9 月份,我们两位同学一起组队,参加 Byte Cup 2018 机器学习比赛。本次比赛由中国人工智能学会和字节跳动主办,IEEE 中国代表处联合组织。比赛的任务是文章标题自动生成。最终,我们队伍获得了第一名。
比赛介绍
本次比赛的任务是给定文章文本内容,自动生成标题。本质上和文本摘要任务比较类似。本次比赛有 100 多万篇文章的训练数据。
数据介绍
详细参见:
http://biendata.com/competition/bytecup2018/data/
本次竞赛使用的训练集包括了约 130 万篇文本的信息,验证集 1000 篇文章, 测试集 800 篇文章。
数据处理
评价指标
本次比赛将使用 Rouge(Recall-Oriented Understudy for Gisting Evaluation)作为模型评估度量。Rouge 是评估自动文摘以及机器翻译的常见指标。它通过将自动生成的文本与人工生成的文本(即参考文本)进行比较,根据相似度得出分值。

模型介绍
本次比赛主要尝试了 Seq2Seq的方法。参考的模型包括 Transformer 模型和 pointer-generator 模型。模型如下图:
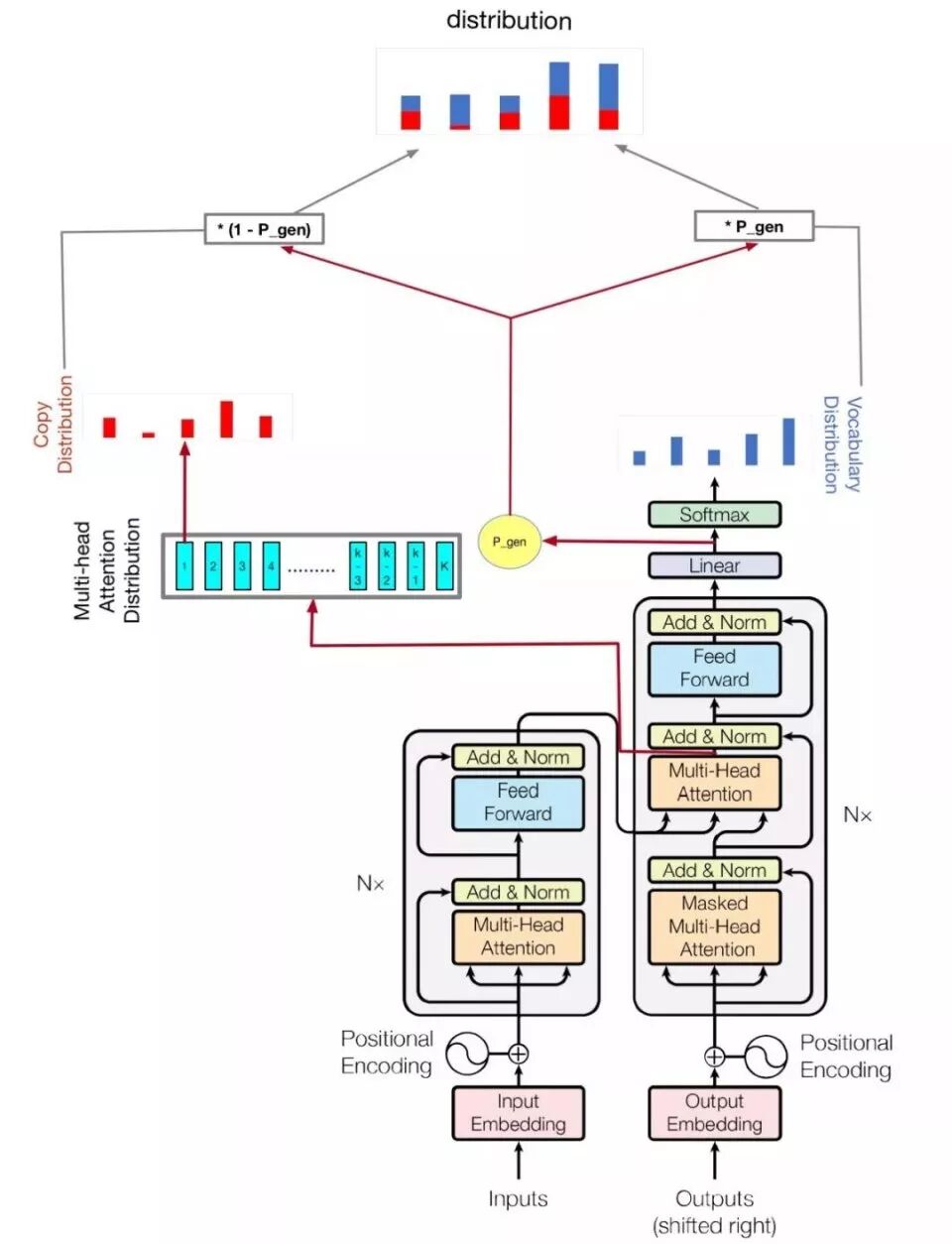
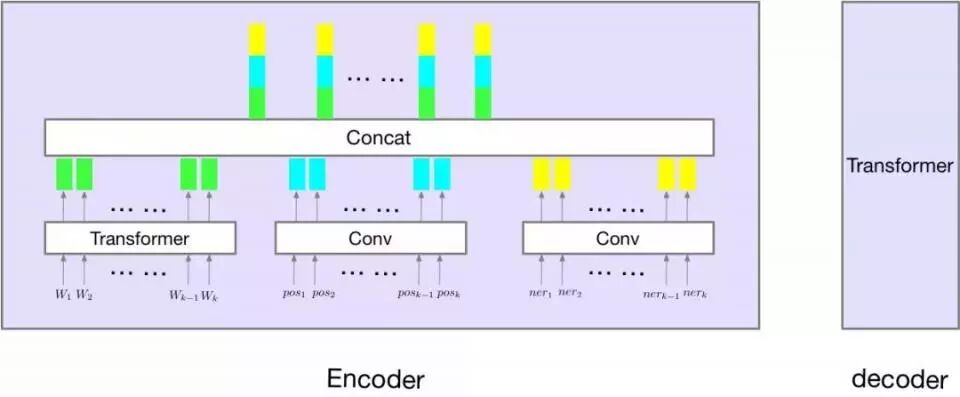
其实就是将 pointer-generator 的 copy 机制加到 Transformer 模型上。同时,尝试了将 ner-tagger 和 pos-tagger 信息加入到模型中,如下图所示:
问题分析
最开始我们尝试了最基本的 Transformer 模型,通过查看数据,遇到以下几类明显错误:
OOV (out of vocabulary);
数字,人名,地名预测错误;
词形预测错误。
OOV 问题的主要原因是数据集词表太大,模型能够实际使用的词表较小;数字,人名,地名预测错误,主要原因是低频词 embedding 学习不充分;词形预测错误,主要原因是模型中没有考虑词的形态问题(当然,如果训练数据足够大,是能避免这个问题的)。
为了解决这些问题,我们尝试了以下方法。
重要组件
Copy机制
对于很多低频词,通过生成式方法生成,其实是很不靠谱的。为此,我们借鉴 Pointer-generator 的方法,在生成标题的单词的时候,通过 Attention 的概率分布,从原文中拷贝词。
Subword
为了避免 OOV 问题,我们采用 subword 的方法处理文本。这样可以将词表大小减小到 20k,同时 subword 会包含一些单词词形结构的信息。
