
Instagram 是世界上最大的 Python 应用环境之一, 在这里,Python被用来实现服务于8亿活跃用户的“业务逻辑”。我们使用Python的参考实现——CPython——作为我们代码的运行环境。随着我们的发展,越来越多的服务器设备需求成为了我们基础设施开支的重要部分。这些设备都是计算密集型的,因此我们着重关注我们编写和部署的代码的效率,并且着力于构建用于检测和诊断性能瓶颈的工具。这些工具工作得很好,然而我们web层的预计增长使我们开始从运行环境中去审查我们效率低下的根源。
起步
为了确定我们需要优化的目标和应该使用的技术,我们必须确定以下两点:
我们从收集CPython在执行Instagram服务器代码时产生的各种数据开始。不出意外,从解释器的角度看,Instagram的负载是一个面向对象的网络服务器负载:
90%的解释器命令是在进行操作数栈的操作、控制流和属性获取。
我们的负载不是循环性的——94%的循环在经历四次以下的迭代之后就终止了。
函数调用的花销非常高,大约占解释器时间花销的30%。
属性获取是其次的资源密集性操作,大约占用了解释器时间花销的28%。这些属性负载通常不是多态的,其中85%的负载发生在单态。
基于以上数据,我们决定将工作重心放在降低函数调用和属性获取的计算开销上。
数据收集方法
通过监测运行在我们实验室环境(InstaLab)上的解释器,我们收集了所有我们需要的数据。InstaLab将来自前五视图中的请求混合(通过CPU指令),复现了生产环境的网络情况,并将其应用于一台隔离的web服务器。这一方法帮助我们得以在不影响用户体验的前提下,收集具有代表性的性能数据。对每一个不同的数据集,我们对CPython进行测量,搭建新的解释器,并从InstaLab中收集相关数据。
字节码频率分布
从解释器的角度来看,Instagram就是一串待执行的字节码指令序列。作为了解解释器行为的第一步,我们统计了CPython的字节码执行频率。下图是执行频率排名前十的字节码:
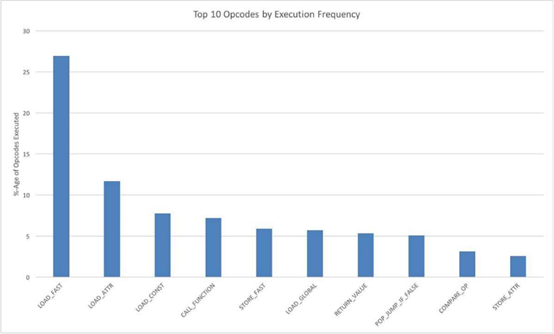
如图所示,我们可以看到LOAD_FAST指令占据主导位置。事实上,LOAD_FAST, STORE_FAST和LOAD_CONST大约占据了所有执行的指令码的40%。这和预期是一样的——CPython是一个堆栈机器,每一个指令都是在对操作数栈进行入栈和出栈操作。尽管这些命令十分简单,但是它们执行得十分频繁,并且产生了内存操作。因此,有效的优化技术应该要尽量避免load和store操作(比如转换为基于寄存器的字节码操作)。
排除上面的操作码后,我们可以更好地理解解释器在执行Instagram代码时所做的“实际工作”。下图显示了剩余的前20个操作码(总共120个)的执行频率分布:
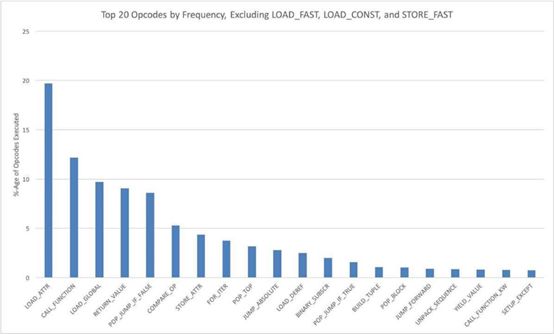
这些指令占剩余开销的90%。我们把它们大体分为以下几类:
属性获取——LOAD_ATTR, STORE_ATTR, LOAD_GLOBAL
控制流——CALL_FUNCTION, RETURN_ VALUE, POP JUMP IF FALSE, COMPARE_OP, FOR_ITER, JUMP ABSOLUTE, POP JUMP IF_ TRUE, POP BLOCK, JUMP FORWARD, YIELD_ VALUE, CALL_FUNCTION_KW, SETUP_EXCEPT
容器操作——BINARY_SUBSCR, BUILD_TUPLE, UNPACK_SEQUENCE
操作数栈操作——POP_TOP, LOAD_DEREF
这与我们所预期的,面向对象的web服务器的负载相一致(与数值计算负载相对)。
执行字节码的时间花费
字节码的执行频率只告诉了我们一半的故事。为了进一步了解解释器所做的工作,我们还希望知道解释器将时间花在了哪里。为了这一目的,我们使用pref_event APIs 测量了执行每一个操作码时,经过退出阶段(retire)的CPU指令数量。我们在解释器循环调度中将每个操作码的主体括起来,分别读取硬件指令计数器,然后将这两个值相减,以计算执行操作码所花费的“时间”。对于回调到解释器或回调到C函数(例如,CALL_FUNCTION操作码族)的情况,我们从操作码的开销中扣除被调用者花费的“时间”量。
下图显示了累计退出CPU指令占比前10的操作码:
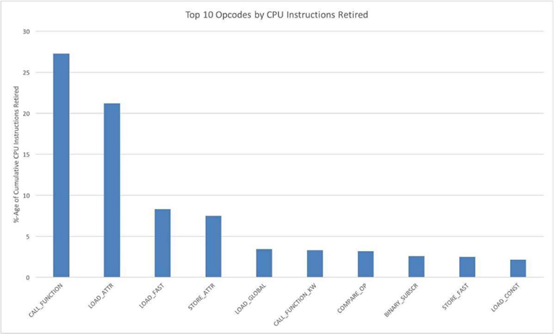
这些数据与之前的数据告诉我们的有所不同,函数调用和属性加载跳到了花销分布的前列。从“时间花销”的角度,最资源密集的操作码分类如下:
控制流-CALL_FUNCTION, CALL_FUNCTION_KW, COMPARE_OP
属性读取-LOAD_ATTR, STORE_ATTR, LOAD_GLOBAL
操作数栈操作-LOAD_FAST, STORE_FAST,LOAD_CONST
基于以上的数据,我们决定将时间花销优化的第一步放在优化属性获取和降低函数调用花销上。
加速属性获取
一个加速动态语言环境中属性获取和方法调度的经典技术是多态内联缓存。内联缓存与密集属性存储(使用类似隐藏类的方法)相结合,可以显着加快属性查找速度。 不过,它们的效果取决于调用位置的多态性程度。
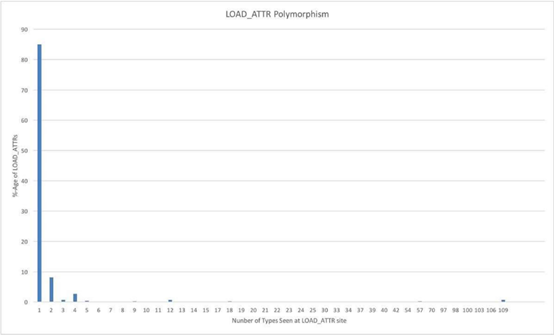
我们通过测量CPython,记录了每次LOAD_ATTR执行时的类型数量,以此来精确计算内联缓存的潜力。下图显示了LOAD_ATTR操作时的多态性程度分布:
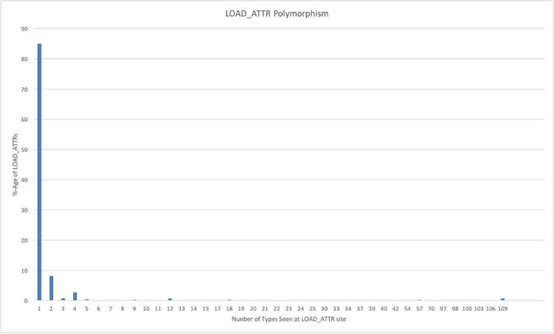
基于以上数据,可以看到内联缓存似乎是一个加速属性获取十分有效的技术。大约85%的LOAD_ATTR指令发生在单态场景中,大小为4的内联缓存足以应对大约96%的属性加载操作。
负载循环程度
最后一个我们希望回答的问题是“我们的代码循环程度有多高?”。回答这一问题有助于我们确定那些降低循环负载的技术能够在多大程度上为我们的任务加速。
我们通过测量CPython记录了每一次循环中的迭代次数。下图展示了循环迭代次数的分布:
如图所示,我们的工作负载循环程度并不高。事实上,大约94%的循环经历了四次以下的迭代就终止了。
结论
根据这些测试,我们确定了CPython中导致我们工作负载效率低下的两个主要根源:函数调用花销和属性获取需求。我们收集到的数据显示,一些众所周知的技术能够有效缓解这种效率低下。下一步,我们将会使用这些信息来指导我们努力优化CPython。
Matt Page是Instagram效率与可靠性团队的一位软件工程师
英文原文:https://ogmcsrgk5.qnssl.com/vcdn/1/优质文章长图2/Instagram调试CPython.pdf
译者:九天揽月







