随着春节脚步的临近,想必各位都已经开始规划幸福的春节长假该如何度过。阖家团聚,探亲访友,与好久没见的好基友一起谈天说地,怼天怼地,想想都是让人感到幸福。

除此之外,每年的春节档电影都会如约而至与大家见面,春节档诞生了许多的经典电影,2019 的春节档电影也是佳片云集,被称作“史上最强春节档”。今天我们就带大家一起用数据去解读其中最值得看的影片。
本次我们的数据主要来源于猫眼,一部分是猫眼的实时预售票房数据:
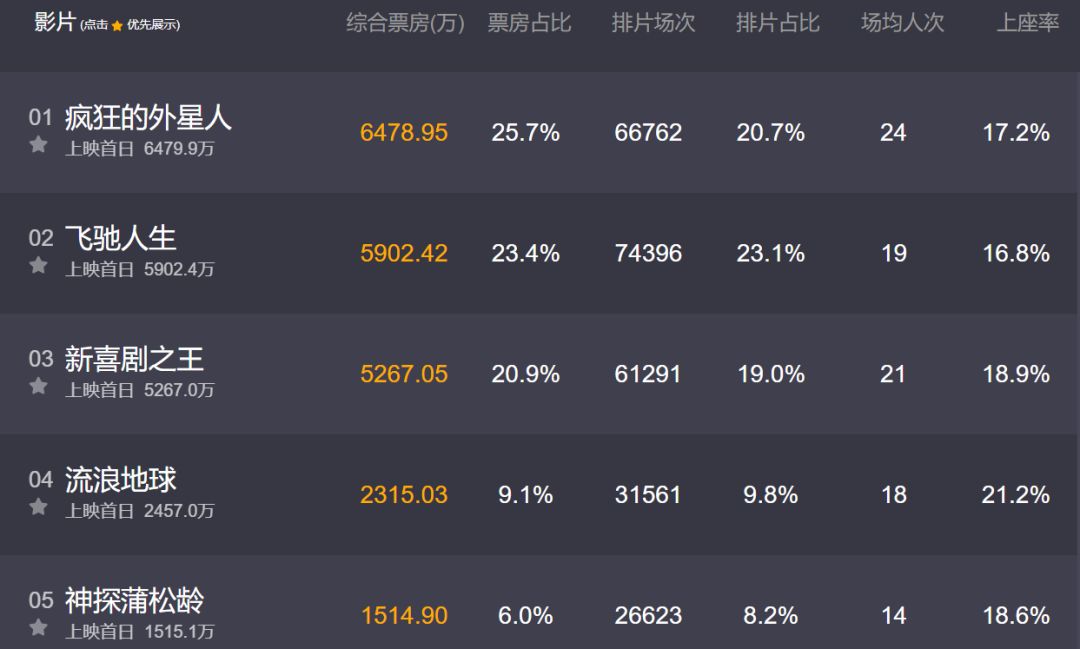
这部分数据可以通过 selenium 去获取,代码如下:
driver = webdriver.Chrome()
driver.maximize_window()
driver.close()
driver.switch_to_window(driver.window_handles[0])
url = 'https://piaofang.maoyan.com/dashboard?date=2019-02-05'
js='window.open("'+url+'")'
driver.execute_script(js)
driver.close()
driver.switch_to_window(driver.window_handles[0])
另一部分数据则来源于猫眼的观众评论。由于电影目前都还没有上映,观众评论给出的分数,表示了其对电影的期待值。
需要注意的是,有许多观众在评论中并没有给出评分,会直接显示为 0,在后续计算时需要排除。
数据如下:
参考代码如下:
tomato = pd.DataFrame(columns=['date','score','city','comment','nick'])
for i in range(0, 1000):
j = random.randint(1,1000)
print(str(i)+' '+str(j))
try:
time.sleep(2)
url= 'http://m.maoyan.com/mmdb/comments/movie/1212592.json?_v_=yes&offset=' + str(j)
html = requests.get(url=url).content
data = json.loads(html.decode('utf-8'
))['cmts']
for item in data:
tomato = tomato.append({'date':item['time'].split(' ')[0],'city':item['cityName'],
'score':item['score'],'comment':item['content'],
'nick':item['nick']},ignore_index=True)
tomato.to_csv('西虹市首富4.csv',index=False)
except:
continue
衡量一个电影关注度的重要方法就是去看首日的预售情况,我们此次选取八部春节档最主要的影片进行对比,代码如下:
p-ggplot(data[order(data$sale,decreasing = T),][1:8,],
aes(x=reorder(name,sale),y=sale,fill=name))+
geom_bar(stat='identity',width = 0.5)+
geom_image(aes(x=name,y=0,image=image),size=0.08)+
geom_text(aes(x=name,y=2500,label=label_sale),size
= 7,col='black',fontface='bold')+
ggtitle('春节档电影预售票房排名(万)') + theme_economist()+ scale_fill_tableau()+
theme(axis.text.x = element_blank(),
axis.text.y = element_blank(),
plot.title = element_text(hjust=0.5,size=30),
panel.grid = element_blank(),
legend.position = 'none',
panel.background = element_blank(),
axis.title = element_blank(),
axis.line = element_blank(),
axis.ticks = element_blank()
)+coord_flip()+ylim(0,6500)
ggsave("春节档上映前预售排名.png", p, width = 10, height = 16)
看一下最终的结果:
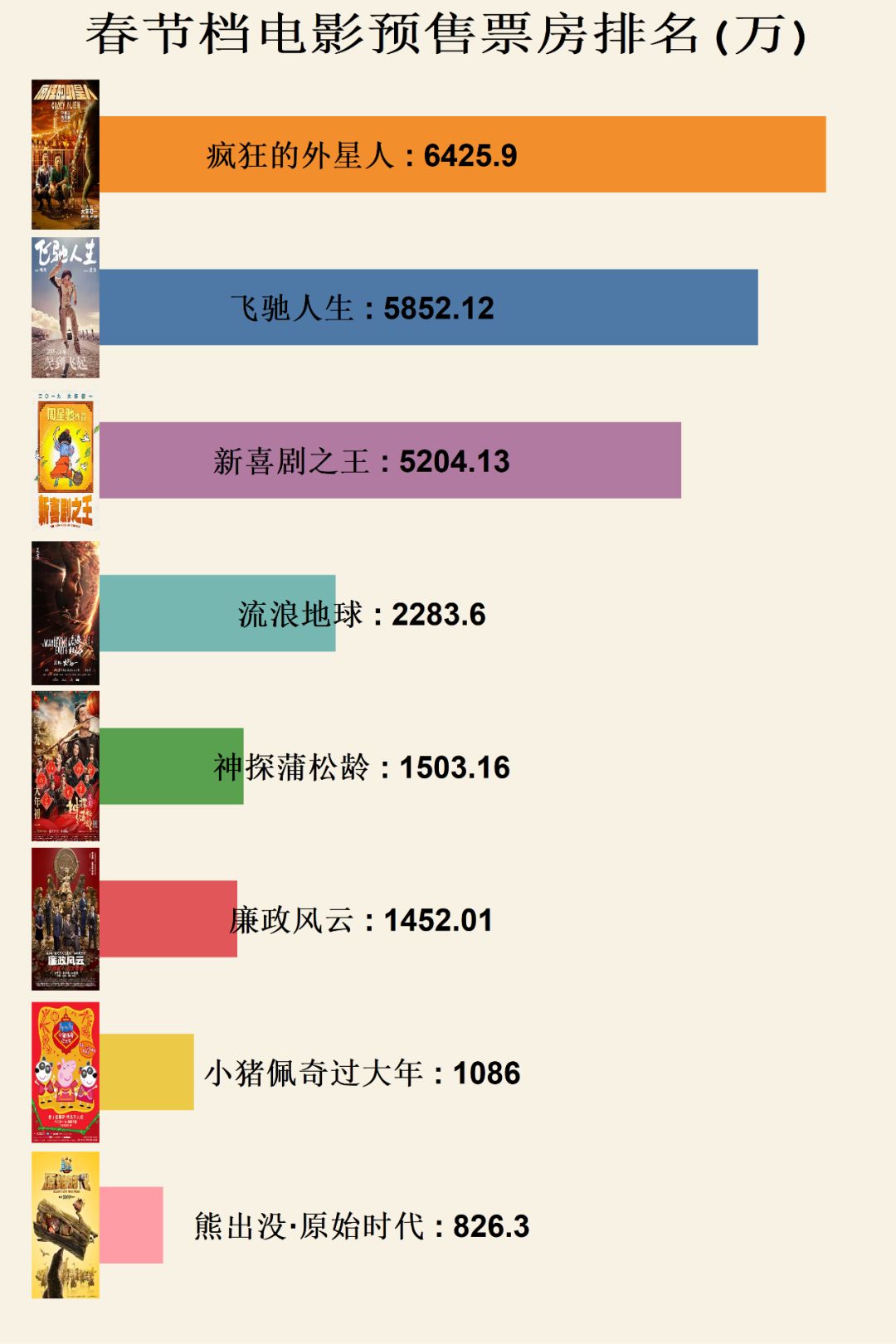
目前预售排名前三位的都是喜剧题材,看来在春节的时候大家还是更加希望能够放松自己,看一下轻松题材的影片。
但是预售票房并不能完全决定最终的票房走势,可以参考之前上映后口碑崩塌的《地球最后的夜晚》和《爱情公寓》。
排名前两位的影片都有沈腾的参与,看来目前沈腾的票房认可度还是不错的,希望两部影片最终都能取得不错的结果。
从预售票房上看,《廉政风云》和《神探蒲松龄》都有比较大的扑街危险,考虑到港片近期略显低迷的表现,希望这两部影片能够带来一些惊喜。
另外我们也看一下上映之前,观众对于影片的整体评价情况,这也会在一定程度上体现观众的期待值。
代码如下:
p-ggplot(data[order(data$score,decreasing = T),][1:8,],
aes(x=reorder(name,score),y=score,fill=name))+
geom_bar(stat='identity',width = 0.5)+
geom_image(aes(x=name,y=0,image=image),size=0.08)+
geom_text(aes(x=name,y=2,label=label_score),size = 7,col='black',fontface='bold')+
ggtitle('春节档电影上映前评价') + theme_wsj()+ scale_fill_tableau()+
theme(axis.text.x = element_blank(),
axis.text.y = element_blank(),
plot.title = element_text(hjust=0.5,size=30),
panel.grid = element_blank(),
legend.position = 'none',
panel.background = element_blank(),
axis.title = element_blank(),
axis.line = element_blank(),
axis.ticks = element_blank()
)+coord_flip()+ylim(0,5)
ggsave("春节档上映前评分排名.png", p, width = 8, height = 12)
看一下最终的结果:

《熊出没》出人意料的在评分中排在首位,这也一定程度上提高了笔者对这部影片的期待值,虽然以笔者的年龄,应该是不适合去看这部影片。
《小猪佩奇》凭借此前的超强营销,成功引起了大家的注意,然而最终表现如何,还是需要上映后接受观众的检验。
同时我们看到成龙大哥领衔的《神探蒲松龄》在评分上要落后于其他影片,看来大家对于这类题材的影片持保留意见比较多一些,我们也期待上映后口碑是否能够实现翻盘。
我们最后通过评论去挖掘上映前大家比较关注的点,主要采用 jieba 分词,需要注意的是,我们需要在分词前增加一些自定义词典。
比如“黄景瑜”,如果不加这个自定义词典,就会被分为“黄景”,之后我们会根据词语出现频率筛选出重要的关键词:
def key_words(df):
comment_str = ' '.join(df)
words_list = []
jieba.load_userdict('spring_film_dict.txt')
word_generator = jieba.cut(comment_str)
for word in word_generator:
words_list.append(word)
words_list = Counter([k for k in words_list if len(k)>1])
return list(dict(words_list.most_common(30)).keys())
最后我们在每个影片中选取了五个能够体现其看点的词语,并进行可视化:

我们选取一些比较有趣的看点组合,进行一下深刻(suixing)解读:
《神探蒲松龄》:大家都在期待成龙大哥的表演,虽然有很多人提前给其打上了“烂片”的标签,但是依然期待影片口碑的翻盘。同时大家也会认真关注影片特效,不知是否会致敬此前 5 毛钱“duang”的特效。
-
《飞驰人生》《疯狂的外星人》:感觉沈腾大有承包今年春节档的态势,预售排名前两位影片中,观众最关注的看点都是沈腾,期待沈腾春节霸屏同时也能收获不错的口碑。
沈腾又是和外星人打交道,又是要体验飞驰的人生,喜欢沈腾的观众在春节档可以大饱眼福了。
《小猪佩奇过大年》:一部适合孩子观看的影片,也是一部宣传片获得极大讨论度的影片,希望不要步此前《地球最后的夜晚》上映后口碑崩盘的后尘。
《新喜剧之王》:显然大部分观众对这部影片的期待来自于星爷,有了此前经典版的《喜剧之王》珠玉在前,《新喜剧之王》不可避免地会被哪来与原作对比,我们期待能够简直有一部经典的影片出现。
最后提前祝愿大家新年愉快,体会与家人团聚的幸福同时也能看到精彩的影片!同时也可以在留言区与我们互动,分享自己春节档会选择去观看的影片。
作者:徐麟
简介:目前就职于互联网公司数据部,哥大统计数据狗,从事数据挖掘&分析工作,喜欢用 R&Python 玩一些不一样的数据。
编辑:陶家龙、孙淑娟
出处:转载自微信公众号:数据森麟(shujusenlin),知乎同名专栏作者。

有赞官宣996工作制:平衡不好可以离婚!
那天,我无意间瞟了眼程序员的桌面……
从10秒到2秒!ElasticSearch性能调优实践







