作者 | 罗昭成
责编 | 唐小引
出品 | CSDN(ID:CSDNNews)
最近几天,有部国产电影因好评及口碑传播而开始异军突起以黑马之势逆袭,在朋友圈以及微博上都会不时看到相关内容,那便是由陈建斌、任素汐等主演的《无名之辈》。这样一部没有什么特别大牌或流量明星,甚至名称与海报都没有什么特色的国产电影却引起了很多人的注意,更是在评分上直接将同期的如《毒液》、《神奇动物:格林德沃之罪》给 PK 了下去。这部剧从 16 日上映到现在,豆瓣评分 8.3 分,其中 5 星好评占 34.8%,而在猫眼上好评则直接超过了 50%。看这个数据,还是一部不错的国产剧。在一个貌似平常的日子,笔者用着一台低配的 Mac 电脑跑了一下《无名之辈》猫眼的评论数据,来看看这部小成本喜剧片究竟值不值得看。

需要特别说明一下,为什么要用猫眼的数据,而不用豆瓣的?主要还是因为豆瓣是直接渲染的 HTML,而猫眼的数据是 JSON,处理起来比较方便。

获取猫眼接口数据
作为一个长期宅在家的程序员,对各种抓包简直是信手拈来。在 Chrome 中查看原代码的模式,可以很清晰地看到接口,接口地址即为:
http://m.maoyan.com/mmdb/comments/movie/1208282.json?_v_=yes&offset=15
在 Python 中,我们可以很方便地使用 request 来发送网络请求,进而拿到返回结果:
def getMoveinfo(url):
session = requests.Session()
headers = {
"User-Agent": "Mozilla/5.0 (iPhone; CPU iPhone OS 11_0 like Mac OS X)"
}
response = session.get(url, headers=headers)
if response.status_code == 200:
return response.text
return None
根据上面的请求,我们能拿到此接口的返回数据,数据内容有很多信息,但有很多信息是我们并不需要的,先来总体看看返回的数据:
{
"cmts":[
{
"approve":0,
"approved":false,
"assistAwardInfo":{
"avatar":"",
"celebrityId":0,
"celebrityName":"",
"rank":0,
"title":""
},
"authInfo":"",
"cityName":"贵阳",
"content":"必须十分,借钱都要看的一部电影。",
"filmView":false,
"id":1045570589,
"isMajor":false,
"juryLevel":0,
"majorType":0,
"movieId":1208282,
"nick":"nick",
"nickName":"nickName",
"oppose":0,
"pro":false,
"reply":0,
"score":5,
"spoiler":0,
"startTime":"2018-11-22 23:52:58",
"supportComment":true,
"supportLike":true,
"sureViewed":1,
"tagList":{
"fixed":[
{
"id":1,
"name":"好评"
},
{
"id":4,
"name":"购票"
}
]
},
"time":"2018-11-22 23:52",
"userId":1871534544,
"userLevel":2,
"videoDuration":0,
"vipInfo":"",
"vipType":0
}
]
}
如此多的数据,我们感兴趣的只有以下这几个字段:
nickName, cityName, content, startTime, score
接下来,进行我们比较重要的数据处理,从拿到的 JSON 数据中解析出需要的字段:
def parseInfo(data):
data = json.loads(html)['cmts']
for item in data:
yield{
'date':item['startTime'],
'nickname':item['nickName'],
'city':item['cityName'],
'rate':item['score'],
'conment':item['content']
}
拿到数据后,我们就可以开始数据分析了。但是为了避免频繁地去猫眼请求数据,需要将数据存储起来,在这里,笔者使用的是 SQLite3,放到数据库中,更加方便后续的处理。存储数据的代码如下:
def saveCommentInfo(moveId, nikename, comment, rate, city, start_time)
conn = sqlite3.connect('unknow_name.db')
conn.text_factory=str
cursor = conn.cursor()
ins="insert into comments values (?,?,?,?,?,?)"
