
在PyTorch推出不到一年的时间内,各类深度学习问题都有利用PyTorch实现的解决方案在GitHub上开源。同时也有许多新发表的论文采用PyTorch作为论文实现的工具,PyTorch正在受到越来越多人的追捧 。
如果说 TensorFlow的设计是“Make It Complicated”,Keras的设计是“Make It Complicated And Hide It”,那么PyTorch的设计真正做到了“Keep it Simple,Stupid”。简洁即是美。
使用TensorFlow能找到很多别人的代码,使用PyTorch能轻松实现自己的想法。

本文选自《深度学习框架PyTorch:入门与实践》

AI君墙裂推荐大家继续阅读另外一篇文章
《PyTorch为何如此高效好用?来探寻深度学习框架的内部架构》

作为 Facebook 人工智能团队(FAIR)提供支持的深度学习框架,PyTorch 自 2017 年 1 月推出以来立即成为了一种流行开发工具。其在调试、编译等方面的优势使其受到了学界研究者们的普遍欢迎。本文中,来自蒙特利尔综合理工学院的研究员 Christian S. Perone 将为我们介绍这种神经网络框架的内部架构,揭开 PyTorch 方便好用的真正原因。
前言
本文主要介绍了 PyTorch 代码库,旨在为 PyTorch 及其内部架构设计提供指导,核心目标是为那些想了解 API 知识之外的人提供有益的帮助,并给出之前教程所没有的新内容。注意:PyTorch 构建系统需要大量使用代码设置,因此其他人的描述我将不再重复。如果你感兴趣,请参考原文提供的扩展资料。
C/C++中 Python 扩展对象的简介
你可能知道可以借助 C/C++扩展 Python,并开发所谓的「扩展」。PyTorch 的所有繁重工作由 C/C++实现,而不是纯 Python。为了定义 C/C++中一个新的 Python 对象类型,你需要定义如下实例的一个类似结构:
// Python object that backs torch.autograd.Variable
struct THPVariable {
PyObject_HEAD
torch::autograd::Variable cdata;
PyObject* backward_hooks;
};
如上,在定义的开始有一个称之为 PyObject_HEAD 的宏,其目标是标准化 Python 对象,并扩展至另一个结构,该结构包含一个指向类型对象的指针,以及一个带有引用计数的字段。

Python API 中有两个额外的宏,分别称为 Py_INCREF() 和 Py_DECREF(),可用于增加和减少 Python 对象的引用计数。多实体可以借用或拥有其他对象的引用(因此引用计数被增加),而只有当引用计数达到零,Python 才会自动删除那个对象的内存。想了解更多有关 Python C/++扩展的知识,请参见:https://docs.python.org/3/extending/newtypes.html。
有趣的事实:使用小的整数作为索引、计数等在很多应用中非常见。为了提高效率,官方 CPython 解释器缓存从-5 到 256 的整数。正由于此,声明 a = 200; b = 200; a is b 为真,而声明 a = 300; b = 300; a is b 为假。
Zero-copy PyTorch 张量到 Numpy,反之亦然
PyTorch 有专属的张量表征,分离 PyTorch 的内部表征和外部表征。但是,由于 Numpy 数组的使用非常普遍,尤其是当数据加载源不同时,我们确实需要在 Numpy 和 PyTorch 张量之间做转换。正由于此,PyTorch 给出了两个方法(from_numpy() 和 numpy()),从而把 Numpy 数组转化为 PyTorch 数组,反之亦然。如果我们查看把 Numpy 数组转化为 PyTorch 张量的调用代码,就可以获得有关 PyTorch 内部表征的更多洞见:
at::Tensor tensor_from_numpy(PyObject* obj) {
if (!PyArray_Check(obj)) {
throw TypeError("expected np.ndarray (got %s)", Py_TYPE(obj)->tp_name);
}
auto
array = (PyArrayObject*)obj;
int ndim = PyArray_NDIM(array);
auto sizes = to_aten_shape(ndim, PyArray_DIMS(array));
auto strides = to_aten_shape(ndim, PyArray_STRIDES(array));
// NumPy strides use bytes. Torch strides use element counts.
