经常写爬虫的都知道,有些页面在登录之前是被禁止抓取的,比如知乎的话题页面就要求用户登录才能访问,而 “登录” 离不开 HTTP 中的 Cookie 技术。
登录原理
Cookie 的原理非常简单,因为 HTTP 是一种无状态的协议,因此为了在无状态的 HTTP 协议之上维护会话(session)状态,让服务器知道当前是和哪个客户在打交道,Cookie 技术出现了 ,Cookie 相当于是服务端分配给客户端的一个标识。
cookie
浏览器第一次发起 HTTP 请求时,没有携带任何 Cookie 信息
服务器把 HTTP 响应,同时还有一个 Cookie 信息,一起返回给浏览器
浏览器第二次请求就把服务器返回的 Cookie 信息一起发送给服务器
服务器收到HTTP请求,发现请求头中有Cookie字段, 便知道之前就和这个用户打过交道了。
分析Post数据
由于知乎进行了改版,网上很多其他的模拟登录的方式已经不行了,所以这里从原理开始一步步分析要如何进行模拟登录。
要把我们的爬虫伪装成浏览器登录,则首先要理解浏览器登录时,是怎么发送报文的。首先打开知乎登录页,打开谷歌浏览器开发者工具,选择Network页,勾选Presev log,点击登陆。 我们很容易看到登录的请求首等信息:
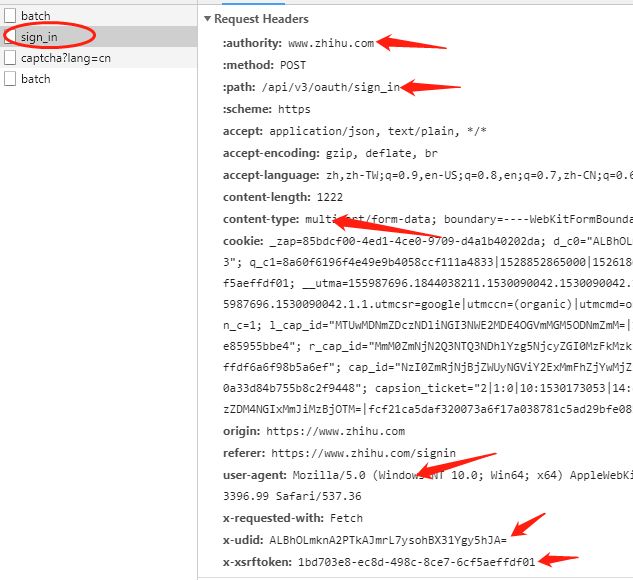
模拟登录最终是要构建请求首和提交参数,即构造 Request Headers和FormData。
构建Headers
Request Headers中有几个参数需要注意:
Content-Type (后面的boundary指定了表单提交的分割线)
cookie (登陆前cookie就不为空,说明之前肯定有set-cookie的操作 )
X-Xsrftoken (则是防止Xsrf跨域的Token认证,可以在Response Set-Cookie中找到 )
接下来我们看看登录时我们向服务器请求了什么,因为这是开门的钥匙,我们必须先知道钥匙由哪些部分组成,才能成功的打开大门:
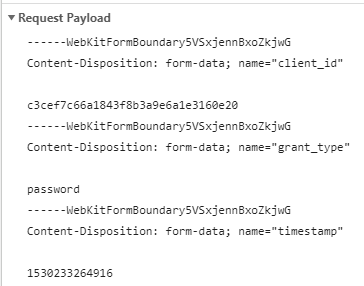
可以看到Request Payload中出现最多的是—-Webxxx这一字符串,上面已经说过了,这是一个分割线,我们可以直接忽略,所以第一个参数是:client_id=c3cef7c66a1843f8b3a9e6a1e3160e20 ;第二个参数为grant_type=password….整理了所有的参数如下(知乎的改版可能导致参数改变):
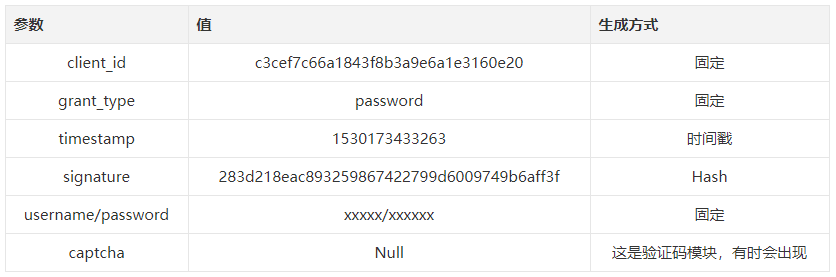
后面还有一些参数是固定参数,这里就不一一列出来了。现在总结我们需要自己生成的一些参数:
X-Xsrftoken
利用全局搜索可以发现该参数的值存在cookie中,因此可以利用正则表达式直接从cookie中提取;
timestamp
该参数为时间戳,可以使用 timestamp = str(int(time.time()*1000))生成
signature
首先ctrl+shift+F全局搜索signature,发现其是在main.app.xxx.js的一个js文件中生成的,打开该.js文件,然后复制到编辑器格式化代码
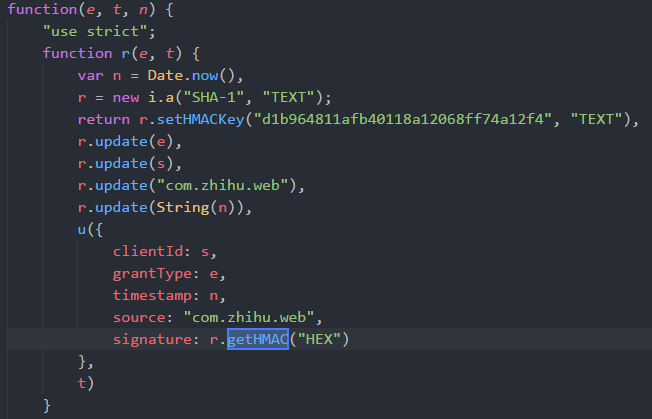
因此我们可以用python来重写这个hmac加密过程:
def _get_signature(timestamp):
"""
通过 Hmac 算法计算返回签名
实际是几个固定字符串加时间戳
:param timestamp: 时间戳
:return: 签名
"""
ha = hmac.new(b'd1b964811afb40118a12068ff74a12f4', digestmod=hashlib.sha1)
grant_type = self.login_data['grant_type']
client_id = self.login_data['client_id']
source = self.login_data['source']
ha.update(bytes((grant_type + client_id + source + timestamp), 'utf-8'))
return ha.hexdigest()
验证码
登录提交的表单中有个captcha参数,这是登录的验证码参数,有时候登录时会出现需要验证码的情况。captcha 验证码,是通过 GET 请求单独的 API 接口返回是否需要验证码(无论是否需要,都要请求一次),如果是 True 则需要再次 PUT 请求获取图片的 base64 编码。
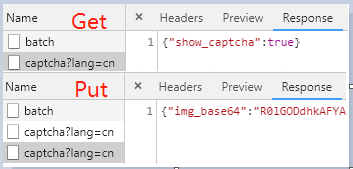