v = (moveId, nikename, comment, rate, city, start_time)
cursor.execute(ins,v)
cursor.close()
conn.commit()
conn.close()

数据处理
因为前文我们是使用数据库来进行数据存储的,因此可以直接使用 SQL 来查询自己想要的结果,比如评论前五的城市都有哪些:
SELECT city, count(*) rate_count FROM comments GROUP BY city ORDER BY rate_count DESC LIMIT 5
结果如下:
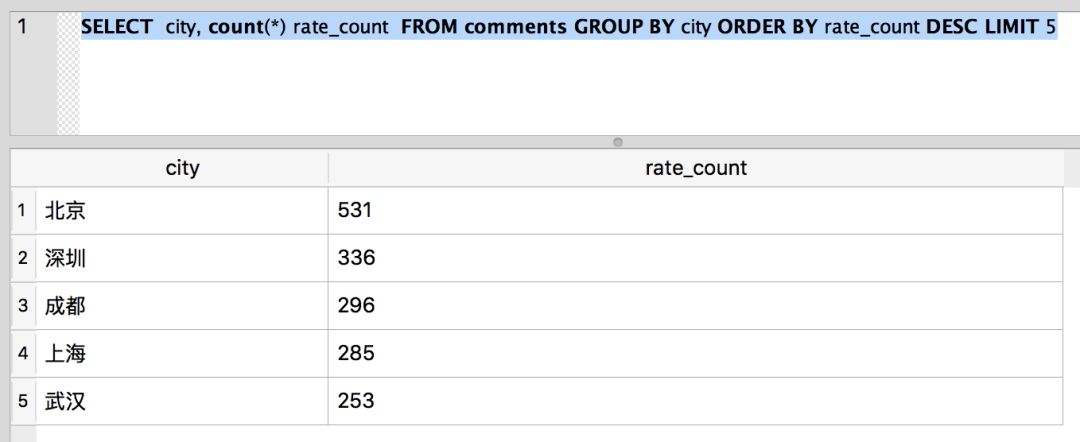
从上面的数据, 我们可以看出来,来自北京的评论数最多。
不仅如此,还可以使用更多的 SQL 语句来查询想要的结果。比如每个评分的人数、所占的比例等。如笔者有兴趣,可以尝试着去查询一下数据,就是如此地简单。
而为了更好地展示数据,我们使用 Pyecharts 这个库来进行数据可视化展示。
根据从猫眼拿到的数据,按照地理位置,直接使用 Pyecharts 来在中国地图上展示数据:
data = pd.read_csv(f,sep='{',header=None,encoding='utf-8'
,names=['date','nickname','city','rate','comment'])
city = data.groupby(['city'])
city_com = city['rate'].agg(['mean','count'])
city_com.reset_index(inplace=True)
data_map = [(city_com['city'][i],city_com['count'][i]) for i in range(0,city_com.shape[0])]
geo = Geo("GEO 地理位置分析",title_pos = "center",width = 1200,height = 800)
while True:
try:
attr,val = geo.cast(data_map)
geo.add("",attr,val,visual_range=[0,300],visual_text_color="#fff",
symbol_size=10, is_visualmap=True,maptype='china')
except ValueError as e:
e = e.message.split("No coordinate is specified for ")[1]
data_map = filter(lambda item: item[0] != e, data_map)
else :
break
geo.render('geo_city_location.html')
注:使用 Pyecharts 提供的数据地图中,有一些猫眼数据中的城市找不到对应的从标,所以在代码中,GEO 添加出错的城市,我们将其直接删除,过滤掉了不少的数据。
