
向AI转型的程序员都关注了这个号👇👇👇
机器学习AI算法工程 公众号: datayx
我们经常会碰到一个问题:用了复杂的GBDT或者xgboost大大提升了模型效果,可是在上线的时候又犯难了,工程师说这个模型太复杂了,我没法上线,满足不了工程的要求,你帮我转换成LR吧,直接套用一个公式就好了,速度飞速,肯定满足工程要求。这个时候你又屁颠屁颠用回了LR,重新训练了一下模型,心里默骂千百遍:工程能力真弱。
这些疑问,我们以前碰到过,通过不断的摸索,试验出了不同的复杂机器学习的上线方法,来满足不同场景的需求。在这里把实践经验整理分享,希望对大家有所帮助。(我们的实践经验更多是倾向于业务模型的上线流程,广告和推荐级别的部署请自行绕道)。
首先在训练模型的工具上,一般三个模型训练工具,Spark、R、Python。这三种工具各有千秋,以后有时间,我写一下三种工具的使用心得。针对不同的模型使用场景,为了满足不同的线上应用的要求,会用不同的上线方法。
一、总结来说,大体会区分这三种场景,请大家对号入座,酌情使用
如果是实时的、小数据量的预测应用,则采用的SOA调用Rserve或者python-httpserve来进行应用;这种应用方式有个缺点是需要启用服务来进行预测,也就是需要跨环境,从Java跨到R或者Python环境。对于性能,基本上我们用Rserver方式,针对一次1000条或者更少请求的预测,可以控制95%的结果在100ms内返回结果,100ms可以满足工程上的实践要求。更大的数据量,比如10000/次,100000/次的预测,我们目前评估下来满足不了100ms的要求,建议分批进行调用或者采用多线程请求的方式来实现。
如果是实时、大数据量的预测应用,则会采用SOA,训练好的模型转换成PMML(关于如何转换,我在下面会详细描述),然后把模型封装成一个类,用Java调用这个类来预测。用这种方式的好处是SOA不依赖于任何环境,任何计算和开销都是在Java内部里面消耗掉了,所以这种工程级别应用速度很快、很稳定。用此种方法也是要提供两个东西,模型文件和预测主类;
如果是Offline(离线)预测的,D+1天的预测,则可以不用考虑第1、2中方式,可以简单的使用Rscript x.R或者python
x.py的方式来进行预测。使用这种方式需要一个调度工具,如果公司没有统一的调度工具,你用shell的crontab做定时调用就可以了。
以上三种做法,都会用SOA里面进行数据处理和变换,只有部分变换会在提供的Function或者类进行处理,一般性都建议在SOA里面处理好,否则性能会变慢。
大概场景罗列完毕,简要介绍一下各不同工具的线上应用的实现方式。
二、如何转换PMML,并封装PMML
大部分模型都可以用PMML的方式实现,PMML的使用方法调用范例见:
jpmml的说明文档:
https://link.zhihu.com/?target=https%3A//github.com/jpmml/jpmml-evaluator
Java调用PMML的范例(https://link.zhihu.com/?target=https%3A//github.com/pjpan/PPJUtils/tree/master/java/pmml ),此案例是我们的工程师写的范例,大家可以根据此案例进行修改即可;
Jpmml支持的转换语言,主流的机器学习语言都支持了,深度学习类除外;
从下图可以看到,它支持R、python和spark、xgboost等模型的转换,用起来非常方便。
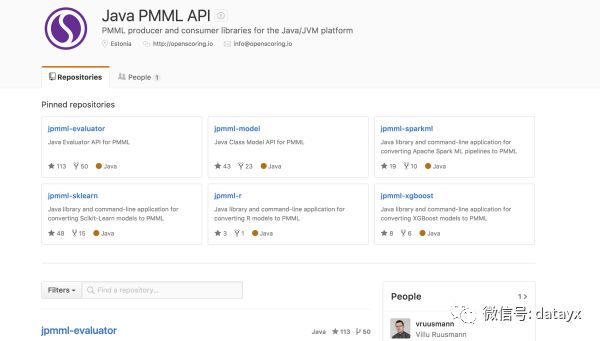
三、接下来说一下各个算法工具的工程实践
python模型上线:我们目前使用了模型转换成PMML上线方法。
python-sklearn里面的模型都支持,也支持xgboost,并且PCA,归一化可以封装成preprocess转换成PMML,所以调用起来很方便;
特别需要注意的是:缺失值的处理会影响到预测结果,大家可以可以看一下;
用PMML方式预测,模型预测一条记录速度是1ms,可以用这个预测来预估一下根据你的数据量,整体的速度有多少。
2.R模型上线-这块我们用的多,可以用R model转换PMML的方式来实现。
这里我介绍另一种的上线方式:Rserve。具体实现方式是:用SOA调用Rserve的方式去实现,我们会在服务器上部署好R环境和安装好Rserve,然后用JAVA写好SOA接口,调用Rserve来进行预测;
https://link.zhihu.com/?target=https%3A//github.com/pjpan/DataScience/blob/master/R/RServe%25E7%259A%2584%25E6%2590%25AD%25E5%25BB%25BA.md
Rserve方式可以批量预测,跟PMML的单个预测方式相比,在少数据量的时候,PMML速度更快,但是如果是1000一次一批的效率上看,Rserve的方式会更快;用Rserve上线的文件只需要提供两个:
模型结果文件(XX.Rdata);
预测函数(Pred.R)。
Rserve_1启动把模型结果(XX.Rdata)常驻内存。预测需要的输入Feature都在Java里定义好不同的变量,然后你用Java访问Rserve_1,调用Pred.R进行预测,获取返回的List应用在线上。最后把相关的输入输出存成log进行数据核对。
Pred.R function(x1,x2,x3){
data (x1,x2,x3)
score data, type = 'prob')
return(list(score))
}
3.Spark模型上线-好处是脱离了环境,速度快。
Spark模型的上线就相对简单一些,我们用scala训练好模型(一般性我们都用xgboost训练模型)然后写一个Java
Class,直接在JAVA中先获取数据,数据处理,把处理好的数据存成一个数组,然后调用模型Class进行预测。模型文件也会提前load在内存里面,存在一个进程里面,然后我们去调用这个进程来进行预测。所以速度蛮快的。
Spark模型上线,放在spark集群,不脱离spark环境,方便,需要自己打jar包;
我们这里目前还没有尝试过,有一篇博客写到了如果把spark模型导出PMML,然后提交到spark集群上来调用,大家可以参考一下:Spark加载PMML进行预测。
四、只用Linux的Shell来调度模型的实现方法-简单粗暴
因为有些算法工程师想快速迭代,把模型模拟线上线看一下效果,所以针对离线预测的模型形式,还有一种最简单粗暴的方法,这种方法开发快速方便,具体做法如下:
predict.sh的写法如下:

最后用Crontab来进行调度,很简单,如何设置crontab,度娘一下就好了。

五、说完了部署上线,说一下模型数据流转的注意事项
区分offline和realtime数据,不管哪种数据,我们根据key和不同的更新频次,把数据放在redis里面去,设置不同的key和不同的过期时间;
大部分redis数据都会存放两个批次的数据,用来预防无法取到最新的数据,则用上一批次的数据来进行填充;
针对offline数据,用调度工具做好依赖,每天跑数据,并生成信号文件让redis来进行读取;
针对realtime数据,我们区分两种类型,一种是历史+实时,比如最近30天的累计订单量,则我们会做两步,第一部分是D+1之前的数据,存成A表,今天产生的实时数据,存储B表,A和B表表结构相同,时效性不同;我们分别把A表和B表的数据放在Redis上去,然后在SOA里面对这两部分数据实时进行计算;
模型的输入输出数据进行埋点,进行数据跟踪,一是用来校验数据,二来是用来监控API接口的稳定性,一般性我们会用ES来进行log的查看和性能方面的监控;
任何接口都需要有容灾机制,如果接口超时,前端需要进行容灾,立即放弃接口调用数据,返回一个默认安全的数值,这点对于工程上非常重要。
将机器学习模型部署为REST API
作为Python开发人员和数据科学家,我希望构建Web应用程序来展示我的工作。尽管我喜欢设计和编写前端代码,但很快就会成为网络应用程序开发和机器学习的佼佼者。因此,我必须找到一个可以轻松地将我的机器学习模型与其他开发人员集成的解决方案,这些开发人员可以比我更好地构建强大的Web应用程序
通过为我的模型构建REST API,我可以将我的代码与其他开发人员分开。这里有一个明确的分工,这对于定义职责很有帮助,并且阻止我直接阻止那些不参与项目机器学习方面的队友。另一个优点是我的模型可以由在不同平台上工作的多个开发人员使用。
在本文中,我将构建一个简单的Scikit-Learn模型,并使用Flask RESTful将其部署为REST API 。本文特别适用于没有广泛计算机科学背景的数据科学家。
关于模型
在这个例子中,我整理了一个简单的Naives Bayes分类器来预测电影评论中发现的短语的情绪。
这些数据来自Kaggle比赛,电影评论的情感分析。评论被分成单独的句子,句子进一步分成单独的短语。所有短语都具有情感分数,以便可以训练模型,其中哪些单词对句子具有积极,中立或消极的情绪。
从Kaggle数据集中分配评级
大多数短语都有中性评级。起初,我尝试使用多项式朴素贝叶斯分类器来预测5种可能类别中的一种。但是,由于大多数数据的评级为2,因此该模型的表现不佳。我决定保持简单,因为本练习的主要内容主要是关于部署为REST
API。因此,我将数据限制在极端类别,并训练模型仅预测负面或正面情绪。
事实证明,多项式朴素贝叶斯模型在预测正面和负面情绪方面非常有效。您可以在此Jupyter笔记本演练中快速了解模型培训过程。在Jupyter笔记本中训练模型后,我将代码转移到Python脚本中,并为NLP模型创建了一个类对象。您可以在下面链接中找到我的Github仓库中的代码。您还需要挑选模型,以便快速将训练过的模型加载到API脚本中。
完整项目源码获取方式:
关注微信公众号 datayx 然后回复 部署 即可获取。
现在我们有了模型,让我们将其部署为REST API。
REST API指南
为API的Flask应用程序启动一个新的Python脚本。
导入库和加载Pickles
下面的代码块包含很多Flask样板和加载分类器和矢量化器pickles的代码。