auto element_size_in_bytes = PyArray_ITEMSIZE(array);
for (auto& stride : strides) {
stride /= element_size_in_bytes;
}
// (...) - omitted for brevity
void* data_ptr = PyArray_DATA(array);
auto& type = CPU(dtype_to_aten(PyArray_TYPE(array)));
Py_INCREF(obj);
return type.tensorFromBlob(data_ptr, sizes, strides, [obj](void* data) {
AutoGIL gil;
Py_DECREF(obj);
});
}
代码摘自(tensor_numpy.cpp:https://github.com/pytorch/pytorch/blob/master/torch/csrc/utils/tensor_numpy.cpp#L88)
正如你在这段代码中看到的,PyTorch 从 Numpy 表征中获取所有信息(数组元数据),并创建自己的张量。但是,正如你从被标注的第 18 行所看到的,PyTorch 保留一个指向内部 Numpy 数组原始数据的指针,而不是复制它。这意味着 PyTorch 将拥有这一数据,并与 Numpy 数组对象共享同一内存区域。
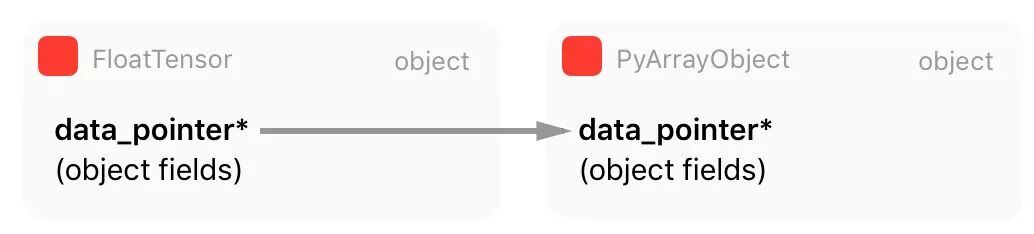
还有一点很重要:当 Numpy 数组对象越出范围并获得零引用(zero reference)计数,它将被当作垃圾回收并销毁,这就是为什么 Numpy 数组对象的引用计数在第 20 行有增加。该行之后,PyTorch 将从这一 Numpy 数据 blob 中创建一个新的张量对象,并且在创建这一新张量的过程中,PyTorch 将会传递内存数据指针,连同内存大小、步幅以及稍后张量存储将会使用的函数(我们将会在下节讨论),从而通过减少 Numpy 数组对象的引用计数并使 Python 关心这一对象内存管理而释放数据。
tensorFromBlob() 方法将创建一个新张量,但只有在为这一张量创建一个新「存储」之后。存储是指存储数据指针的地方,它并不在张量结构内部。张量存储正是我们下一节要讨论的内容。
张量存储
张量的实际原始数据并不是立即保存在张量结构中,而是保存在我们称之为「存储(Storage)」的地方,它是张量结构的一部分。
正如我们前面在 tensor_from_numpy() 中看到的代码,它调用了 tensorFromBlob() 函数以从原始数据 Blob 中创建一个张量。tensorFromBlob() 函数在内部会调用另一个名为 storageFromBlob() 函数,该函数主要根据类型为数据创建一个存储。例如在 CPU 浮点型的情况下,它会返回一个新的 CPUFloatStorage 实例。
CPUFloatStorage 基本上是包含 utility 函数的包装类(wrapper),且实际存储结构如下所示称为 THFloatStorage:
typedef struct THStorage
{
real *data;
ptrdiff_t size;
int refcount;
char flag;
THAllocator *allocator;
void *allocatorContext;
struct THStorage *view;
} THStorage;
如上所示,THStorage 有一个指向原始数据、原始数据大小、flags 和 allocator 的指针,我们会在后面详细地讨论它们。值得注意的是,THStorage 不包含如何解释内部数据的元数据,这是因为存储对保存的内容「无处理信息的能力」,只有张量才知道如何「查看」数据。
因此,你可能已经意识到多个张量可以指向相同的存储,而仅仅对数据采用不同的解析。这也就是为什么我们以不同的形状或维度,查看相同元素数量的张量会有很高的效率。下面的 Python 代码表明,在改变张量的形状后,存储中的数据指针将得到共享。
>>> tensor_a = torch.ones((3, 3))
>>> tensor_b = tensor_a.view(9)
>>> tensor_a.storage().data_ptr() == tensor_b.storage().data_ptr()
True
如 THFloatStorage 结构中的第七行代码所示,它有一个指向 THAllocator 结构的指针。它因为给分配器(allocator)带来灵活性而显得十分重要,其中 allocator 可以用来分配存储数据。