使用 Python,就是如此简单地生成了如下地图:
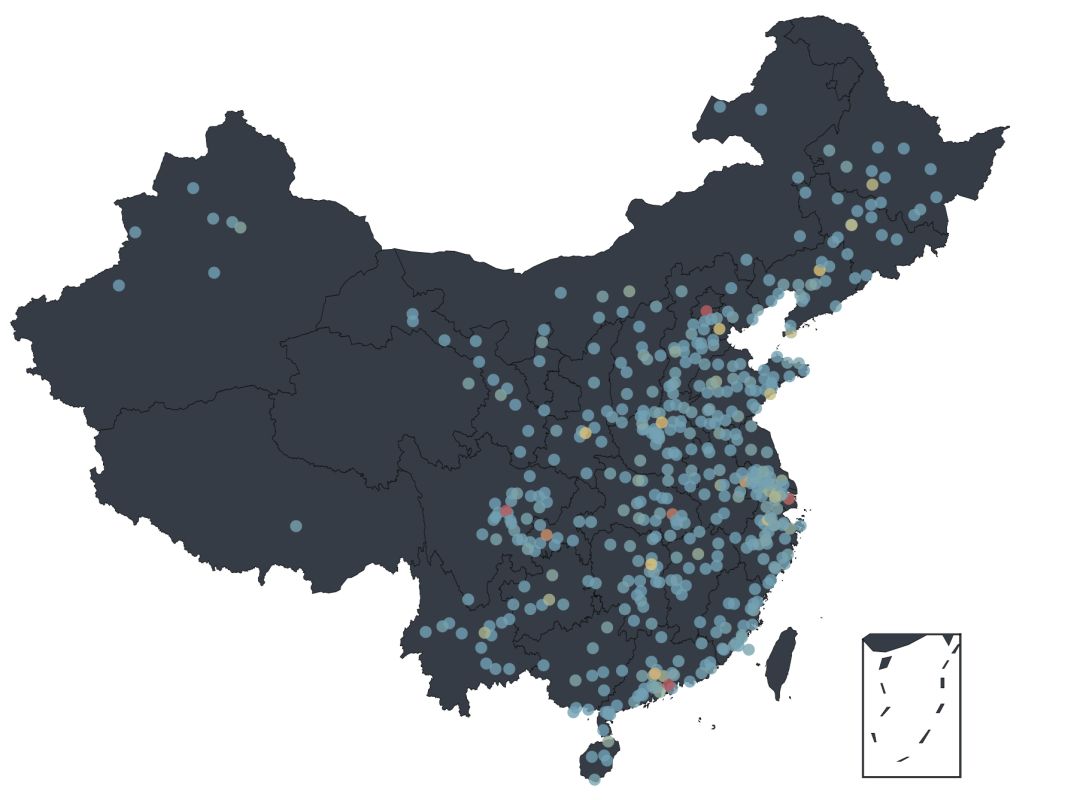
从可视化数据中可以看出,既看电影又评论的人群主要分布在中国东部,又以北京、上海、成都、深圳最多。虽然能从图上看出来很多数据,但还是不够直观,如果想看到每个省/市的分布情况,我们还需要进一步处理数据。
而在从猫眼中拿到的数据中,城市包含数据中具备县城的数据,所以需要将拿到的数据做一次转换,将所有的县城转换到对应省市里去,然后再将同一个省市的评论数量相加,得到最后的结果。
data = pd.read_csv(f,sep='{',header=None,encoding='utf-8',names=['date','nickname','city','rate','comment'])
city = data.groupby(['city'])
city_com = city['rate'].agg(['mean','count'])
city_com.reset_index(inplace=True)
fo = open("citys.json",'r')
citys_info = fo.readlines()
citysJson = json.loads(str(citys_info[0]))
data_map_all = [(getRealName(city_com['city'][i], citysJson),city_com['count'][i]) for i in range(0,city_com.shape[0])]
data_map_list = {}
for item in data_map_all:
if data_map_list.has_key(item[0]):
value = data_map_list[item[0]]
value += item[1]
data_map_list[item[0]] = value
else:
data_map_list[item[0]] = item[1]
data_map = [(realKeys(key), data_map_list[key] ) for key in data_map_list.keys()]
def getRealName(name, jsonObj):
for item in jsonObj:
if item.startswith(name) :
return jsonObj[item]
return name
def realKeys(name):
return name.replace(u"省", "").replace(u"市", "")
.replace(u"回族自治区", "").replace(u"维吾尔自治区", "")
.replace(u"壮族自治区", "").replace(u"自治区", "")
经过上面的数据处理,使用 Pyecharts 提供的 map 来生成一个按省/市来展示的地图:
def generateMap(data_map):
map = Map("城市评论数", width= 1200, height = 800, title_pos="center")
while True:
try:
attr,val = geo.cast(data_map)
map.add("",attr,val,visual_range=[0,800],
visual_text_color="#fff",symbol_size=5,
is_visualmap=True,maptype='china',
is_map_symbol_show=False,is_label_show=True,is_roam=False,
)
except ValueError as e:
e = e.message.split("No coordinate is specified for "
)[1]
data_map = filter(lambda item: item[0] != e, data_map)
else :
break
map.render('city_rate_count.html')
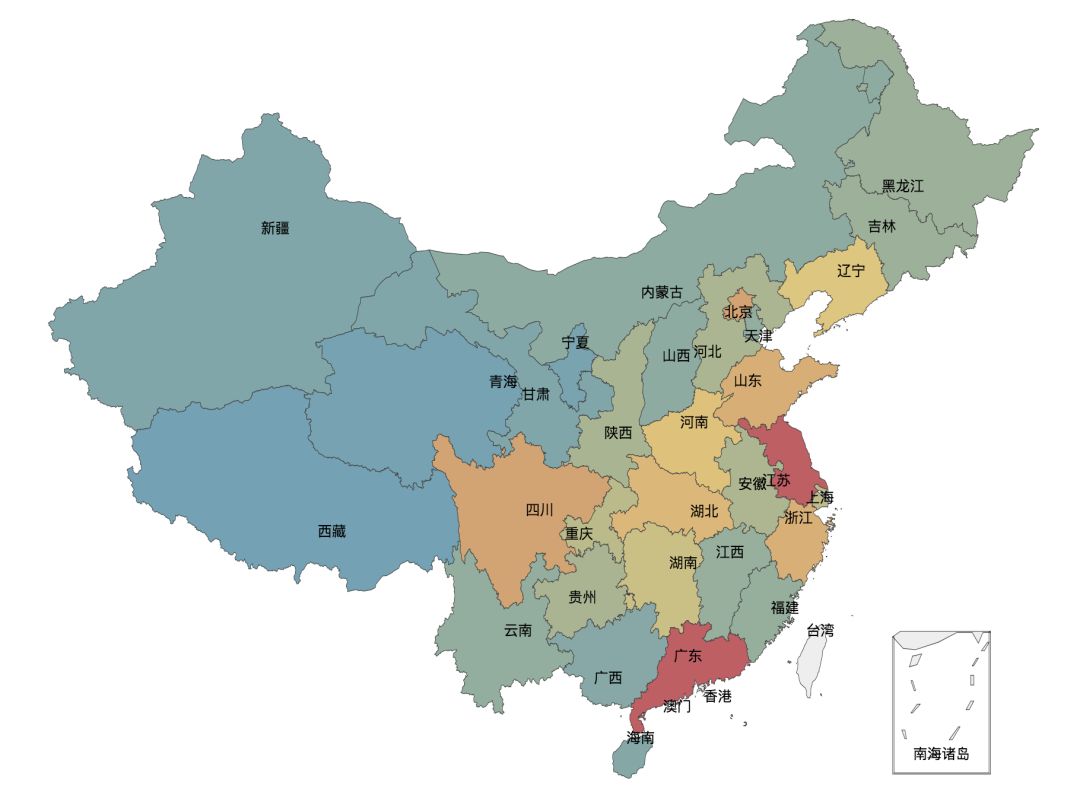
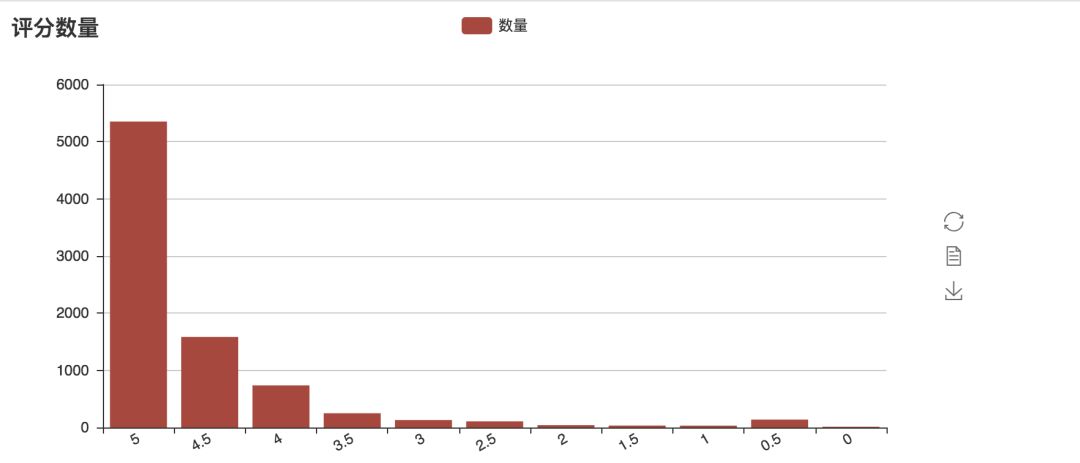
当然,我们还可以来可视化一下每一个评分的人数,这个地方采用柱状图来显示:
data = pd.read_csv(f,sep='{',header=None,encoding='utf-8',names=['date','nickname','city','rate','comment'])
rateData = data.groupby(['rate'])
rateDataCount = rateData["date"].agg([ "count"])
rateDataCount.reset_index(inplace=True)
count = rateDataCount.shape[0] - 1
attr = [rateDataCount["rate"][count - i] for i in range(0, rateDataCount.shape[0])]
v1 = [rateDataCount["count"][count - i] for i in range(0, rateDataCount.shape[0])]
bar = Bar("评分数量")
bar.add("数量",attr,v1,is_stack=True,xaxis_rotate=30,yaxix_min=4.2,
xaxis_interval=0,is_splitline_show=True)
bar.render("html/rate_count.html")
画出来的图,如下所示,在猫眼的数据中,五星好评的占比超过了 50%,比豆瓣上 34.8% 的五星数据好很多。