创建一个参数解析器
解析器将查看用户发送给API的参数。参数将在Python字典或JSON对象中。对于这个例子,我们将专门寻找一个名为的密钥query。查询将是用户希望我们的模型预测短语是正面还是负面的短语。

资源类对象
资源是Flask RESTful API的主要构建块。每个类别可以具有对应于的REST API的主要行动,如方法:GET,PUT,POST,和DELETE。GET将是主要方法,因为我们的目标是提供预测。在get下面的方法中,我们提供了有关如何处理用户查询以及如何打包将返回给用户的JSON对象的说明。
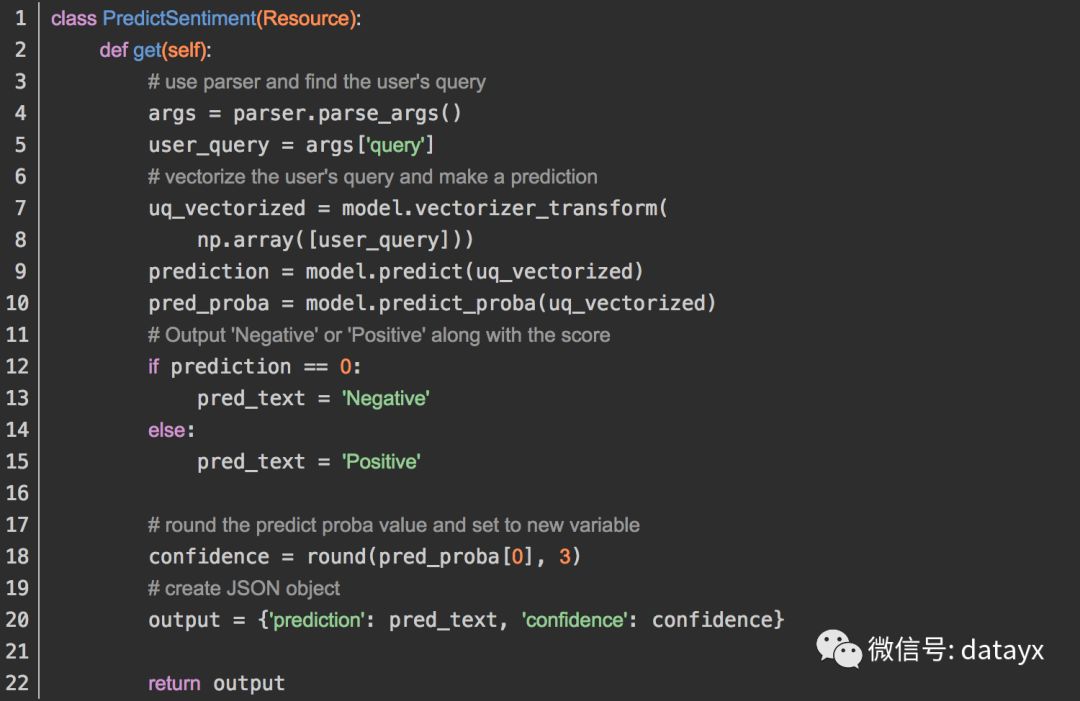
端点
以下代码将基本URL设置为情绪预测器资源。您可以想象您可能有多个端点,每个端点指向可以进行不同预测的不同模型。一个示例可以是端点,'/ratings'其将指导用户到另一个模型,该模型可以预测给定类型,预算和生产成员的电影评级。您需要为第二个模型创建另一个资源对象。这些可以一个接一个地添加,如下所示。

