选自the Gradient
作者:Alan L. Yuille、Chenxi Liu
机器之心编译
深度学习是近年来人工智能技术发展的核心,虽然取得了巨大成功,但它具有明显的局限性。与人类视觉系统相比,深度学习在通用性、灵活性和适应性上要差很多,而在遇到复杂的自然图像时,深度学习可能还会遇到机制性困难。本文中,来自约翰霍普金斯大学的学者们向我们介绍了深度学习的几大极限,以及如何解决这些问题的思路。
研究人员表示,目前形式的深度神经网络似乎不太可能是未来建立通用智能机器或理解思维/人类大脑的最佳解决方案,但深度学习的很多机制在未来仍会继续存在。
本文是《Deep Nets: What have they ever done for Vision?》论文的精简版。
深度学习的历史
我们现在正目睹的是人工智能的第三次崛起。前两波发生在 1950-1960 年代和 1980-1990 年代——当时都产生了相当大的影响,却也都慢慢冷却下来。这是因为当时的神经网络既没有实现本该达成的性能提升,也没有帮助我们理解生物的视觉系统。第三次浪潮:21 世纪初——至今,此次与前两次不同,深度学习在很多基准测试和现实应用上已经大幅超越了生物的能力。虽然深度学习的大多数基本思想在第二次浪潮中已经发展完善,但其能力在大型数据集和计算机算力(特别是 GPU)发展完善之前是无法释放的。
深度学习的沉浮反映了学派的流行,以及不同算法的热度。第二次浪潮让我们在高期待——低成果的发展中看到了经典 AI 的局限性,这就是在 20 世纪 80 年代中期出现 AI 寒冬的原因。第二波浪潮的退却转化为支持向量机、内核方法以及相关方法的崛起。我们被神经网络研究者的成果惊艳,尽管其效果令人失望,但随着时间的发展,它们又再次兴起。今天,我们很难找到与神经网络无关的研究了——这同样也不是一个好的现象。我们不禁有些怀疑:如果人工智能领域的学者们追求更多不同的方法,而不是跟从流行趋势,这个行业或许会发展得更快。令人担忧的是,人工智能专业的学生们经常完全忽略旧技术,只顾追逐新趋势。
成功与失败
在 AlexNet 横空出世之前,计算机视觉社区对于深度学习持怀疑态度。2011 年,AlexNet 在 ImageNet 图像识别竞赛中横扫了所有竞争对手,随后几年,研究人员提出了越来越多性能更好的对象分类神经网络架构。同时,深度学习也很快适应了其他视觉任务,如目标检测,其中图像包含一个或多个物体。在这种任务中,神经网络会对初始阶段的信息进行增强而确定最后的目标类别与位置,其中初始阶段提出了对象的可能位置和大小。这些方法在 ImageNet 前最为重要的目标识别竞赛——PASCAL 目标识别挑战上优于此前的最佳方式,即可变形部件模型(Deformable Part Model)。其他深度学习架构也在一些经典任务上有了很大的提升,如下图:
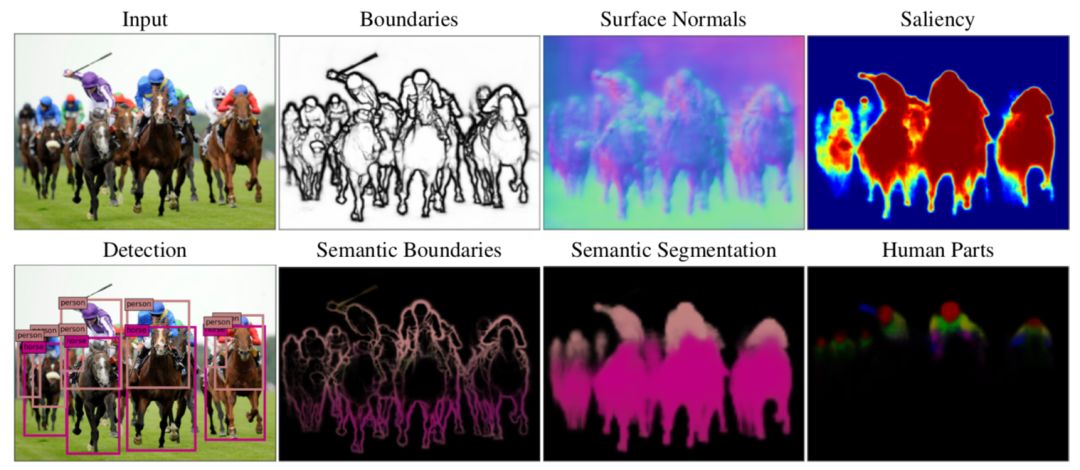
图 1. 深度学习可以执行很多不同视觉任务。其中包括边界检测、语义分割、语义边界、曲面法线、显著度、人体,以及目标检测。
但是,尽管深度学习超越了此前的一些技术,它们却并不能用于通用任务。在这里,我们可以定义出三个主要限制。
首先,深度学习几乎总是需要大量标注数据。这使得计算机视觉的研究者们倾向于解决易于解决——而不是真正重要的问题。
有一些方法可以减少监督的需求,包括迁移学习、few-shot 学习、无监督学习以及弱监督学习。但到目前为止,它们的成就并不如监督学习那样令人印象深刻。
第二,深度学习在基准测试数据集上表现良好,但在数据集之外的真实世界图像上可能表现很差。所有数据集都有自己的偏差。这种偏差在早期视觉数据集中非常明显,研究人员发现神经网络会利用数据集的偏差「投机取巧」,比如利用背景进行判断(如在 Caltech101 中检测鱼曾经非常容易,因为鱼图是唯一以水为背景的图)。尽管通过使用大数据集和深度神经网络可以减少这一现象,但问题仍然存在。
在下图中,深度神经网络在 ImageNet 上训练以识别沙发,但却可能因为示例图片数量不足而无法成功。深度神经网络是偏向于反「特殊情况」的,模型不会太考虑数据集中出现较少的情况。但在现实世界的应用中,这些偏差很成问题,将这样的系统用于视觉检测有可能导致严重后果。例如用于训练自动驾驶汽车的数据集几乎不会包含坐在路中间的婴儿。

图 2:UnrealCV 允许视觉研究人员简单操纵合成场景,比如改变沙发的视角。我们发现 Faster-RCNN 检测沙发的平均精度(AP)在 0.1 到 1.0 范围内,显示出对视角的极度敏感性。这可能是因为训练中的偏差导致 Faster-RCNN 更倾向于特定的视角。
第三,深度网络对图像的改变过于敏感,而这些改变在人类看来可能并不影响对图的判断。深度网络不仅对标准对抗攻击(会导致难以察觉的图像变化)敏感,而且对环境的变化也过于敏感。图 3 显示了将吉他 PS 成雨林中的猴子的效果。这导致深度网络将猴子误识为人类而且将吉他视作鸟,大概是因为拿吉他的更有可能是人类而不是猴子,而出现在雨林里猴子身边的更有可能是鸟而不是吉他。最近的研究给出了很多关于深度网络对环境过于敏感的案例,如将大象放进房间。

图 3:添加遮挡致使深度网络失灵。左:用摩托车进行遮挡后,深度网络将猴子识别为人类。中:用自行车进行遮挡后,深度网络将猴子识别为人类,而且丛林将网络对车把的识别误导为鸟。右:用吉他进行遮挡后,深度网络将猴子识别为人类,而且丛林将网络对吉他的识别误导为鸟。
对背景的过度敏感可以归咎于数据集有限的规模。对于任意的对象,数据集中只能包含有限数量的背景,因此神经网络存在偏好。例如,在早期的图像标注数据集中,我们观察到长颈鹿只会出现在树的附近,因此生成的标注没有提及图像中没有树的长颈鹿,尽管它们是最主要的对象。
对于深度网络等数据驱动型方法来说,捕获背景大量变化的难题以及探索大量噪声因素的需要是一个很大的问题。确保网络可以解决所有这些问题似乎需要无穷大的数据集,这又会给训练和测试数据集带来巨大的挑战。
「大型数据集」还不够大
组合性爆炸
以上所提到的所有问题都未必是深度学习的症结所在,但它们是真正问题的早期信号。也就是说,现实世界中的图像数据集组合起来非常大,因此无论多大的数据集都无法表征现实世界的复杂性。
组合性大是什么意思?想象一下通过从目标字典中选择目标并将它们放在不同的配置中来构建一个可视场景。实现这一任务的方法数量可以达到指数级。即使是含有单个目标的图像也能拥有类似的复杂性,因为我们可以用无数种方法对其进行遮挡。其背景也有无数种变化的可能。
尽管人类能够自然地适应视觉环境中的种种变化,但深度神经网络更加敏感、易错,如图 3 所示。我们注意到,这种组合性爆炸在一些视觉任务中可能不会出现,深度神经网络在医学图像中的应用通常非常成功,因为其背景的变化相对较少(如胰腺和十二指肠总是离得很近)。但是对于许多应用来说,如果没有一个指数级的大型数据集,我们就无法捕捉到现实世界的复杂性。
这一缺陷带来了一些重大问题,因为在有限随机样本上进行训练、测试模型这一标准范式变得不切实际。这些样本量永远无法大到可以表征数据底层分布的程度。因此我们不得不面对以下两个新问题:
1. 在需要庞大数据集才能捕获现实世界组合复杂性的任务中,如何在规模有限的数据集上训练算法才能使其表现良好?
2. 如果只能在有限子集上测试,我们如何才能有效测试这些算法以确保它们在庞大数据集上表现良好?
克服组合性爆炸
从现有形式来看,深度神经网络等方法很可能无法克服组合性爆炸这一难题。无论是训练还是测试,数据集似乎永远不够大。以下是一些潜在的解决方案。
组合性
组合性是一种基本原则,可以诗意地表述为「一种信仰的体现,相信世界是可知的,人类可以拆解、理解并按照自己的意愿重组事物」。此处的关键假设在于,结构是分层的,由更基本的子结构按照一组语法规则组合而成。这意味着,子结构和语法可以从有限的数据中习得,然后泛化到组合的场景中。
与深度网络不同,组合性模型(compositional model)需要结构化的表征,这些表征明确地表明其结构和子结构。组合性模型具备超越所见数据的推理能力,可以推理系统、进行干涉、实施诊断并基于相同的底层知识结构解决许多不同的问题。Stuart Geman 曾说过,「世界是组合的,或者说上帝是存在的,」否则上帝就要手工焊接人类智能了。尽管深度神经网络拥有某种形式的复杂性,如高级特征由来自低级特征的响应组合而成,但这并不是本文中提到的组合性。

图 4:从(a)到(c),可变性递增并使用了遮挡。(c)是一个庞大的组合数据集示例,本质上和验证码相同。有趣的是,关于验证码的研究表明,组合性模型的性能很好,但深度神经网络的表现却很差。
图 4 是关于组合性的一个示例,与合成分析有关。
组合性模型的若干概念优势已经体现在一些视觉问题中,如使用相同的底层模型执行多个任务和识别验证码。其它非视觉示例也表明了相同的论点。尝试训练进行智商测试的深度网络没有取得成功。这一任务的目标是预测一个 3x3 网格中缺失的图像,其它 8 个格子的图像都已给出,任务中的底层规则是组合性的(干扰可以存在)。相反地,对于一些自然语言应用,神经模块网络的动态架构似乎足够灵活,可以捕捉到一些有意义的组合,其性能优于传统的深度学习网络。实际上,我们最近证实,经过联合训练后,各个模块确实实现了它们预期的组合功能(如 AND、OR、FILTER(RED) 等)。
组合性模型有很多理想的理论特性,如可解释、可生成样本。这使得错误更容易诊断,因此它们比深度网络等黑箱方法更难被欺骗。但学习组合性模型很难,因为它需要学习构件和语法(甚至语法的性质也是有争议的)。并且,为了通过合成进行分析,它们需要拥有目标和场景结构的生成模型。除了一些例外,如脸、字母和规则纹理图像,将分布放在图像上很难。
更重要的是,处理组合性爆炸需要学习 3D 世界的因果模型以及这些模型如何生成图像。对人类婴儿的研究表明,他们通过建立预测所处环境结构的因果模型来学习。这种因果理解使他们能够从有限的数据中学习并泛化到新环境中。这类似于将牛顿定律和太阳系的托勒密模型进行对比,牛顿定律以最少的自由参数给出了因果理解,而托勒密模型给出了非常准确的预测,但需要大量的数据来确定其细节。
在组合数据上测试
在现实世界的组合复杂度上测试视觉算法的一个潜在挑战是,我们只能在有限的数据上进行测试。博弈论通过关注最坏的案例而不是一般的案例来解决这个问题。正如我们之前所说的,如果数据集没有捕捉到问题的组合复杂度,那么一般案例在有限大小数据集上的结果可能没有意义。很明显,如果目标是开发用于自动驾驶汽车或医学图像中诊断癌症的视觉算法,那将注意力放在最坏的案例上是有意义的,因为算法的失败会导致严重的后果。
如果能够在低维空间中捕捉故障模式,如立体的危险因素,我们就可以用计算机图形和网格搜索来研究它们。但对于大多数视觉任务,尤其是涉及组合数据的任务来说,很难识别出少数可以被隔离或测试的危险因素。一个策略是将标准对抗攻击的概念扩展到包含非局部结构,这可以通过允许导致图像或场景改变但不会显著影响人类感知的复杂操作(如遮挡或改变被观察物体的物理属性)来实现。将这一策略应用于处理组合数据的视觉算法仍然颇具挑战性。但,如果在设计算法时考虑到了组合性,那它们的显式结构可能使得诊断并确定它们的故障模式成为可能。
小结
几年前,Aude Oliva 和 Alan Yuille(一作)共同组织了一场由美国国家科学基金会资助的计算机视觉前沿研讨会(MIT CSAIL 2011)。会议鼓励大家坦诚交换意见。与会人员对于深度网络在计算机视觉方面的潜力存在巨大分歧。Yann LeCun 大胆预测,所有人都将很快使用深度网络。他的预测是对的。深度网络的成功令人瞩目,还使计算机视觉变得非常热门,大大增加了学界和业界的互动,促使计算机视觉被应用于很多领域并带来很多其它重要的研究成果。即便如此,深度网络还存在巨大挑战,而我们要实现通用人工智能和理解生物视觉系统,就必须克服这些挑战。我们的一些担忧与最近对深度网络的批评中提到的类似。随着研究人员开始在越来越现实的条件下处理越来越复杂的视觉任务,可以说最严峻的挑战是如何开发能够处理组合性爆炸的算法。虽然深度网络会是解决方案的一部分,但我们认为还需要涉及组合原则和因果模型的互补方法,以捕捉数据的基本结构。此外,面对组合性爆炸,我们要再次思考如何训练和评估视觉算法。
原文链接:https://thegradient.pub/the-limitations-of-visual-deep-learning-and-how-we-might-fix-them/
本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者 / 实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告 & 商务合作:bd@jiqizhixin.com










