作者介绍
杨建荣,竞技世界资深DBA,前搜狐畅游数据库专家,Oracle ACE,YEP成员。拥有近十年数据库开发和运维经验,目前专注于开源技术、运维自动化和性能调优。拥有Oracle 10g OCP、OCM、MySQL OCP认证,对Shell、Java有一定功底。每天通过微信、 博客进行技术分享,已连续坚持1800多天。

最近有一个业务库的负载比往常高了很多,最直观的印象就是原来的负载最高是100%,现在不是翻了几倍或者指数级增长,而是突然翻了100倍,导致业务后端的数据写入剧增,产生了严重的性能阻塞。
这类问题引起了我的兴趣和好奇心,经过和业务方沟通了解,这个业务是记录回执数据的,简单来说就好比你发送了一条微博,想看看有多少人已读,有多少人留言等。所以这类场景不存在事务,会有数据的密集型写入,会有明确的统计需求。
目前的统计频率是每7分钟做一次统计,会有几类统计场景,目前基本都是全表扫描级别的查询语句。当前数据库的架构很简单,是一个主从,外加MHA高可用。

问题的改进方向是减少主库的压力,分别是读和写的压力。写入的压力来自于业务的并发写入压力,而读的压力来自于于全表扫描的压力,对于CPU和IO压力都很大。
这两个问题的解决还是存在优先级,首先统计的SQL导致了系统资源成为瓶颈,结果原本简单的Insert也成为了慢日志SQL,相比而言,写入需求是硬需求,而统计需求是辅助需求,所以在这种场景下和业务方沟通,快速的响应方式就是把主库的统计需求转移到从库端。
转移了读请求的负载,写入压力得到了极大缓解,后来也经过业务方的应用层面的优化,整体的负载情况就相对乐观了:




这个算是优化的第一步改进,在这个基础上,开始做索引优化,但是通过对比,发现效果很有限。因为从库端的是统计需求,添加的索引只能从全表扫描降级为全索引扫描,对于系统整体的负载改进却很有限,所以我们需要对已有的架构做一些改进和优化。
引入读写分离,优化初见成效
方案1:
考虑到资源的成本和使用场景,所以我们暂时把架构调整为如下的方式:即添加两个数据节点,然后打算启用中间件的方式来做分布式的架构设计。对于从库,暂时为了节省成本,就对原来的服务器做了资源扩容,即单机多实例的模式,这样一来写入的压力就可以完全支撑住了。

但是这种方式有一个潜在的隐患,那就是从库的中间件层面来充当数据统计的角色,一旦出现性能问题,对于中间件的压力极大,很可能导致原本的统计任务会阻塞。同时从库端的资源瓶颈除了磁盘空间外就是IO压力,目前通过空间扩容解决不了这个硬伤。
在和业务同学进一步沟通后,发现他们对于这一类表的创建是动态配置的方式,在目前的中间件方案中很难以落实。而且对于业务来说,统计需求变得更加不透明了。
方案2:
一种行之有效的改进方式就是从应用层面来做数据路由,比如有10个业务:业务1、业务2在第一个节点,业务3、业务5在第二个节点等等,按照这种路由的配置方式来映射数据源,相对可控,更容易扩展,所以架构方式改为了这种:

而整个的改进中,最关键的一环是对于统计SQL性能的改进,如果SQL统计性能的改进能够初见成效,后续的架构改进就会更加轻松。
后续有开始有了业务的爆发式增长,使得统计需求的优化成为本次优化的关键所在。
原来的主库读写压力都很大,通过读写分离,使得读节点的压力开始激增,而且随着业务的扩展,统计查询的需求越来越多。比如原来是有10个查询,现在可能变成了30个,这样一来统计压力变大,导致系统响应降低,从而导致从库的延迟也开始变大。最大的时候延迟有3个小时,按照这种情况,统计的意义其实已经不大了。