名称==主要区块
这里不多说。如果要将此API部署到生产环境,请将debug设置为False。

用户请求
以下是用户如何访问您的API以便他们获得预测的一些示例。
使用Jupyter笔记本中的Requests模块:

使用curl:

使用HTTPie:
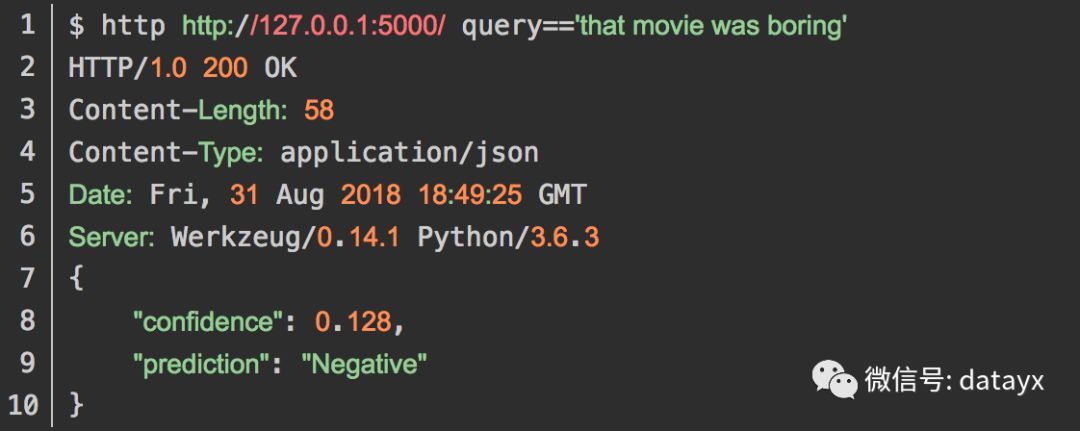
现在,我的队友可以通过向这个API发出请求来为他们的应用添加情绪预测,而无需将Python和JavaScript混合在一起。
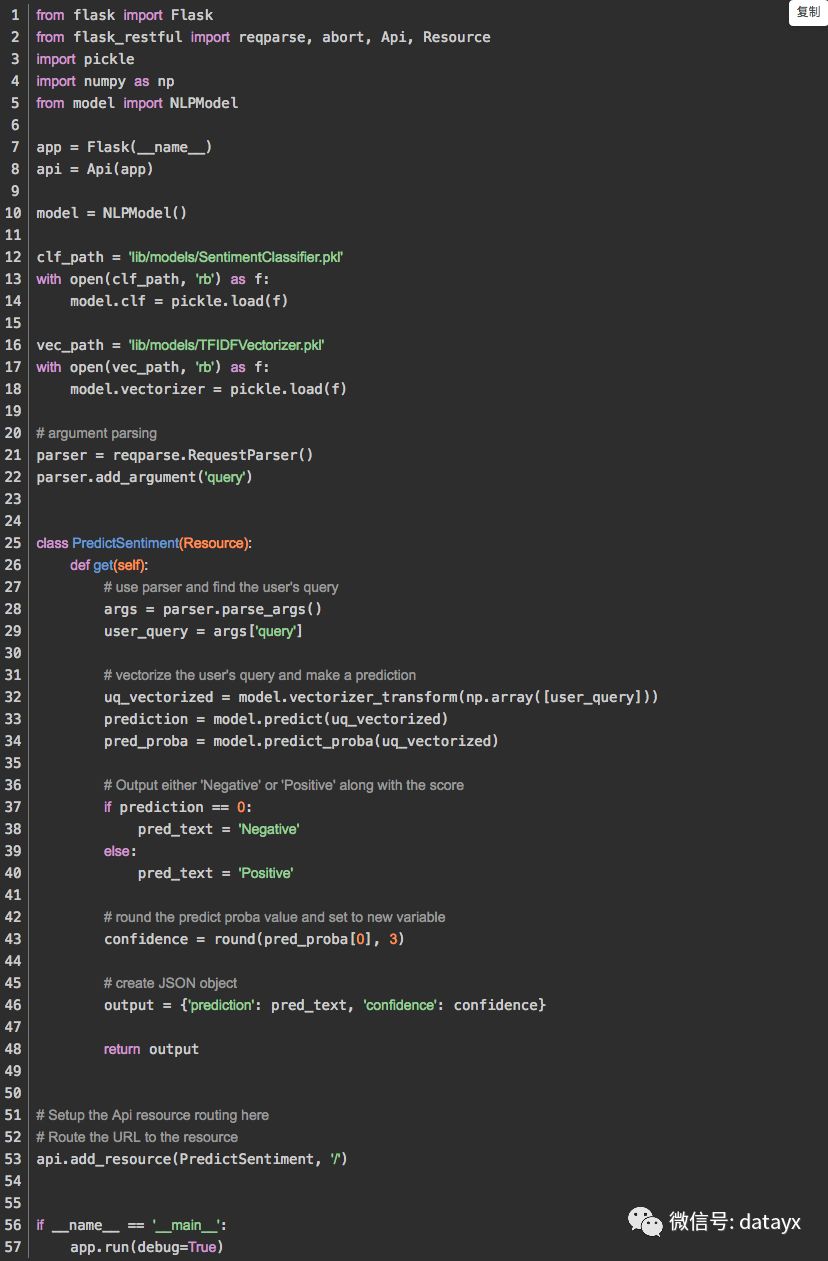
完整app.py 代码
有时在一个地方查看所有代码会很有帮助。