typedef struct THAllocator
{
void* (*malloc)(void*, ptrdiff_t);
void* (*realloc)(void*, void*, ptrdiff_t);
void (*free)(void*, void*);
} THAllocator;
代码摘自(THAllocator.h:https://github.com/pytorch/pytorch/blob/master/aten/src/TH/THAllocator.h#L16)
如上所述,该结构有三个函数指针字段来定义分配器的意义:malloc、realloc 和 free。对于分配给 CPU 的内存,这些函数当然与传统的 malloc/realloc/free POSIX 函数相关。然而当我们希望分配存储给 GPU,我们最终会使用如 cudaMallocHost() 那样的 CUDA 分配器,我们可以在下面的 THCudaHostAllocator malloc 函数中看到这一点。
static void *THCudaHostAllocator_malloc(void* ctx, ptrdiff_t size) {
void* ptr;
if (size < 0) THError("Invalid memory size: %ld", size);
if (size == 0) return NULL;
THCudaCheck(cudaMallocHost(&ptr, size));
return ptr;
}代码摘自(THCAllocator.c:https://github.com/pytorch/pytorch/blob/master/aten/src/THC/THCAllocator.c#L3)
如上所示,分配器调用了一个 cudaMallocHost() 函数。你可能已经注意到版本库组织中有缩写的表示模式,在浏览版本库时记住这些约定非常重要,它们在 PyTorch README 文件中有所总结:
该约定同样存在于函数/类别名和其它对象中,因此了解它们十分重要。你可以在 TH 代码中找到 CPU 分配器,在 THC 代码中找到 CUDA 分配器。最后,我们可以看到主张量 THTensor 结构的组成:
typedef struct
THTensor
{
int64_t *size;
int64_t *stride;
int nDimension;
THStorage *storage;
ptrdiff_t storageOffset;
int refcount;
char flag;
} THTensor;
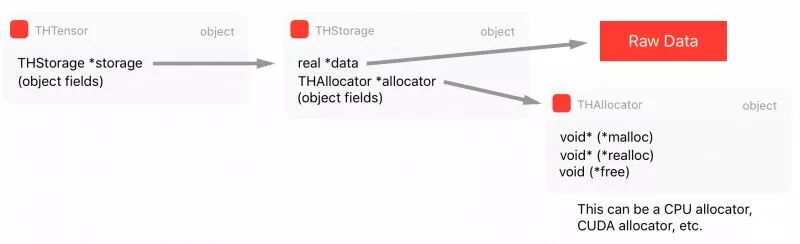
如上,THTensor 的主要结构为张量数据保留了 size/strides/dimensions/offsets/等,同时还有存储 THStorage。我们可以将所有这些结构总结为以下图表:
现在,如果我们有多重处理的需求,且希望在多个不同的进程中共享张量数据,那么我们需要一个共享内存的方法。否则每次另一个进程需要张量或我们希望实现 Hogwild 训练过程以将所有不同的进程写入相同的内存区域时,我们就需要在进程间创建副本,这是非常低效的。因此,我们将在下一节讨论共享内存的特定存储方法。
共享内存
共享内存可以用很多种不同的方法实现(依赖于支持的平台)。PyTorch 支持部分方法,但为了简单起见,我将讨论在 MacOS 上使用 CPU(而不是 GPU)的情况。由于 PyTorch 支持多种共享内存的方法,由于代码中包含很多级的间接性,这部分会有点困难。
PyTorch 为 Python multiprocessing 模块提供了一个封装器,可以从 torch.multiprocessing 导入。他们对该封装器中的实现做出了一些变动,以确保每当一个 Tensor 被放在队列上或和其它进程共享时,PyTorch 可以确保仅有一个句柄的共享内存会被共享,而不会共享 Tensor 的完整新副本。现在,很多人都不知道 PyTorch 中的 Tensor 方法是 share_memory_(),然而,该函数正好可以触发那个特定 Tensor 的保存内存的完整重建。该方法的执行过程是创建共享内存的一个区域,其可以在不同的进程中使用。最终,该函数可以调用以下的函数:
static THStorage* THPStorage_(newFilenameStorage)(ptrdiff_t size)
