

大家好!又到了每周一狗熊会的深度学习时间了。在上一讲中,我们对另一座深度生成模型大山——生成式对抗网络进行了详细的介绍。到这里深度学习的主要内容小编通过18讲的内容已经基本上跟大家介绍的差不多了。本讲小编想和大家介绍一些延伸性的内容,关于深度学习的三个方面,分别是神经风格迁移、深度强化学习以及著名的胶囊网络。

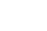
所谓图像的神经风格迁移(Style Transfer),就是指在给定图像A和图像B的情况下,通过神经网络将这两张图像转化为C,且C同时具有图像A的内容和图像B的风格。比如下图左边两张输入图片:一张图像是长城,一张是黄公望著名的富春山居图的一部分,通过第一张图像的长城内容和第二张图的山水画风格,经过神经网络进行风格迁移之后得到了一幅具有山水画风格的图像:
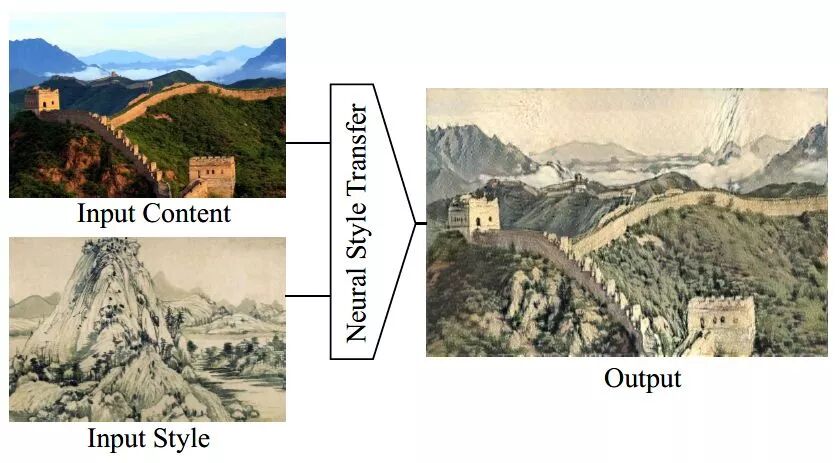
小编这里通过几篇神经风格迁移的论文来简单展示一下该领域的一些应用和进展。神经风格迁移领域相对早一点的一篇经典论文为 Gatys等人发表的 A Neural Algorithm of Artistic Style,其中系统的阐述了神经风格迁移的主要思想和原理。同样以图像A、B和C为例,神经风格迁移的主要思想如下:
图像C保留图像A的内容,或者说是图像A的语义。这个对于神经网络来说并不困难,各种深度卷积网络都可以较好的实现图像A到C的语义编码。
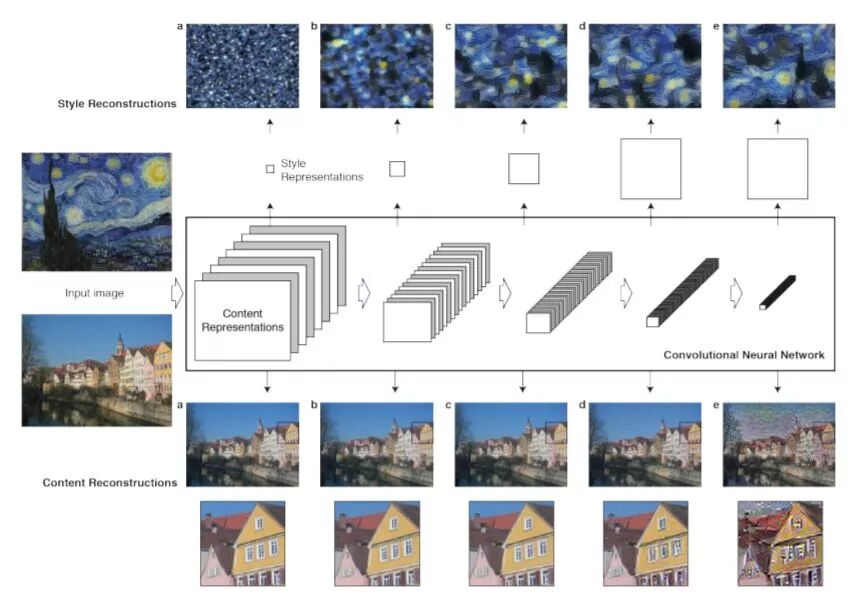
图像 C 具备图像 B 的风格。风格不像是图像语义,是一个整体或者全局的概念,一般来说很难把握,论文中考虑了图像特征之间的gram矩阵来衡量图像特征的相关性。所谓图像的gram矩阵,就是就是每个图像特征之间的内积所构成的矩阵:
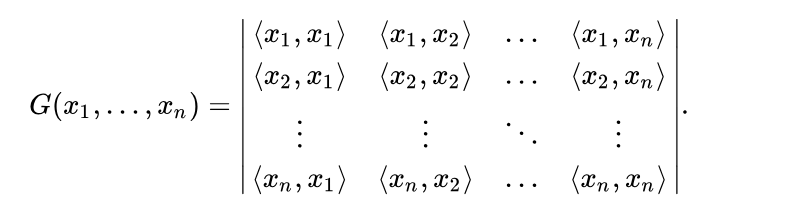
