
大数据文摘出品
来源:Medium
编译:李雷、笪洁琼、Aileen、ZoeY
今天是大年初三,按照传统习俗,从这天开始,就要开始走亲访友了。这时候的商场、饭馆也都是“人声鼎沸”,毕竟走亲戚串门必不可少要带点礼品、聚餐喝茶。
热闹归热闹,这个时候最难的问题可能就是怎样从小区、商场、菜市场的人山人海里准确定位,找到一个“车位”。

别慌!
一位名叫Adam Geitgey的软件工程师、AI软件工程博主也被“停车难”的问题困扰已久。为了让自己能给迅速定位空车位,他用实例分割模型Mask R-CNN和python写了一个抢占停车位的小程序。
以下是作者以第一人称给出的教程,enjoy。
我住在一个大都市,但就像大多数城市一样,在这里很难找到停车位。停车场总是停得满满的,即使你自己有私人车位,朋友来访的时候也很麻烦,因为他们找不到停车位。
我的解决方法是:
用摄像头对着窗外拍摄,并利用深度学习算法让我的电脑在发现新的停车位时给我发短信。

这可能听起来相当复杂,但是用深度学习来构建这个应用,实际上非常快速和简单。有各种现有的实用工具 - 我们只需找到这些工具并且将它们组合在一起。
现在,让我们花几分钟时间用Python和深度学习建立一个高精度的停车位通知系统吧!
当我们想要通过机器学习解决一个复杂的问题时,第一步是将问题分解为简单任务的列表。然后,对于每个简单任务,我们可以从机器学习工具箱中找寻不同的工具来解决。
通过将这些简单问题的解决方案串起来形成框架(例如下面的思维导图),我们将实现一个可以执行复杂操作的系统。
以下就是我如何将检测公共停车位的问题分解并形成流程:

机器学习模型流程的输入是来自对着窗外的普通网络摄像头的视频:

我的摄像头拍下的视频类似上图
我们将每一帧视频送入模型里,一次一帧。
流程的第一步是检测视频帧中所有可能的停车位。显然,我们需要知道图像的哪些部分是停车位才能检测到哪些停车位是空的。
第二步是识别每帧视频中所有的汽车,这样我们可以跟踪每辆车在帧与帧之间的位移。
第三步是确定哪些停车位上目前有汽车,哪些没有。这需要综合第一步和第二步的结果。
最后一步是在停车位空出来的时候发送通知。这是基于视频帧之间的汽车位置的变化。
我们可以使用各种技术以多种不同方式完成这些步骤。构建流程的方法不是唯一的,不同的方法没有对错,但有不同的优点和缺点。现在让我们来看看每一步吧!
以下是相机拍到的图像:

我们需要能够扫描该图像并返回可以停车的区域列表,如下所示:

街区上可用的停车位
有一种偷懒的方法是手动将每个停车位的位置编入到程序中,而不是自动检测停车位。但是如果我们移动相机或想要检测不同街道上的停车位时,我们必须再次手动输入停车位的位置。这太不爽了,所以让我们找到一种自动检测停车位的方法。
一个想法是寻找停车计费表并假设每个计费表旁边都有一个停车位:

在图片中检测的停车计费表
但这种方法存在一定的问题。首先,并非每个停车位都有停车咪表 – 实际上,我们最感兴趣的是找到免费停车位!其次,停车咪表的位置并不能确切地告诉我们停车位的具体位置,只能让我们离车位更接近一点。
另一个想法是建立一个物体检测模型,寻找在道路上绘制的停车位斜线标记,如下所示:

留意那些微小的黄色标记,这些是在道路上绘制每个停车位的边界。
但这种做法也很痛苦。首先,我所在城市的停车位斜线标记非常小,从远处很难看清,电脑也难以察觉。第二,街道上到处都是各种不相关的线条和标记,所以要区分哪些线条是停车位,哪些线条是车道分隔线或人行横道是很困难的。
每当遇到一个看似困难的问题时,请先花几分钟时间看看是否能够采用不同的方式来避免某些技术难点并解决问题。到底什么是停车位呢?停车位就是车辆停留很长一段时间的地方。因此也许我们根本不需要检测停车位。为什么我们不能只检测那些长时间不动的车并假设它们停在停车位上?
换句话说,真正的停车位只是容纳了非移动中的车辆的区域:

这里每辆车的边框实际上都是一个停车位!如果我们能够检测到静止的汽车,就不需要真的去检测停车位。
因此,如果我们能够检测到汽车并找出哪些汽车在视频的每帧之间没有移动,我们就可以推断停车位的位置。这就变得很容易了!
检测视频每帧中的汽车是一个标准的对象检测问题。我们可以使用许多种机器学习方法来检测图像中的对象。以下是一些从过去到现在最常见的对象检测算法:
训练一个HOG(梯度方向直方图)物体探测器滑过(扫描)我们的图像以找到所有的汽车。这种比较古老的非深度学习方法运行起来相对较快,但它对于朝向不同方向的汽车不能很好地处理。
训练CNN(卷积神经网络)物体探测器阅览(扫描)我们的图像,直到我们找到所有的汽车。这种方法虽然准确,但效率不高,因为我们必须使用CNN算法多次扫描同一图像才能找到其中的所有汽车。虽然它可以很容易地找到朝向不同方向的汽车,但它需要比基于HOG的物体探测器更多的训练数据。
使用更新的深度学习方法,如Mask R-CNN,快速R-CNN或YOLO,将CNN的准确性与巧妙设计和效率技巧相结合,可以大大加快检测过程。即使有大量训练数据来训练模型,这种方法的速度也相对较快(在GPU上)。
一般来说,我们希望选择最简单的解决方案,以最少的训练数据完成工作,而不是最新、最花哨的算法。但在这种特殊情况下,Mask R-CNN对我们来说是一个比较合理的选择,尽管它相当花哨新潮。
Mask R-CNN架构的设计理念是在不使用滑动窗口方法的情况下以高计算效率的方式检测整幅图像上的对象。换句话说,它运行得相当快。使用最新GPU,我们可以以每秒几帧的速度检测高分辨率视频中的对象。那对于这个项目来说应该没问题。
此外,Mask R-CNN对每个检测到的对象给出了大量信息。大多数对象检测算法仅返回每个对象的边界。但Mask R-CNN不仅会给我们每个对象的位置,还会给我们一个对象轮廓(或概述),如下所示:

为了训练Mask R-CNN,我们需要大量的包含我们想要检测的对象的图片。我们可以去拍摄汽车照片并检测这些照片中的所有汽车,但这需要几天的工作。幸运的是,汽车是许多人想要检测的常见物体,因此已经有不少汽车图像的公共数据集。
其中一个名为COCO (Common Objects in Context)的流行数据集,其中包含标注了对象轮廓的图像。在此数据集中,有超过12,000张做了标注的汽车图像。以下是COCO数据集中的其中一张:

COCO数据集中的图像,其中已经标出了对象。
这个数据集非常适合训练Mask R-CNN模型。
等等,还有更好的事!由于太多人使用COCO数据集构建对象检测模型,很多人已经完成并共享了他们的结果。因此,我们可以从预先训练好的模型开始,而无需训练我们自己的模型,这种模型可以即插即用。对于这个项目,我们将使用来自Matterport的大型开源Mask R-CNN实现项目,它自带预先训练的模型。
旁注:不要害怕训练一个定制的Mask R-CNN目标探测器!注释数据是很费时,但并不难。
如果我们在摄像头拍摄的图像上运行预先培训过的模型,就会得到如下的结果:

在我们的图像上,识别出了COCO数据集中的默认对象-汽车、人、交通灯和一棵树。
我们不仅能识别汽车,还能识别交通灯和人。幽默的是,其中一棵树被识别成一个“盆栽植物”。
对于图像中检测到的每一个物体,我们从Mask R-CNN模型中都会得到以下四个数据:
1.检测到的对象类型(以整数形式表示)。经过预先训练的COCO模型知道如何检测80种不同的常见物体,如汽车和卡车。这是80种的常见物体的完整清单https://gist.github.com/ageitgey/b143ee809bf08e4927dd59bace44db0d。
2.目标检测的置信度得分。数值越高,模型就越确定它正确地识别了对象。
3.图像中对象的边界框,以X/Y像素位置表示。
4.位图图层告诉我们边界框中的哪些像素是对象的一部分,哪些不是。通过图层数据,我们还可以计算出对象的轮廓。
下面是使用Matterport’s Mask R-CNN中的预培训模型和OpenCV共同实现汽车边界框检测的Python代码:
当您运行该代码时,会看到图像上每辆被检测到的汽车周围都有一个边框,如下所示:

被检测到的每辆汽车周围都有一个绿色的边框。
您还可以在控制台中查看每个被检测到的汽车的像素坐标,如下所示:
Cars found in frame of video:
Car: [492 871 551 961]
Car: [450 819 509 913]
Car: [411 774 470 856]
有了这些数据,我们已经成功地在图像中检测到了汽车。可以进行下一步了!
我们知道图像中每辆车的像素位置。通过连续查看多帧视频,我们可以很容易地确定哪些车辆没有移动,并假设这些区域是停车位。但我们如何检测汽车何时离开停车位呢?
主要问题是,我们的图像中汽车的边界框有部分重叠:

即使对于不同停车位的汽车,每辆车的边界框也有一点重叠。
因此,如果我们假设每一个边界框中的都代表一个停车位,那么即使停车位是空的,这个边界框也可能有一部分被汽车占据。我们需要一种方法来测量两个对象重叠的程度,以便检查“大部分是空的”的边框。
我们将使用交并比(Intersection Over Union ,IoU)方法。用两个对象重叠的像素数量除以两个对象覆盖的像素总数量,如下所示:
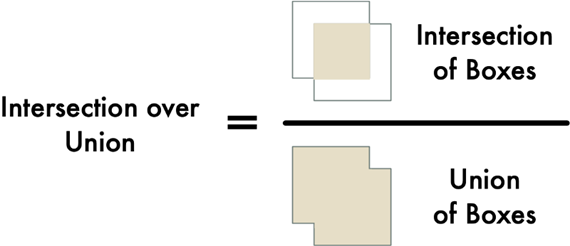
IoU可以告诉我们汽车边界框与停车位边界框的重叠程度。有了这个指标,我们就可以很容易地确定一辆车是否在停车位。如果IoU测量值很低,比如0.15,这意味着这辆车并没有占用太多的停车位。但是如果测量值很高,比如0.6,这意味着汽车占据了大部分的停车位,那么我们可以确定停车位被占用了。
由于IoU在计算机视觉中是一种常见的度量方法,所以通常您使用的库已经有相关实践。事实上,Matterport Mask R-CNN库中就有这样的函数mrcnn.utils.compute_overlaps(),我们可以直接调用这个函数。
假设在图像中有一个表示停车区域的边界框列表,那么检查被检测到的车辆是否在这些边界框中,就如同添加一行或两行代码一样简单。
结果如下:
[
[1. 0.07040032 0. 0.]
[0.07040032 1. 0.07673165 0.]
[0. 0. 0.02332112 0.]
]
在这个二维数组中,每一行表示一个停车位的边界框。相应的,每列表示该停车位与被检测到的汽车有多少重叠。1.0分意味着汽车完全占据了停车位,而0.02分这样的低分意味着汽车只是接触了停车位边界框,但并没有占据很多区域。
为了找到空置的停车位,我们只需要检查这个数组中的每一行。如果所有的数字都是零或者非常小的数字,就意味着没有东西占据了这个空间,因此它就是空闲的!
但请记住,物体检测并不总是与实时视频完美结合。尽管Mask R-CNN非常准确,但偶尔它会在一帧视频中错过一两辆车。因此,在将停车位标记为空闲之前,我们应该确保它在一段时间内都是空闲的,可能是5或10帧连续视频。这将防止仅仅在一帧视频上出现暂时性的物体检测问题而误导系统将停车位判定为空闲。但当我们看到至少有一个停车位在连续几帧视频图像中都被判定为空闲,我们就可以发送短信了!
最后一步是当我们注意到一个停车位在连续几帧视频图像中都被判定为空闲时,就发送一条短信提醒。
使用 Twilio从Python发送短消息非常简单。Twilio是一个流行的接口,它可以让您用几行代码从任何编程语言发送短消息。当然,如果您喜欢使用其他的短信服务提供者,也是可以的。我和Twilio没有利害关系。只是第一个就想到了它。
Twilio:
https://www.twilio.com
要使用Twilio,需要注册试用帐户,创建Twilio电话号码并获取您的帐户凭据。然后,您需要安装Twilio Python客户端的库:
pip3 install twilio
安装后,使用下面的代码(需要将关键信息替换成您的账户信息),就可以从Python发送短信了:
from twilio.rest import Client
twilio_account_sid = 'Your Twilio SID here'
twilio_auth_token = 'Your Twilio Auth Token here'
twilio_source_phone_number = 'Your Twilio phone number here'
client = Client(twilio_account_sid, twilio_auth_token)
message = client.messages.create(
body="This is my SMS message!",
from_=twilio_source_phone_number,
to="Destination phone number here"
)
直接将代码插入到我们的脚本里,就可以添加发送短信的功能了。但我们需要注意的是,如果一个停车位一直是空闲的,就不需要在每一帧视频都给自己发送短信了。因此,我们需要有一个标志来标记我们是否已经发送了一条短信,并确保在经过一定时间或检测到其他停车位空闲之前,我们不会再发送另一条短信息。
我们将流程中的每个步骤写成了一个单独的Python脚本。以下是完整的代码:
此部分代码太长,感兴趣的同学可以在下面的网址中找到:
https://medium.com/@ageitgey/snagging-parking-spaces-with-mask-r-cnn-and-python-955f2231c400
要运行此代码,您需要首先安装Python 3.6+, Matterport Mask R-CNN和OpenCV。
Matterport Mask R-CNN:
https://github.com/matterport/Mask_RCNN
OpenCV:
https://pypi.org/project/opencv-python/
我有意让代码尽可能简明扼要。例如,它只是假设在第一帧视频中出现的任何汽车都是已停放的汽车。试试修改代码,看看您能不能提高它的可靠性。
不用担心修改此代码就不能适应不同的场景。只需更改模型搜寻的对象ID,就可以将代码完全转换为其他内容。例如,假设您在滑雪场工作。通过一些调整,您可以将此脚本转换为一个自动检测滑雪板从斜坡上跳下的系统,并记录炫酷的滑雪板跳跃轨迹。或者,如果您在一个游戏保护区工作,您可以把这个脚本变成一个用来计数在野外能看到多少斑马的系统。
唯一的限制就是你的想象力。
一起来试试吧!
相关报道:
https://medium.com/@ageitgey/snagging-parking-spaces-with-mask-r-cnn-and-python-955f2231c400