NER-Tagger和POS-Tagger信息
因为 baseline 在数字,人名,地名,词形上预测错误率较高,所以我们考虑能不能将 NER-Tagger 和 POS-Tagger 信息加入到模型中。如上图所示。实验证明通过加入这两个序列信息能够大大加快模型的收敛速度(训练收敛后,指标上基本没差异)。
Gradient Accumulation
在实验过程中,我们发现 Transformer 模型对 batch_size 非常敏感。之前,有研究者在机器翻译任务中,通过实验也证明了这一观点。然而,对于文章标题生成任务,因为每个 sample 的文章长度较长,所以,并不能使用超大 batch_size 来训练模型,所以,我们用 Gradient Accumulation 的方法模拟超大 batch_size。
Ensemble
采用了两层融合。第一层,对于每一个模型,将训练最后保存的 N 个模型参数求平均值(在 valid 集上选择最好的 N)。第二层,通过不同随机种子得到的两个模型,一个作为生成候选标题模型(选择不同的 beam_width, length_penalty), 一个作为打分模型,将候选标题送到模型打分,选择分数最高的标题。
失败的方法
将 copy 机制加入到 Transformer 遇到一些问题,我们直接在 decoder 倒数第二层加了一层 Attention 层作为 copy 机制需要的概率分布,训练模型非常不稳定,并且结果比 baseline 还要差很多;
我们尝试了 BERT,我们将 bert-encoder 抽出的 feature 拼接到我们模型的encoder的最后一层,结果并没有得到提升;
word-embedding 的选择,我们使用 GloVe 和 fastText 等预训练的词向量,模型收敛速度加快,但是,结果并没有 random 的方法好。
结束语
非常感谢主办方举办本次比赛,通过本次比赛,我们探索学习到了很多算法方法和调参技巧。
参考文献
[1] Sennrich, Rico, Barry Haddow, and Alexandra Birch. "Neural machine translation of rare words with subword units." arXiv preprint arXiv:1508.07909 (2015).
[2] Vaswani, Ashish, et al. "Attention is all you need." Advances in Neural Information Processing Systems. 2017.