具体来说,我们可以先选取一个经过 ImageNet 训练好的预训练卷积网络,比如说 VGG16、InceptionNet或者是ResNet等等,下面以VGG16为例进行说明。假设图像X输入VGG16网络之后,第 m 层的输出有 Nm 个通道,每个通道有 Mm 个像素。定义 Xik 为第 i 个通道在第 k 个像素上的值,则图像A和C之间的内容损失可定义为:
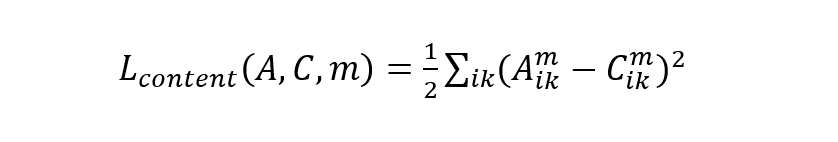
然后是风格损失。因为风格损失是基于 gram 矩阵的,所以先要给出 gram 矩阵的计算公式:
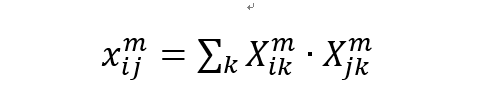
基于 gram 矩阵的风格损失定如下:
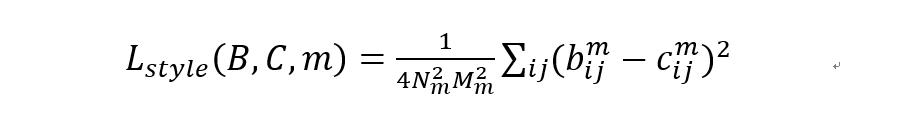
可以看到风格损失是基于图像整体的,与具体像素k无关,所以最终整个风格迁移的损失函数可以定义为:
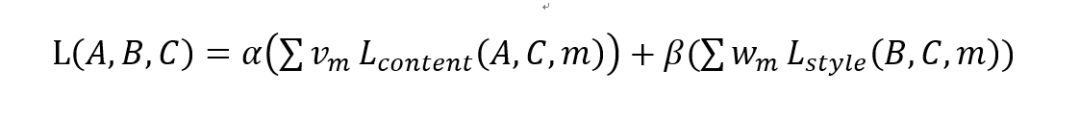
其中权重α和β决定了内容和风格之间的平衡,Vm和Wm决定了不同层次之间的平衡。基于上述思想论文给出的实现一幅莫奈星空图风格的建筑风格迁移:

整个图像风格迁移的过程与正常的神经网络优化过程还是有区别的,在神经风格迁移中,卷积网络的参数是经过预训练之后的参数,是一个固定值,实际能做的是调整输入以最小化损失函数。
关于神经风格迁移的其他理论和方法,Neural Style Transfer: A Review 这篇综述给出了该领域详尽的方法和相关应用:

从整个机器学习的任务划分上来看,机器学习可以分为有监督学习、有监督和半监督学习以及强化学习,而我们之前一直谈论的图像、文本等深度学习的应用都属于监督学习范畴。自编码器和生成式对抗网络可以算在无监督深度学习范畴内。最后就只剩下强化学习了。但是我们这是深度学习的笔记,为什么要把强化学习单独拎出来讲一下呢?因为强化学习发展到现在,早已结合了神经网络迸发出新的活力,强化学习结合深度学习已经形成了深度强化学习(Deep Reinforcement Learning)这样的新领域,因为强化学习和深度学习之间的关系以及其本身作为人工智能的一个重要方向,所以为了知识系统的完整性,小编这里用一小节的内容简单描述一下。
强化学习是一种关于序列决策的工具,在许多领域都有研究,例如博弈论、控制论、运筹学、信息论、仿真优化、多主体系统学习、群体智能、统计学以及遗传算法等领域。具体而言就是描述决策主体如何基于环境而行动以获取收益最大化的问题。强化学习一个最著名的例子就是此前击败李世石和柯洁的 ALPHAGo,其实现下棋并战胜人类的背后原理技术就是深度强化学习。

强化学习+深度学习的一个结果就是形成了深度强化学习这样的新领域,我们先简单介绍一下深度强化学习,然后来看一下深度神经网络是如何跟强化学习算法相结合的。
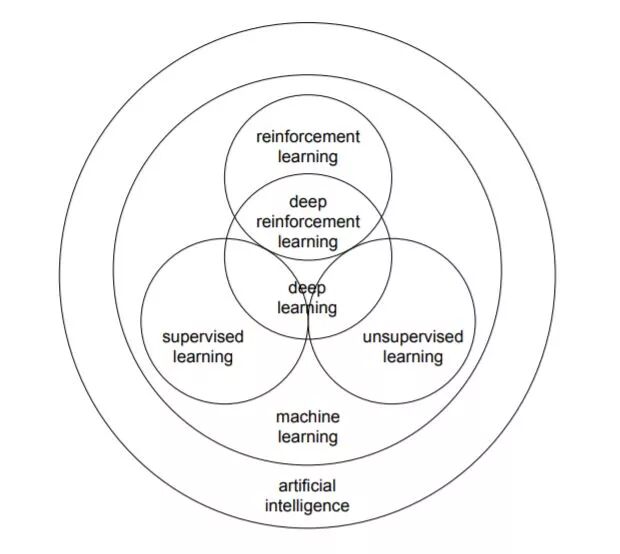
关于深度强化学习,这里有一篇非常详细的综述论文,笔者仅简单介绍一下。在这篇综述中,作者力图回答以下三个问题:1)为什么强化学习要引入深度学习?2)目前深度强化学习最前沿的进展有哪些?3)目前深度强化学习存在哪些问题以及未来可应对的解决方案。

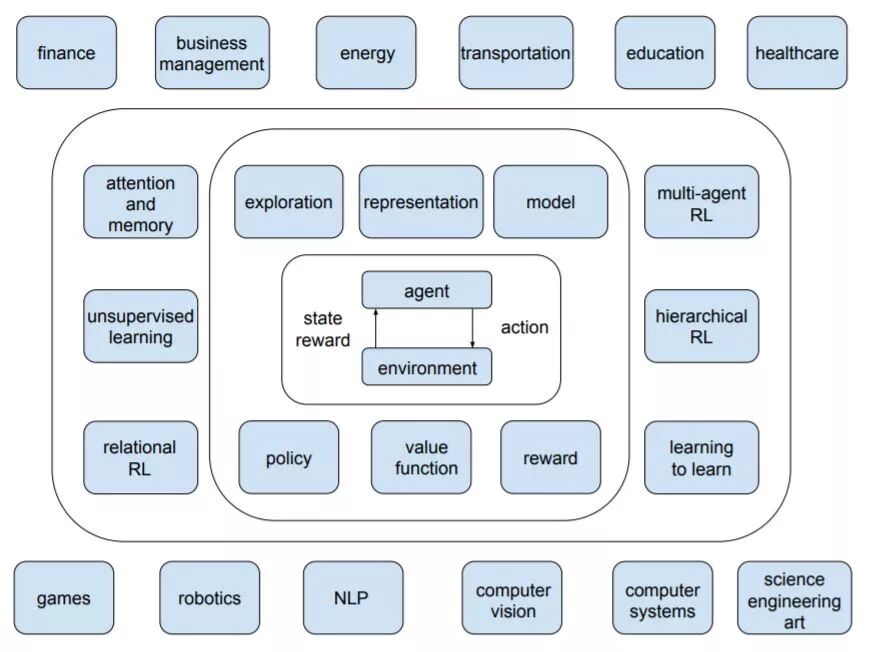
作者在论文中逐步讨论了深度强化学习的 6 个核心元素、6 个重要机制和12个主要的应用场景。6 个核心元素包括值函数 (value function)、策略 (policy)、奖赏 (reward)、模型 (model)、探索与利用 (exploration vs. exploitation)、以及表征 (representation),6 个重要机制包括注意力与存储机制 (attention and memory)、无监督学习 (unsupervised learning)、层次强化学习 (hierarchical RL)、多智能体强化学习 (multi-agent RL)、关系强化学习 (relational RL)、和元学习 (learning to learn),而12 个应用场景包括游戏 (games)、机器人学 (robotics)、自然语言处理 (natural language processing, NLP)、计算机视觉 (computer vision)、金融 (finance)、商务管理 (business management)、医疗 (healthcare)、教育 (education)、能源 (energy)、交通 (transportation)、计算机系统 (computer systems)、以及科学、工程和艺术 (science, engineering, and art)。可以是对深度强化学习做了非常全面和详尽的介绍。
3
胶囊网络
卷积神经网络在深度学习和计算机视觉应用中都有着举足轻重的地位,可以说CNN是目前深度学习的主流方法了。在CNN这样普遍化的工业应用之后,也许你会思考,我们能否更进一步,构造出性能超越CNN的网络结构?解铃还须系铃人,当年提出CNN的Hinton经过多年研究,在2017年11月提出了著名的胶囊网络(Capsule Nets),并在mnist数据识别任务上取得了迄今为止最优的成绩。本篇笔记笔者先和大家来分析一下CNN的一些缺点,然后再来详细看一下胶囊网络的基本结构和原理。
我们都知道在CNN中池化层是一个伟大的发明,数据经过池化层这样一个下采样过程的处理,能够缩小信息冗余,让网络处理更加有效的信息。但池化层也很粗暴,比如说最大池化处理,丢失了数据中很多有效的信息,降低了图像的空间分辨率。最明显的例子就是CNN很难分辨出两张有着细微差别的输入图像,比如说下图中CNN很难察觉出这只猫是在左边还是在右边。

不同位置的猫
再比如说CNN识别一张人脸的要素在于两只眼睛一张嘴巴和一个鼻子,只要输入图像中有这些元素,CNN都会将其识别为人脸。比如说下面这张图,明显不是正常的人脸,倒是有点像毕加索画中的人脸,CNN也会准确无误的将其识别出来,而不会在乎构成人脸的这些鼻子眼睛之间是以怎样的一种结构来组成人脸的。
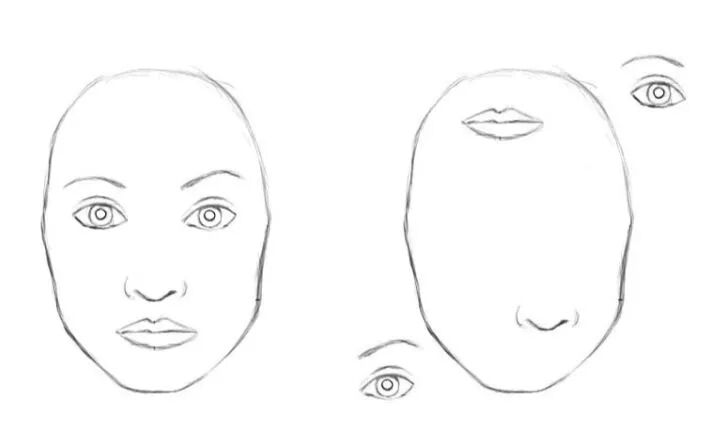
变形的人脸
从CNN的角度看,鼻子歪了或者是眼睛长到嘴巴上去了对于整张图像来说只是微小的变化,不会影响它对输出的判断。Hinton认为:人类在识别图像的时候,神经元是按照一种二叉决策树的形式自上而下的进行判断识别的,而CNN则是通过一层层的网络进行信息过滤和提取来进行集成和抽象形成的,这是CNN与人类思维的最大区别。
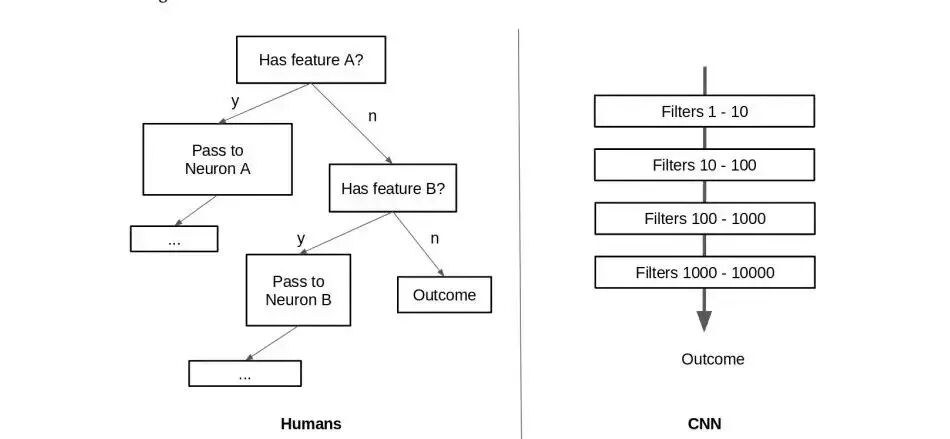
人类的思维 vs CNN的思维
所以总的来说,CNN最大的问题在于其网络内部的各神经元是平等的,没有具体的组织结构能够让CNN来识别出同一张图像内容的不同位置表示。CNN的这些缺点,正是胶囊网络Capsule Nets要做的。
2017年11月,由Sara Sabour、Nicholas Frosst和Geoffrey Hinton发表了一篇名为Dynamic Routing Between Capsules(胶囊间的动态路由)的论文,这篇论文提出了一种新的、不同于此前的CNN网络架构的胶囊网络结构,论文一经公开,在深度学习界引起不小的反响和讨论。

胶囊网络论文摘要
那么究竟什么是胶囊网络呢?简而言之,就是组成胶囊网络的基本元素是一个个的胶囊,而不是神经网络中的神经元。那胶囊又是什么呢?没错,胶囊是由一组神经元构成的,说到底,胶囊网络的最基本单元还是神经元,但是Hinton人为的规定胶囊就是胶囊网络的最小单元。
构成每个胶囊的这样一组神经元,它会学习检测给定区域(例如一个八边形区域)图像的特定目标,输出一个向量(例如一个八维向量),向量的长度代表目标存在的概率估计,而且它对姿态参数(例如精确的位置,旋转,等等)定向编码(例如8D空间)。如果对象有轻微的变化(例如移位、旋转、改变大小等),那么胶囊将输出相同长度但方向略有不同的向量,因而胶囊追求的是等变化(Equivariance),而对应的不能察觉出这种轻微变化的CNN追求的则是不变性(Invariance)。
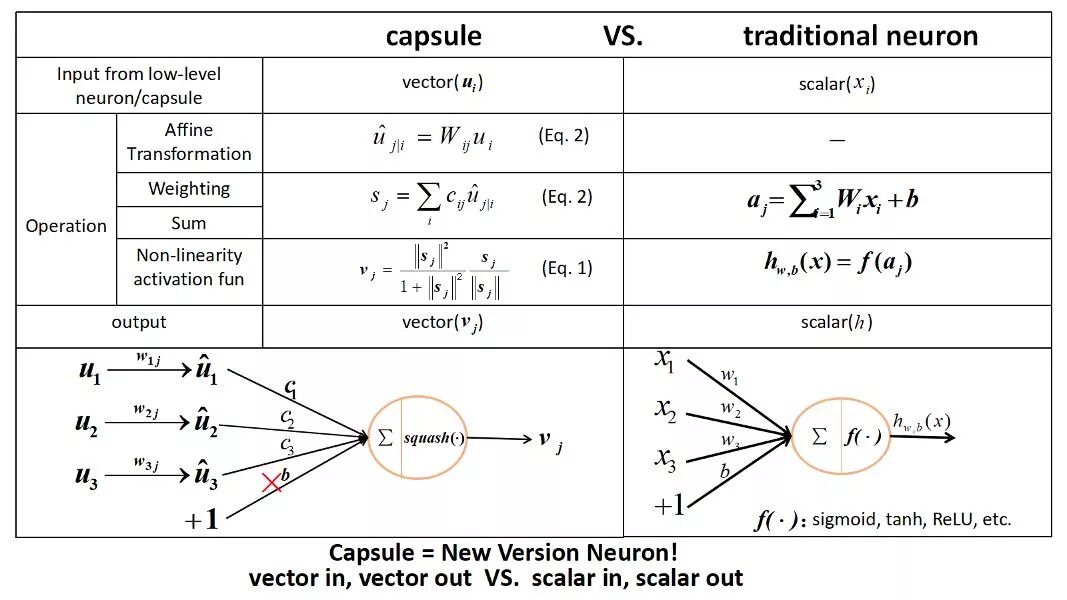
胶囊与传统神经元的区别
跟神经网络一样,胶囊网络同样具有层的概念,一个胶囊网络由多个胶囊层构成,最开始的胶囊层可以称之为基本胶囊层,基本胶囊层直接接受的小区域图像作为输入,假设它试图检测一个特定的对象和姿势,比如一个矩阵或者三角形。而在此之上更高的胶囊称之为路由胶囊(Routing Capsule),路由胶囊用来检测更为复杂的或者更大的物体。
基本胶囊层就是用我们之前很熟悉的卷积层来实现,所以这里不做赘述。但路由胶囊层就不一样了,这也正是整个胶囊网络的特殊之处。路由胶囊层采用了一种叫做routing-by-agreement(路由协议)的算法来检测物体对及其姿态。
我们以Aurélien Géron提供的胶囊网络PPT作为讲解范例。假设有两种基本胶囊:一种是长方形胶囊,一种是三角形胶囊,假设它们都发现了要检索的东西,矩形和三角形都可以是房子或船的一部分。给定矩形的姿态,它会稍微向右旋转,房子和船也会稍微向右旋转。考虑到三角形的位置,房子几乎是上下颠倒的,而船会稍微向右旋转。形状和整体与部分关系都是在训练中学习的。矩形和三角形在船的姿势上是一致的,而在房子的姿势上是完全不同的。所以很可能矩形和三角形是同一条船的一部分,而不是房子。
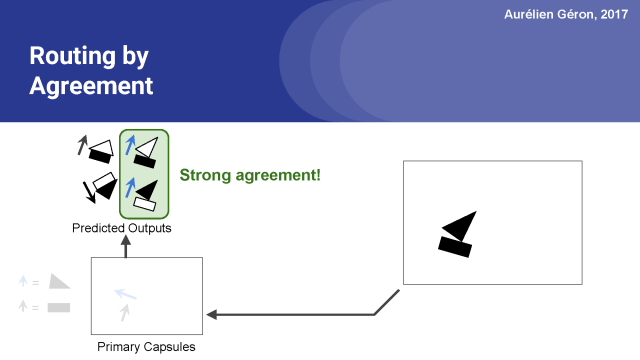
路由协议
既然如此,我们知道了矩形和三角形是船的一部分,矩形胶囊和三角胶囊的输出也就是只关注船胶囊,所以就没有必要发送这些输出到任何其他胶囊,这就是路由协议在这个例子上的含义。
多层胶囊构成的胶囊网络结构示意图如下所示:
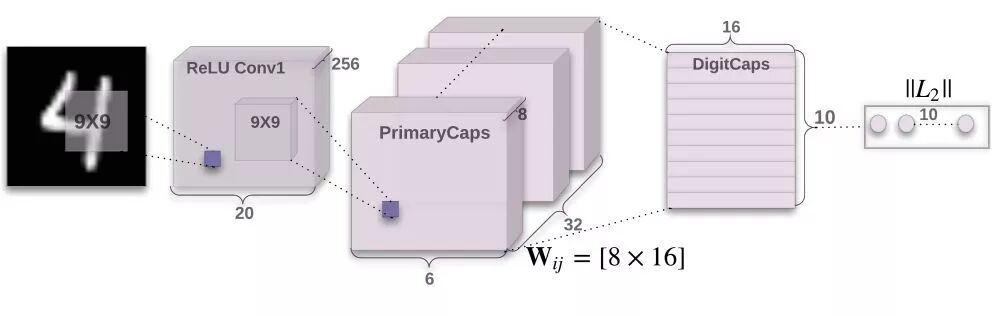
胶囊网络
下图是胶囊网络在mnist数据集上的效果,包括对手写数字多个维度的刻画:
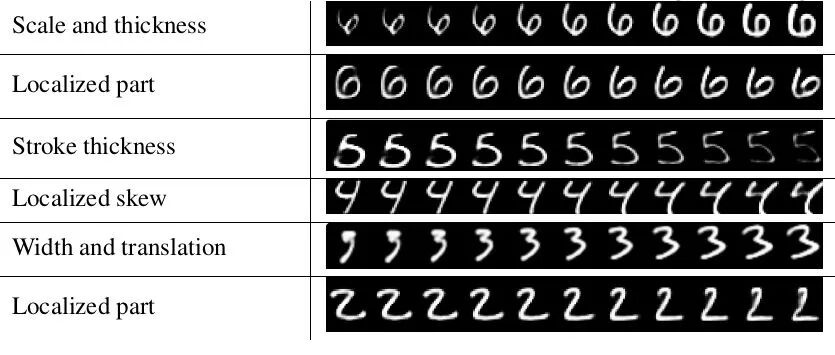
胶囊网络在mnist数据集上的效果
胶囊网络在mnist整体识别任务上达到了99.75%的准确率,可以说是创了mnist识别任务的历史新高了。在mnist重叠数字识别上,胶囊网络也能够很好的区分出重叠的数字。

胶囊网络在mnist重叠数据上的效果
以上便是本讲内容。
本节是一个大杂烩,在讲完深度学习的主流方法和应用之后小编和大家分享的一个延伸性的内容。主要包括图像的神经风格迁移、深度强化学习以及Hinton的胶囊网络。旨在让大家了解深度学习的一些扩展性的内容。下一讲将是咱们深度学习笔记系列的最后一讲,小编会和大家来捋一捋深度学习中常用的框架。咱们下一期见!
【参考资料】
深度卷积网络 原理与实践 彭博
A Neural Algorithm of Artistic Style
Neural Style Transfer: A Review
https://github.com/ycjing/Neural-Style-Transfer-Papers
https://morvanzhou.github.io/tutorials/machine-learning/reinforcement-learning
https://github.com/MorvanZhou/Reinforcement-learning-with-tensorflow
DEEP REINFORCEMENT LEARNING
https://zhuanlan.zhihu.com/p/21421729
Dynamic Routing Between Capsules
https://github.com/naturomics/CapsNet-Tensorflow
https://jhui.github.io/2017/11/03/Dynamic-Routing-Between-Capsules/
https://zhuanlan.zhihu.com/p/33556066
http://www.sohu.com/a/206548662_473283
鲁伟,狗熊会人才计划一期学员。目前在杭州某软件公司从事数据分析和深度学习相关的研究工作,研究方向为贝叶斯统计、计算机视觉和迁移学习。

识别二维码,查看作者更多精彩文章
识别下方二维码成为狗熊会会员!
友情提示:
个人会员不提供数据、代码,
视频only!
个人会员网址:http://teach.xiong99.com.cn






