
本期作者:Eric Brown
本期编辑:Allen | 崙
Prophet是Facebook 开源一款基于 Python 和 R 语言的数据预测工具。Facebook 表示,Prophet 相比现有预测工具更加人性化,并且难得地提供 Python 和R的支持。它生成的预测结果足以和专业数据分析师媲美。
另外,Prophet中文翻译过来为:
先知
一看就与众不同,你懂的!
推荐干货:2018第三季度最受欢迎的券商金工研报前50
安装说明可以在这里找到:
https://facebook.github.io/prophet/

使用Prophet是非常简单的。导入模块,将一些数据加载到Dataframe中,然后将数据设置为正确的格式,就可以开始建模或者预测了。
1、导入模块:
from fbprophet import Prophet
import numpy as np
import pandas as pd
2、加载数据:
sales_df = pd.read_csv('../examples/retail_sales.csv')
注意Dataframe的格式。需要有一个包含datetime字段的'ds'列和一个包含我们想要建模/预测的值的'y'列。
在我们对这些数据进行分析之前,我们需要对y变量进行log变换,尝试将非平稳数据转换为平稳数据。这也将趋势转换为更线性的趋势。这并不是处理时间序列数据的完美方法,但它可以提高工作频率,在你第一次了解代码时不用担心这个问题。
sales_df['y_orig'] = sales_df['y']
sales_df['y'] = np.log(sales_df['y'])
3、开始建立模型:
model = Prophet()
model.fit(sales_df)
如果你使用的是月度数据,那么在运行上述命令之后,很可能会看到以下提示:
Disabling weekly seasonality. Run prophet with weekly_seasonality=True to override this.
你可以忽略此提示。
4、开始预测:
使用Prophet,你可以使用以下命令构建一些未来时间数据:
future_data = model.make_future_dataframe(periods=6, freq = 'm')
现在我们使用“predict”函数进行预测:
forecast_data = m.predict(future_data)
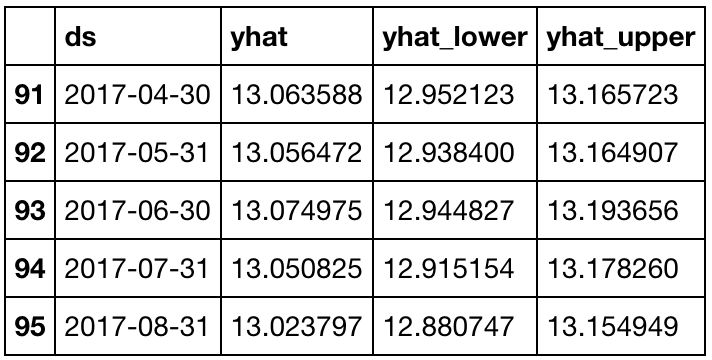
让我们看一下这组数据的图表,以便了解我们的模型是如何工作的。
model.plot(forecast_data)
让我们再来看看/数据/模型/预测的季节性和趋势。
model.plot_components(forecast_data)
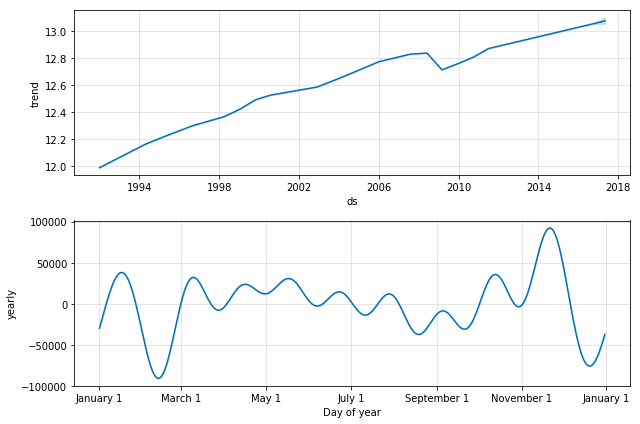
因为我们使用的是月度数据,Prophet会绘制趋势和每年的季节性,但是如果你使用的是日度数据,你会看到一个周的季节性图表。
从趋势和季节性上看,我们可以看到趋势在潜在的时间序列中起了很大的作用,而季节性在年初和年底的时候发挥了更大的作用。
基于以上信息,我们就能够快速地建模和预测一些数据,以便从这些特定的数据集中了解将来可能发生的事情。
我们继续调整这个模型,同时分享一个小技巧让你的预测图显示的原始数据,你可以通过使用np.exp()来获取原始数据:
forecast_data_orig = forecast_data
forecast_data_orig['yhat'] = np.exp(forecast_data_orig['yhat'])
forecast_data_orig['yhat_lower'] = np.exp(forecast_data_orig['yhat_lower'])
forecast_data_orig['yhat_upper'] = np.exp(forecast_data_orig['yhat_upper'])
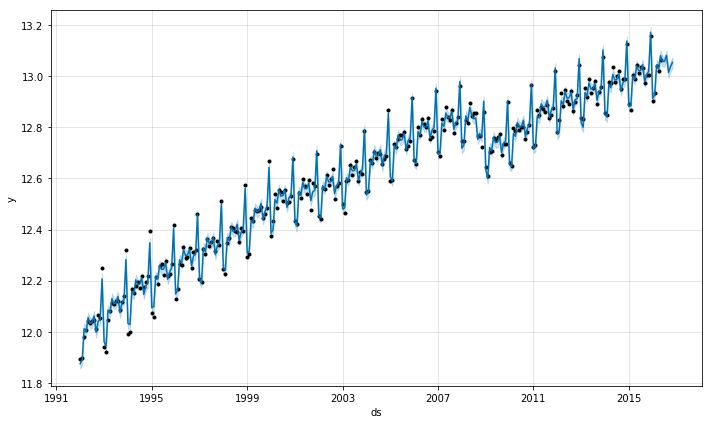
让我们看看预测值与原始数据:
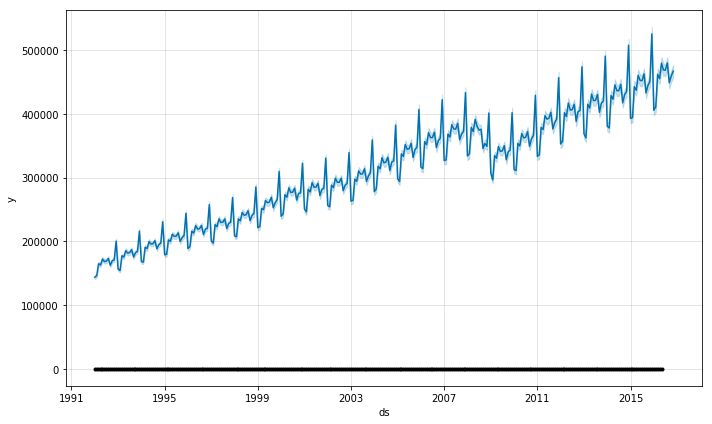
上面这张图看着怪怪的。我们把原始数据绘制在预测图上,黑点(图表底部)是我们的原始数据。为了让这个整个图表更有参考意义,我们需要把原始的y数据点绘制在这个图表上。为此,只需将sales_df dataframe中的“y_orig”列重命名为“y”即可绘制正确的数据。
sales_df['y_log']=sales_df['y']
sales_df['y']=sales_df['y_orig']
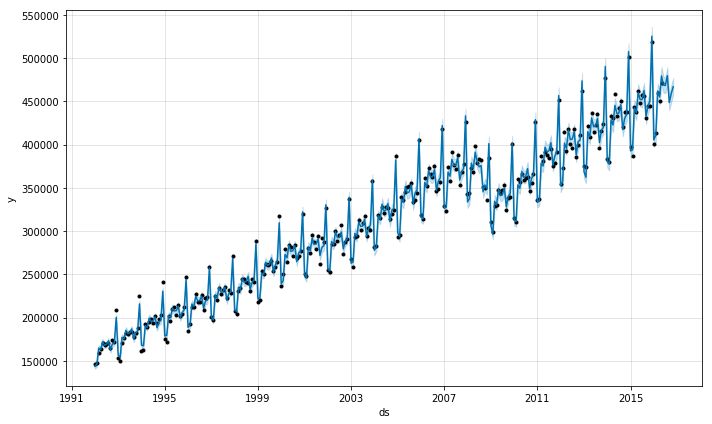
对未来6个月销量将在450K到475K之间。
sales_df = pd.read_csv('examples/retail_sales.csv')
sales_df['y_orig']=sales_df.y
sales_df['y'] = np.log(sales_df['y'])
model = Prophet()
model.fit(sales_df);
future_data = model.make_future_dataframe(periods=12, freq = 'm')
forecast_data = model.predict(future_data)
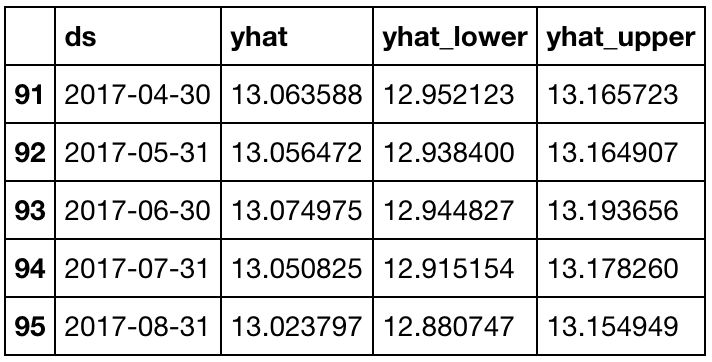
使用Prophet内置绘图函数来绘制输出:
model.plot(forecast_data)
首先,我们需要将数据进行适当的组合和索引,以便开始绘图。我们只对来预测数据集的“yhat”、“yhat_lower”和“yhat_upper”列作分析。
forecast_data.set_index('ds', inplace=True)
viz_df = sales_df.join(forecast_data[['yhat', 'yhat_lower','yhat_upper']], how = 'outer')