{
int flags = TH_ALLOCATOR_MAPPED_SHAREDMEM | TH_ALLOCATOR_MAPPED_EXCLUSIVE;
std
::string handle = THPStorage_(__newHandle)();
auto ctx = libshm_context_new(NULL, handle.c_str(), flags);
return THStorage_(newWithAllocator)(size, &THManagedSharedAllocator, (void*)ctx);
}
如上所示,该函数使用了一个特殊的分类器 THManagedSharedAllocator 来创建另一个存储。它首先定义了一些 flags,然后创建了一个格式为 /torch_ [process id] _ [random number] 的字符串句柄,最后在使用特殊的 THManagedSharedAllocator 创建新的存储。该分配器有一个指向 PyTorch 内部库 libshm 的函数指针,它将实现名为 Unix Domain Socket 的通信以共享特定 quyu 的内存句柄。这种分配器实际上是「smart allocator」的特例,因为它包含通信控制逻辑单元,并使用了另一个称之为 THRefcountedMapAllocator 的分配器,它将创建市级共享内存区域并调用 mmp() 以将该区域映射到进程虚拟地址空间。
现在我们可以通过手动交换共享内存句柄而将分配给另一个进程的张量分配给一个进程,如下为 Python 示例:
>>> import torch
>>> tensor_a = torch.ones((5, 5))
>>> tensor_a
1 1 1 1 1
1 1 1 1 1
1 1 1 1 1
1
1 1 1 1
1 1 1 1 1
[torch.FloatTensor of size 5x5]
>>> tensor_a.is_shared()
False
>>> tensor_a = tensor_a.share_memory_()
>>> tensor_a.is_shared()
True
>>> tensor_a_storage = tensor_a.storage()
>>> tensor_a_storage._share_filename_()
(b'/var/tmp/tmp.0.yowqlr', b'/torch_31258_1218748506', 25)
在这段代码中,执行进程 A,我们就创建了一个 5×5,被 1 所填充的张量。在此之后,我们将其共享,并打印 Unix Domain Socket 地址和句柄的元组。现在我们可以从另一个进程 B 中接入这一内存区域了:
进程 B 执行代码:
>>> import torch
>>> tensor_a = torch.Tensor()
>>> tuple_info = (b'/var/tmp/tmp.0.yowqlr', b'/torch_31258_1218748506', 25)
>>> storage = torch.Storage._new_shared_filename(*tuple_info)
>>> tensor_a = torch.Tensor(storage).view((5, 5))
1 1 1 1 1
1 1 1 1 1
1 1 1 1 1
1 1 1 1 1
1 1 1 1 1
[torch.FloatTensor of size 5x5]
如你所见,使用 Unix Domain Socket 地址和句柄的元组信息,我们可以接入另一个进程的张量存储内容。如果你在进程 B 改变张量,你会看到改动也会反映在进程 A 中,因为张量之间共享着同样的存储区域。
DLPack:深度学习框架 Babel 的希望
现在让我们来看看 PyTorch 代码库最新的一些内容——DLPack(https://github.com/dmlc/dlpack)。DLPack 是一个内存张量结构的开放标准,允许张量数据在框架之间交换。非常有趣的是,这种内存表示是标准化的——与大多数框架已经在使用的内存表示方法非常类似,这就允许我们可以在框架之间共享,且完全无需复制数据。鉴于目前我们还没有内部通信的工具,DLPack 是一个非常了不起的创造。
它无疑会帮助我们解决今天存在于 MXNet、PyTorch 等框架上「孤岛」一样的张量表示,并允许开发者在多个深度学习框架之间自由操作,享受标准化为框架带来的优势。
DLPack 的核心结构 DLTensor 非常简单,如下所示:
/*!
* \brief Plain C Tensor object, does not manage memory.
*/
typedef struct {
/*!
* \brief The opaque data pointer points to the allocated data.
* This will be CUDA device pointer or cl_mem handle in OpenCL.
* This pointer is always aligns to 256 bytes as in CUDA.
*/
void* data;
/*! \brief The device context of the tensor */
DLContext ctx;
/*! \brief Number of dimensions */
int ndim;
/*! \brief The data type of the pointer*/
DLDataType dtype;
/*! \brief The shape of the tensor */
int64_t* shape;
/*!
* \brief strides of the tensor,
* can be NULL, indicating tensor is compact.
*/
int64_t* strides;
/*! \brief The offset in bytes to the beginning pointer to data */
uint64_t byte_offset;
} DLTensor;
代码来自 https://github.com/dmlc/dlpack/blob/master/include/dlpack/dlpack.h
如你所见,这里有一个未加工数据的数据指针,以及形态/步幅/偏移/GPU 或 CPU,以及其他 DLTensor 指向的元信息。
这里还有一个被称为 DLManagedTensor 的受管理版本,其中框架可以提供一个环境,以及「删除」函数,后者可以从借用张量来通知其他框架不再需要资源。
在 PyTorch 中,如果你想要转换到 DLTensor 格式,或从 DLTensor 格式转换,你可以找到 C/C++的方法,甚至 Python 方法来做这件事:
import torch
from torch.utils import dlpack
t = torch.ones((5, 5))
dl = dlpack.to_dlpack(t)
这个 Python 函数会从 ATen 调用 toDLPack 函数,如下所示:
DLManagedTensor* toDLPack(const Tensor& src) {
ATenDLMTensor * atDLMTensor(new ATenDLMTensor);
atDLMTensor->handle = src;
atDLMTensor->tensor.manager_ctx = atDLMTensor;
atDLMTensor->tensor.deleter = &deleter;
atDLMTensor->tensor.dl_tensor.data = src.data_ptr();
int64_t device_id = 0;
if (src.type().is_cuda()) {
device_id = src.get_device();
}
atDLMTensor->tensor.dl_tensor.ctx = getDLContext(src.type(), device_id);
atDLMTensor->tensor.dl_tensor.ndim = src.dim();
atDLMTensor->tensor.dl_tensor.dtype = getDLDataType(src.type());
atDLMTensor->tensor.dl_tensor.shape = const_cast<int64_t*>(src.sizes().data());
atDLMTensor->tensor.dl_tensor.strides = const_cast<int64_t*>(src.strides().data());
atDLMTensor->tensor.dl_tensor.byte_offset = 0;
return &(atDLMTensor->tensor);
}
如上所示,这是一个非常简单的转换,它可以将元数据的 PyTorch 格式转换为 DLPack 格式,并将指针指向内部张量的数据表示。
我们都希望更多的深度学习框架可以学习这种标准,这会让整个生态系统受益。希望本文能够对你有所帮助。
原文链接:http://blog.christianperone.com/2018/03/pytorch-internal-architecture-tour/
想要了解更多资讯,请扫描下方二维码,关注机器学习研究会

转自: 数学与人工智能