[3] See, Abigail, Peter J. Liu, and Christopher D. Manning. "Get to the point: Summarization with pointer-generator networks." arXiv preprint arXiv:1704.04368 (2017).
附冠军采访
Q:能否分别介绍一下所有队员的情况?
A:我们队伍包括两位同学,队长姜兴华和队员严雨姗。
队长姜兴华,浙江大学计算机学院计算机专业的研三学生,主要方向为自然语言处理,机器学习等。

队员严雨姗,浙江大学管理学院创业管理专业博一学生,主要研究方向为创业与大数据相关课题。

Q:能否介绍一下学术背景?
A:
队长从本科大三开始接触机器学习,从事过计算机视觉和自然语言处理相关研究工作。研究生导师是蔡登/何晓飞教授。目前研究方向为自然语言处理-文本生成相关。
Q:能否介绍一下参加比赛的经历?
A:这次比赛是我们第一次参加数据竞赛。之前也没什么比赛经验。参加 Byte Cup 2018,主要是觉得该比赛解决的问题非常有趣并且在学术界和工业界都是非常有意义的。
Q:在比赛中做了哪些尝试?遇到了哪些困难?
A:比赛初期我们调研了很多文本生成,机器翻译等相关方向的论文和开源代码,做出了很多尝试。比赛过程中,也遇到了很多问题,包括计算资源不足和代码实现错误等问题。我们的模型是基于 Transformer 模型的改进。比赛中经常遇到的问题就是,Baseline+A,Baseline+B 会有很好的效果,但是 Baseline+A+B 就不能达到同等量级的提升。
同时,调参也遇到了很多的问题,比如:对于不同的模型结构需要使用不同的学习率策略才能达到很好的效果。改进模型是一个不断迭代的过程,新模型,看数据(找到数据明显错误),分析问题,改进模型。
再比如,我们实验过程中,会遇到 OOV (out-of-vocabulary) 问题,数字预测错误,单词词形预测错误,生成语句重复,生成语句长度太短等若干问题,每次迭代,都会在对应问题上得到提升。
Q:以后想在什么具体的领域发展或想解决什么问题?希望做科研还是找工作?如果未来会参加比赛,希望参加什么样的比赛(对参加比赛的标准是什么)?
A:之后,我们主要做自然语言处理相关工作,主要会关注内容生成/创作等方向。预计之后会去工业界从事相关工作,因为工业界有更多的实际场景和数据,相对来说,会比较有成就感一些。