del viz_df['y']
del viz_df['index']
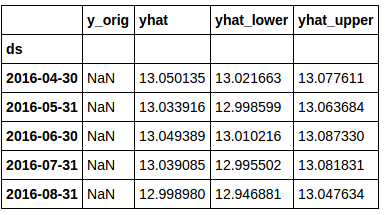
你会注意到“y_orig”列中充满了“NaN”。这是因为“未来日期”行没有原始数据。
现在,让我们看一下如何比缺省情况下的Prophet库更好地可视化这些数据。
首先,我们需要在原始的销售数据中得到最后的日期。这将用于分割绘图的数据。
sales_df.index = pd.to_datetime(sales_df.index)
last_date = sales_df.index[-1]
为了绘制预测数据,我们将设置一个函数导入两个额外的库来减去日期(timedelta):
from datetime import date,timedelta
def plot_data(func_df, end_date):
end_date = end_date - timedelta(weeks=4)
mask = (func_df.index > end_date)
predict_df = func_df.loc[mask]
fig, ax1 = plt.subplots()
ax1.plot(sales_df.y_orig)
ax1.plot((np.exp(predict_df.yhat)), color='black', linestyle=':')
ax1.fill_between(predict_df.index, np.exp(predict_df['yhat_upper'
]), np.exp(predict_df['yhat_lower']), alpha=0.5, color='darkgray')
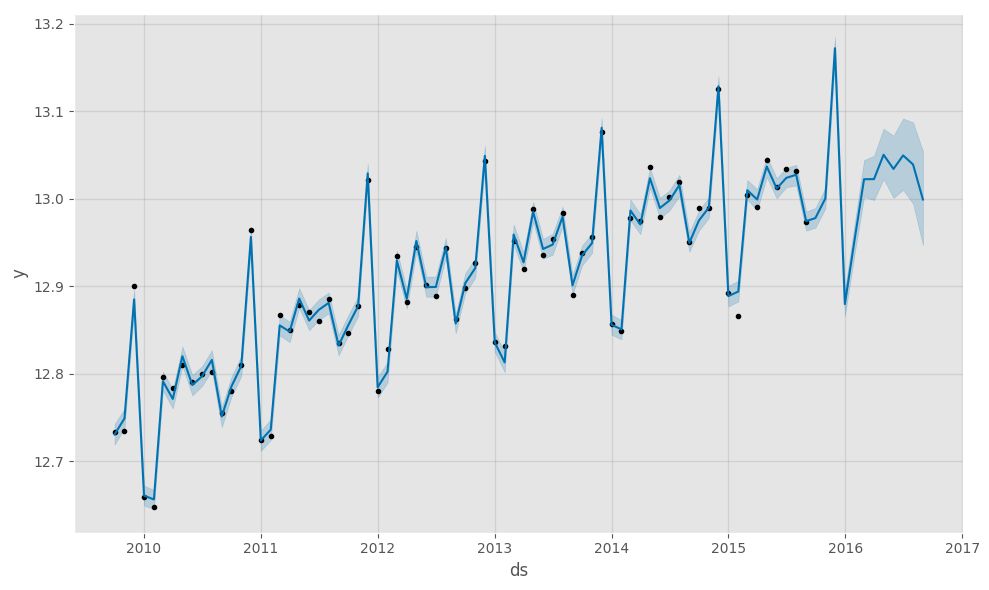
ax1.set_title('Sales (Orange) vs Sales Forecast (Black)')
ax1.set_ylabel('Dollar Sales')
ax1.set_xlabel('Date')
L=ax1.legend()
L.get_texts()[0].set_text('Actual Sales')
L.get_texts()[1].set_text('Forecasted Sales')
此函数去查找:
原始数据倒数第二行(https://stackoverflow.com/questions/29370057/select-dataframe-rows-between-two-dates)
然后创建一组新数据(predict_df),只包含“future data”。然后,它根据预测数据创建一个带有置信带的图。
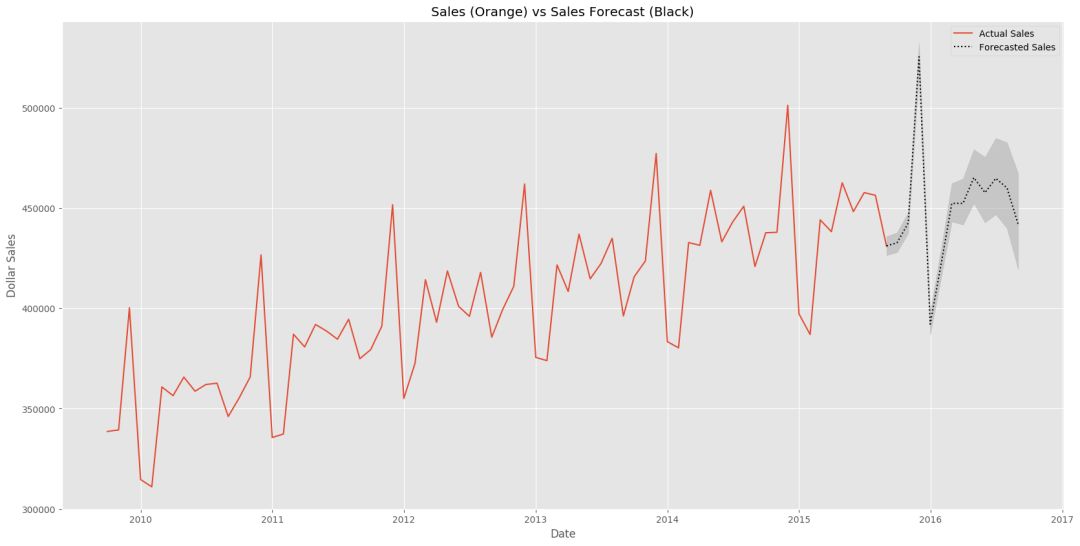
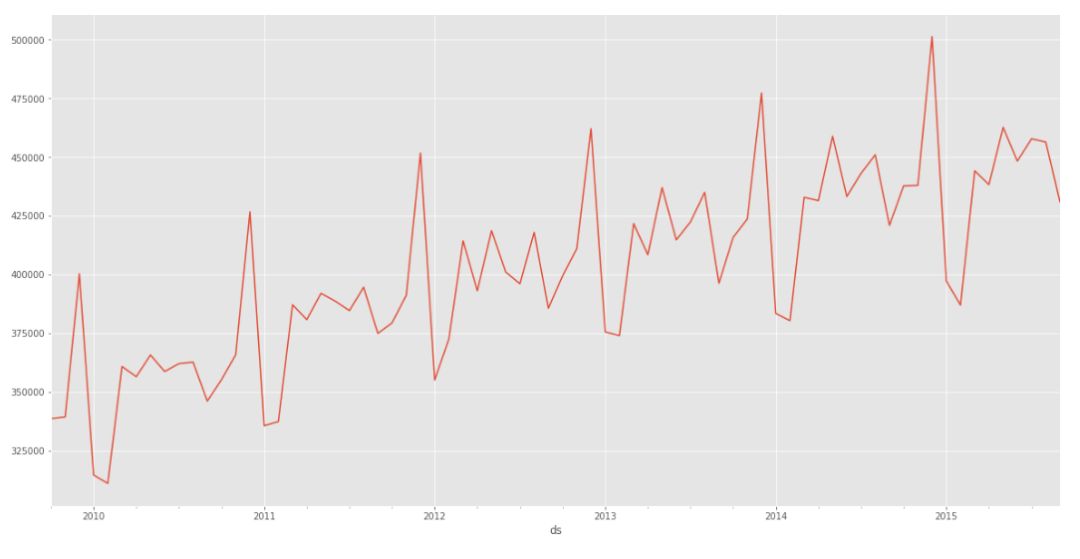
在前面两个部分,我们预测了未来24个月的月度销售数据。在此部分中,我们想看看如何使用Prophet库中的‘holiday’结构来更好地预测具体事件。如果我们看到的销售数据,每年的12月份都有一个明显的不同。这种模式可能有多种原因,但我们假设这是由于每年12月的促销活动造成的。
Prophet允许构建一个holiday的Dataframe,并在你的模型中使用这些数据。对于本示例,将以以下方式构建我的Prophet holiday数据:
promotions = pd.DataFrame({
'holiday': 'december_promotion',
'ds': pd.to_datetime(['2009-12-01', '2010-12-01', '2011-12-01', '2012-12-01',
'2013-12-01', '2014-12-01','2015-12-01']),
'lower_window':
0,
'upper_window': 0,
})
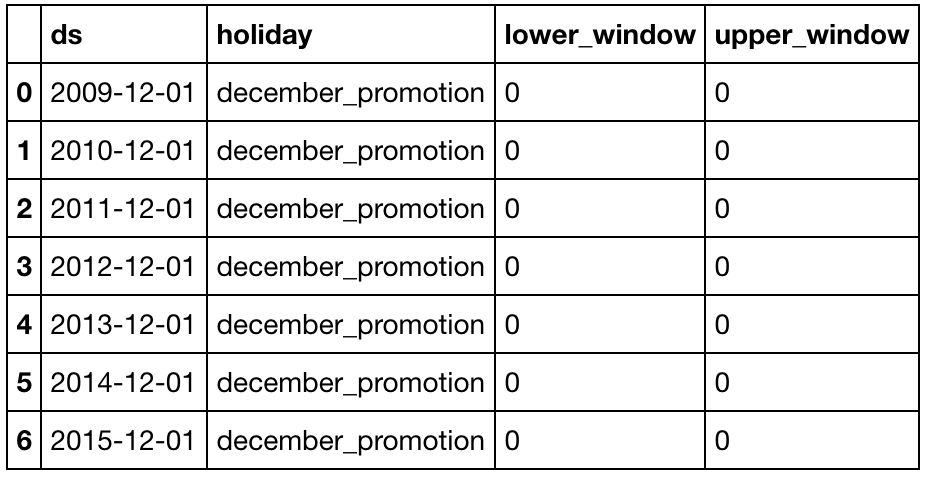
将lower_window和upper_window的值设置为零,以表明我们不希望Prophet考虑任何其他月份列表。
sales_df = pd.read_csv('../examples/retail_sales.csv', index_col='date', parse_dates=True)
df = sales_df.reset_index()
df=df.rename(columns={'date':'ds', 'sales':'y'})
df['y'] = np.log(df['y'])
model = Prophet(holidays=promotions)
model.fit(df);
future = model.make_future_dataframe(periods=24, freq = 'm')
forecast = model.predict(future)
model.plot(forecast);
绘制模型,如下所示:
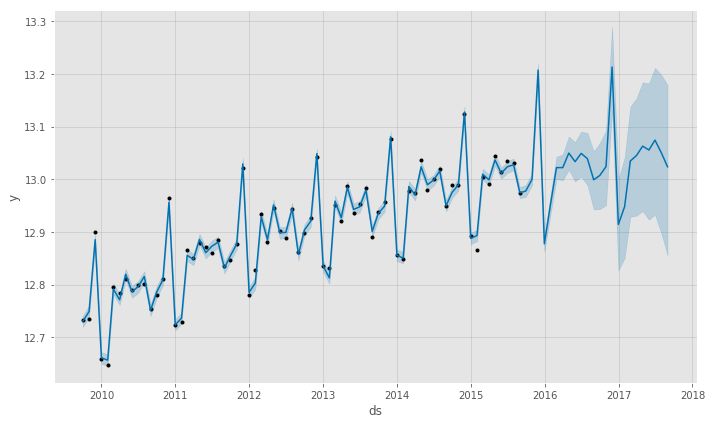
另外,Prophet的component是十分重要,因为它允许你查看模型的趋势和季节性等等:
model.plot_components(forecast)
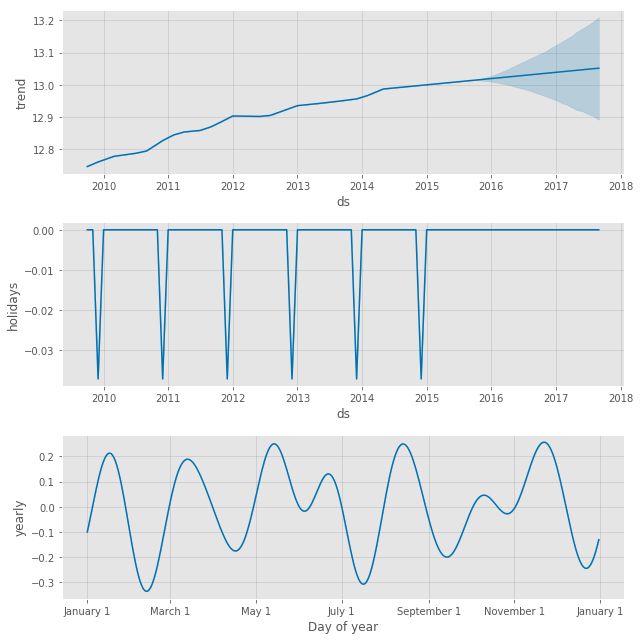
具体内容请查看详细Notebook。
在后台输入
20181104
后台获取方式介绍
1、经过多年交易之后你应该学到的东西(深度分享)
2、监督学习标签在股市中的应用(代码+书籍)
3、2018年学习Python最好的5门课程
4、全球投行顶尖机器学习团队全面分析
5、使用Tensorflow预测股票市场变动
6、被投资圈残害的清北复交学生们
7、使用LSTM预测股票市场基于Tensorflow
8、手把手教你用Numpy构建神经网络(附代码)
9、判断哪些输入特征对神经网络是重要的
10、美丽的回测——教你定量计算过拟合概率
在量化投资的道路上
你不是一个人在战斗!