部署
一旦您构建了模型和REST API并在本地完成测试,您就可以像将任何Flask应用程序部署到Web上的许多托管服务一样部署API。通过在Web上部署,各地的用户都可以向您的URL发出请求以获取预测。部署指南包含在Flask文档中。
这只是为情绪分类器构建Flask REST API的一个非常简单的示例。一旦您训练并保存了相同的过程,就可以应用于其他机器学习或深度学习模型。
除了将模型部署为REST API之外,我还使用REST API来管理数据库查询,以便通过从Web上抓取来收集数据。这使我可以与全栈开发人员协作,而无需管理其React应用程序的代码。如果移动开发人员想要构建应用程序,那么他们只需熟悉API端点即可。
https://blog.csdn.net/u012294181/article/details/54564391
阅读过本文的人还看了以下:
《21个项目玩转深度学习:基于TensorFlow的实践详解》完整版PDF+附书代码
FashionAI服装属性标签图像识别Top1-5方案分享
重要开源!CNN-RNN-CTC 实现手写汉字识别
yolo3 检测出图像中的不规则汉字
同样是机器学习算法工程师,你的面试为什么过不了?
前海征信大数据算法:风险概率预测
【Keras】完整实现‘交通标志’分类、‘票据’分类两个项目,让你掌握深度学习图像分类
VGG16迁移学习,实现医学图像识别分类工程项目
特征工程(一)
特征工程(二) :文本数据的展开、过滤和分块
特征工程(三):特征缩放,从词袋到 TF-IDF
特征工程(四): 类别特征
特征工程(五): PCA 降维
特征工程(六): 非线性特征提取和模型堆叠
特征工程(七):图像特征提取和深度学习
如何利用全新的决策树集成级联结构gcForest做特征工程并打分?
Machine Learning Yearning 中文翻译稿
蚂蚁金服2018秋招-算法工程师(共四面)通过
全球AI挑战-场景分类的比赛源码(多模型融合)
斯坦福CS230官方指南:CNN、RNN及使用技巧速查(打印收藏)
python+flask搭建CNN在线识别手写中文网站
中科院Kaggle全球文本匹配竞赛华人第1名团队-深度学习与特征工程
不断更新资源
深度学习、机器学习、数据分析、python
搜索公众号添加: datayx

长按图片,识别二维码,点关注