对此我做了几个方面的改进:
首先是和业务方进行了细致的沟通,对于业务的场景有了一个比较清晰的认识,其实这个业务场景是蛮适合Redis之类的方案来解决的,但是介于成本和性价比选择了关系型的MySQL,结论:暂时保持现状。
对于读压力,目前不光支撑不了指数级压力,连现状都让人担忧。业务的每个统计需求涉及5个SQL,要对每个场景做优化都需要取舍,最后达到的一个初步效果是字段有5个,索引就有3个,而且不太可控的是一旦某个表的数据量太大导致延迟,整个系统的延迟就会变大,从而造成统计需求都整体垮掉,所以添加索引来解决硬统计需求算是心有力而力不足。结论:索引优化效果有限,需要寻求其他可行解决方案。
对于写压力,后续可以通过分片的策略来解决,这里的分片策略和我们传统认为的逻辑不同,这是基于应用层面的分片,应用端来做这个数据路由。这样分片对于业务的爆发式增长就很容易扩展了。有了这一层保障之后,业务的统计需求迁移到从库,写压力就能够平滑的对接了,目前来看写压力的空余空间很大,完全可以支撑指数级的压力。结论:业务数据路由在统计压力减缓后再开始改进。
为了快速改进现状,我写了一个脚本自动采集和管理,会定时杀掉超时查询的会话。但是延迟还是存在,查询依旧是慢,很难想象在指数级压力的情况下,这个延迟会有多大。
在做了大量的对比测试之后,按照单表3500万的数据量,8张同样数据量的表,5条统计SQL,做完统计大约需要17~18分钟左右,平均每个表需要大约2分多钟。
因为不是没有事务关联,所以这个场景的延迟根据业务场景和技术实现来说是肯定存在的,我们的改进方法是提高统计的查询效率,同时保证系统的压力在可控范围内。

一种行之有效的方式就是借助于数据仓库方案,MySQL原生不支持数据库仓库,但是有第三方的解决方案:一类是ColumStore,是在InfiniDB的基础上改造的;一类是Infobright,除此之外还有其他大型的解决方案,比如Greenplum的MPP方案,ColumnStore的方案有点类似于这种MPP方案,需要的是分布式节点,所以在资源和架构上Infobright更加轻量一些。
我们的表结构很简单,字段类型也是基本类型,而且在团队内部也有大量的实践经验。
改进之后的整体架构如下,原生的主从架构不受影响:

需要在此基础上扩展一个数据仓库节点,数据量可以根据需要继续扩容。
表结构如下:
CREATE TABLE `receipt_12149_428` (
`id` int(11) NOT NULL COMMENT '自增主键',
`userid` int(11) NOT NULL DEFAULT '0' COMMENT '用户ID',
`action` int(11) NOT NULL DEFAULT '0' COMMENT '动作',
`readtimes` int(11) NOT NULL DEFAULT '0' COMMENT '阅读次数',
`create_time` datetime NOT NULL COMMENT '创建时间'
) ;
导出的语句类似于:
select
*from ${tab_name} where create_time between xxx and xxxx into outfile
'/data/dump_data/${tab_name}.csv' FIELDS TERMINATED BY ' ' ENCLOSED BY
'\"';
Infobright社区版是不支持DDL和DML的,后期Infobright官方宣布:不再发布ICE社区版,将专注于IEE的开发,所以后续的支持力度其实就很有限了。对于我们目前的需求来说是游刃有余。
来简单感受下Infobright的实力:
>select count( id) from testxxx where id>2000;
+------------+
| count( id) |
+------------+
| 727686205 |
+------------+
1 row in set (6.20 sec)
>select count( id) from testxxxx where id
+------------+
| count( id) |
+------------+
| 13826684 |
+------------+
1 row in set (8.21 sec)
>select count( distinct id) from testxxxx where id
+---------------------+
| count( distinct id) |
+---------------------+
| 1999 |
+---------------------+
1 row in set (10.20 sec)
所以对于几千万的表来说,这都不是事儿。
我把3500万的数据导入到Infobright里面,5条查询语句总共的执行时间维持在14秒,相比原来的2分钟多已经改进很大了。我跑了下批量的查询,原本要18分钟,现在只需要不到3分钟。
通过引入Infobright方案对已有的统计需求可以做到完美支持,但是随之而来的一个难点就是对于数据的流转如何平滑支持。我们可以设定流转频率,比如10分钟等或者半个小时,但是目前来看,这个是需要额外的脚本或工具来做的。
在具体落地的过程中,发现有一大堆的事情需要提前搞定。
其一:
比如第一个头疼的问题就是全量的同步,第一次同步肯定是全量的,这么多的数据怎么同步到Infobright里面。
第二个问题,也是更为关键的,那就是同步策略是怎么设定的,是否可以支持的更加灵活。
第三个问题是基于现有的增量同步方案,需要在时间字段上添加索引。对于线上的操作而言又是一个巨大的挑战。
其二:
从目前的业务需求来说,最多能够允许一个小时的统计延迟,如果后期要做大量的运营活动,需要更精确的数据支持,要得到半个小时的统计数据,按照现有的方案是否能够支持。
这两个主要的问题,任何一个解决不了,数据流转能够落地都是难题,这个问题留给我的时间只有一天。所以我准备把前期的准备和测试做得扎实一些,后期接入的时候就会顺畅得多。
部分脚本实现如下:
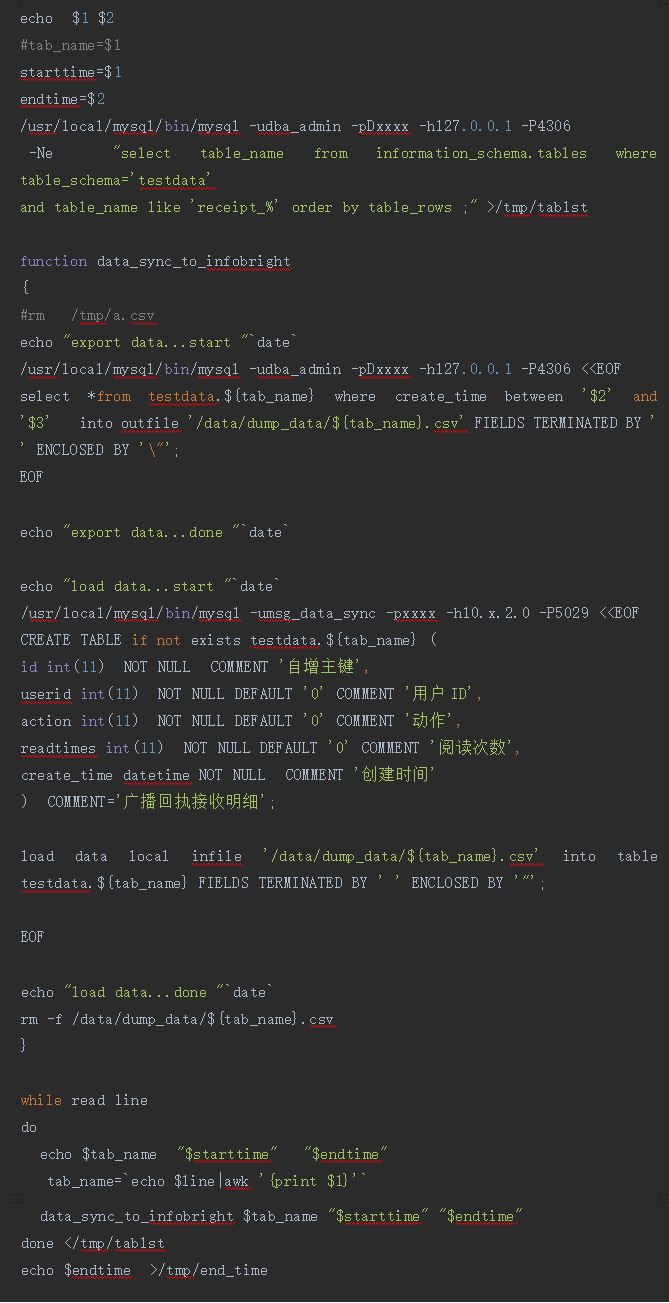
脚本的输入参数有两个,一个是起始时间,一个是截止时间。第一次全量同步的时候,可以把起始时间给的早一些,这样截止时间是固定的,逻辑上就是全量的。另外全量同步的时候一定要确保主从延迟已经最低或者暂时停掉查询业务,使得数据全量抽取更加顺利。
所以需要对上述脚本再做一层保证,通过计算当前时间和上一次执行的时间来得到任务可执行的时间。这样脚本就不需要参数了,这是一个动态调度的迭代过程。
考虑到每天落盘的数据量大概在10G左右,日志量在30G左右,所以考虑先使用客户端导入Infobright的方式来操作。
从实践来看,涉及的表有600多个,我先导出了一个列表,按照数据量来排序,这样小表就可以快速导入,大表放在最后,整个数据量有150G左右,通过网络传输导入Infobright,从导出到导入完成,这个过程大概需要1个小时。
而导入数据到Infobright之后的性能提升也是极为明显的。原来的一组查询持续时间在半个小时,现在在70秒钟即可完成。对于业务的体验来说大大提高。完成了第一次同步之后,后续的同步都可以根据实际的情况来灵活控制。所以数据增量同步暂时是“手动挡”控制。
从整个数据架构分离之后的效果来看,从库的压力大大降低,而效率也大大提高。
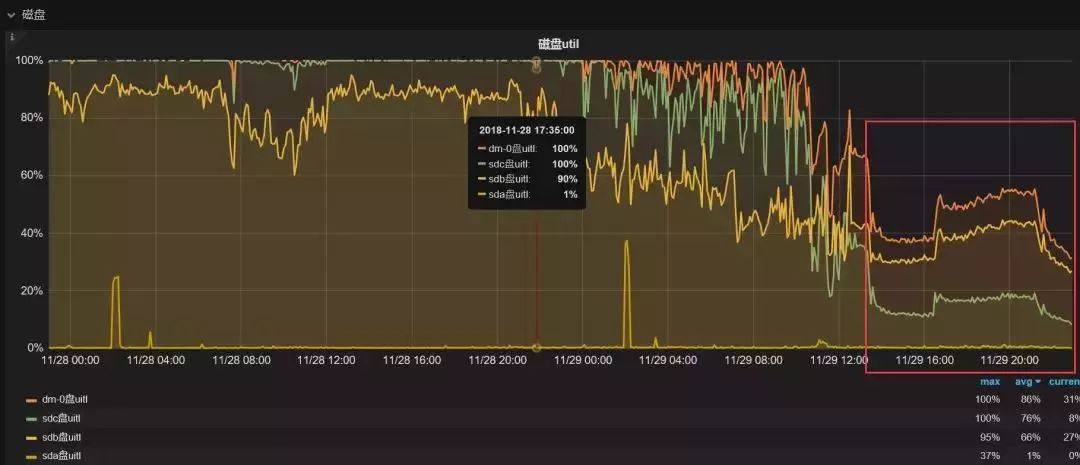
前面算是对现状做到了最大程度的优化,但是还有一个问题,目前的架构暂时能够支撑密集型数据写入,但是不能够支持指数级别的压力请求,而且存储容量很难以扩展。
从我的理解中,业务层面来做数据路由是最好的一种方式,而且从扩展上来说,也更加友好。
所以再进一层的改进方案如下:

通过数据路由来达到负载均衡,从目前来看效果是很明显的,而在后续要持续的扩容时,对于业务来说也是一种可控的方式。以下是近期的一些优化时间段里从库的IO的压力情况:
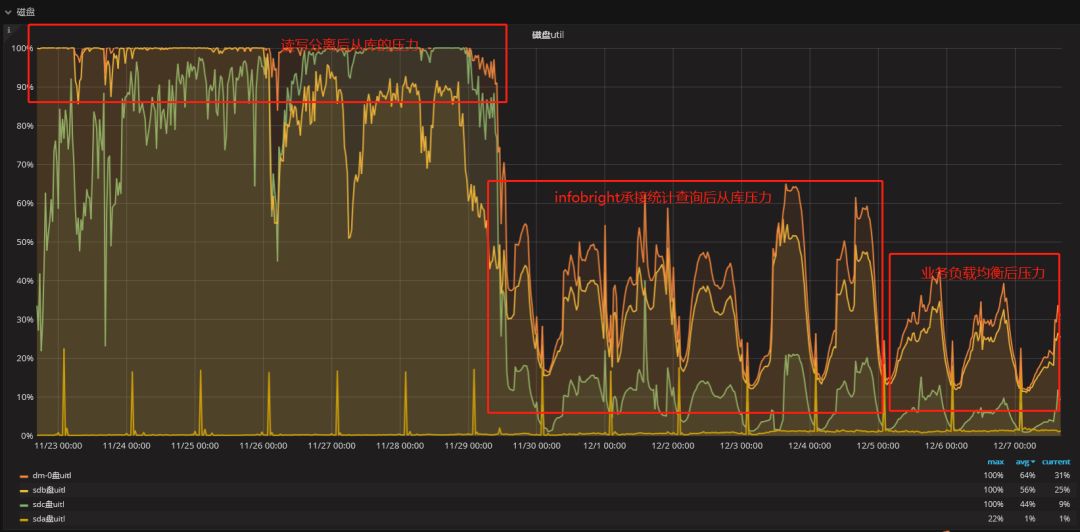
经过陆续几次地解决问题、补充并跟进方案,我们完成了从最初的故障到落地成功,MySQL性能扩展的架构优化分享也已经基本了结。如有更好的实现方式,欢迎大家在留言区交流分享!

往期推荐:
以分布式设计、架构、体系思想为基础,兼论研发相关的点点滴滴,不限于代码、质量体系和研发管理。