所以登录验证的过程总共分为三步,首先GET请求看是否需要验证码;其次根据GET请求的结果,如果为True,则需要发送PUT请求来获取验证的图片;最后将验证的结果通过POST请求发送给服务器。
这是lang=cn的API需要提交的数据形式,实际上有两个 API,一个是识别倒立汉字,一个是常见的英文验证码,任选其一即可,汉字是通过 plt 点击坐标,然后转为 JSON 格式。
最后还有一点要注意,如果有验证码,需要将验证码的参数先 POST 到验证码 API,再随其他参数一起 POST 到登录 API。该部分完整的代码如下:
def _get_captcha(lang, headers):
if lang == 'cn':
api = 'https://www.zhihu.com/api/v3/oauth/captcha?lang=cn'
else:
api = 'https://www.zhihu.com/api/v3/oauth/captcha?lang=en'
resp = self.session.get(api, headers=headers)
show_captcha = re.search(r'true', resp.text)
if show_captcha:
put_resp = self.session.put(api, headers=headers)
json_data = json.loads(put_resp.text)
img_base64 = json_data['img_base64'].replace(r'\n', '')
with open('./captcha.jpg', 'wb') as f:
f.write(base64.b64decode(img_base64))
img = Image.open('./captcha.jpg')
if lang == 'cn':
plt.imshow(img)
print('点击所有倒立的汉字,按回车提交')
points = plt.ginput(7)
capt = json.dumps({'img_size': [200, 44],
'input_points': [[i[0]/2, i[1]/2] for i in points]})
else:
img.show()
capt = input('请输入图片里的验证码:')
self.session.post(api, data={'input_text': capt}, headers=headers)
return capt
return ''
保存Cookie
最后实现一个检查登录状态的方法,如果访问登录页面出现跳转,说明已经登录成功,这时将 Cookies 保存起来(这里 session.cookies 初始化为 LWPCookieJar 对象,所以有 save 方法),这样下次登录可以直接读取 Cookies 文件。
self.session.cookies = cookiejar.LWPCookieJar(filename='./cookies.txt')
def check_login(self):
resp = self.session.get(self.login_url, allow_redirects=False)
if resp.status_code == 302:
self.session.cookies.save()
return True
return False
总结
理解了我们需要哪些信息,以及信息的提交方式,现在来整理完整的登录过程:
构建HEADERS请求头和FORM_DATA表单的基本信息,一般为固定不变的信息;
从cookies中获取x-xsrftoken,更新到headers中;
检查用户名和密码是否在data表单中,如果没有,则需要更新用户名和密码到表单中;
获取时间戳,并利用时间戳来计算signature参数,模拟js中的hmac过程;
检查验证码,如果需要验证码,则先将验证码的结果POST到验证API端口,手动输入验证码的结果;
将时间戳、验证码以及signature这三个参数更新到Request Payload中,即程序中的login_data表单;
将headers和data这两个表单信息POST到Login_API这个接口,可以查看我们登录时的信息,是把提交的信息发送到https://www.zhihu.com/api/v3/… ;
检查返回的response结果,如果有error,则输出错误的结果;否则表示登录成功,保存cookie文件。
原文地址:https://segmentfault.com/a/1190000015454650
学习Python就关注:datanami

近期文章:
写Python爬虫不可不理解队列Queue
坑爹的Python陷阱
30个有关Python的小技巧
Python 实现多线程下载器
Python新手收藏这一篇就够了