从以上观众分布和评分的数据可以看到,这一部剧,观众朋友还是非常地喜欢。前面,从猫眼拿到了观众的评论数据。现在,笔者将通过 jieba 把评论进行分词,然后通过 Wordcloud 制作词云,来看看,观众朋友们对《无名之辈》的整体评价:
data = pd.read_csv(f,sep='{',header=None,encoding='utf-8',names=['date','nickname','city','rate','comment'])
comment = jieba.cut(str(data['comment']),cut_all=False)
wl_space_split = " ".join(comment)
backgroudImage = np.array(Image.open(r"./unknow_3.png"))
stopword = STOPWORDS.copy()
wc = WordCloud(width=1920,height=1080,background_color='white',
mask=backgroudImage,
font_path="./Deng.ttf",
stopwords=stopword,max_font_size=400,
random_state=50)
wc.generate_from_text(wl_space_split)
plt.imshow(wc)
plt.axis("off")
wc.to_file('unknow_word_cloud.png')
导出:

再说从这张词云图我们可以明显地看到“小人物”、“好看”、“喜剧”、“演技”这四个字非常地突出,历来能够称得上黑马的都是小成本并且反映小人物的荒诞喜剧为多,从这四个关键词中我们似乎看出了这部电影究竟为什么会收获众多好评。一如豆瓣上的一条短评所言:“不是爱情,胜似爱情。丧的刚刚好,黑的刚刚好,暖的刚刚好。有人说,中国没有‘治愈系’的电影。从此片起,就有了。看这片,我们笑着流泪。刻画底层人物的现实主义题材的电影不在少数,但此片是我近年来看过的,最具诚意、三观最正,也最‘哀而不伤’的一部。你将充分感受到什么叫‘真正的演技’,你将看到陈建斌任素汐章宇王砚辉等‘顶级演技天团’如何飙戏。真心期盼,从此片起,国产片将真正迎来‘好演员+好电影的春天’。”

【完】
微信改版了,
想快速看到CSDN的热乎文章,
赶快把CSDN公众号设为星标吧,
打开公众号,点击“设为星标”就可以啦!

CSDN 公众号秉持着「与千万技术人共成长」理念,不仅以「极客头条」、「畅言」栏目在第一时间以技术人的独特视角描述技术人关心的行业焦点事件,更有「技术头条」专栏,深度解读行业内的热门技术与场景应用,让所有的开发者紧跟技术潮流,保持警醒的技术嗅觉,对行业趋势、技术有更为全面的认知。
如果你有优质的文章,或是行业热点事件、技术趋势的真知灼见,或是深度的应用实践、场景方案等的新见解,欢迎联系 CSDN 投稿,联系方式:微信(guorui_1118,请备注投稿+姓名+公司职位),邮箱(guorui@csdn.net)。
推荐阅读: