过完年,压岁钱到位,迟来的年终奖到账,钱包鼓起来但新的节日也不断跟上,情人节、元宵节、妇女节……
说到底,还不是要买买买?
淘宝上的店铺又多又杂乱,一旦买错了,面临的就是“女”朋友的“果真直男审美”的diss,或者人财两空的局面

接下去,来看看用机器学习技术如何甄别优质店铺,让你买到就是赚到!
分三步走:
第一步:找到阿里给出的店铺评价历史信息,分为训练集数据和测试集数据;
第二步:利用训练集数据构建机器学习模型;
第三步:使用测试集数据进行准确率判断并优化。
如此便可以建立一个相对科学的靠谱店铺预测模型。

首先,从阿里云天池开一份包含2000家店铺的评分,等级,评论等信息和数年交易记录的数据:
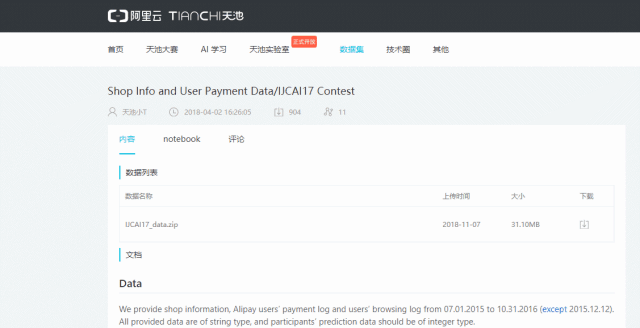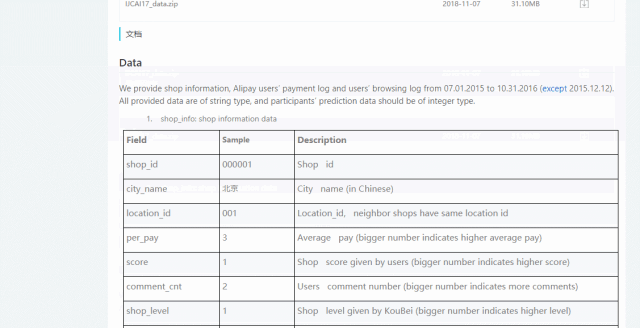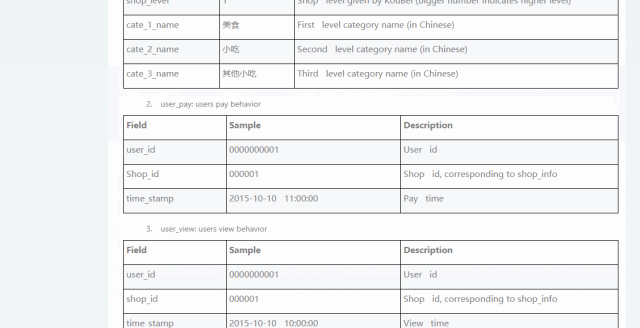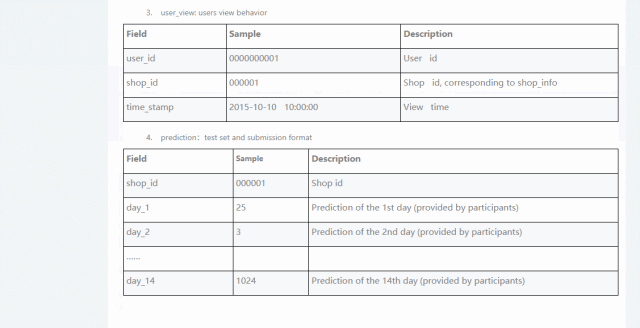
通过这份数据,我们可以构建一套模型,根据店铺的访问、购买信息等数据,来评测该店铺是否为优质店铺。
一部分数据将用来作为训练集,另一部分数据会用来测试已经训练好模型的精确度。但训练的时候并不是精确度越高越好,过拟合和欠拟合都不是好事情。
欠拟合指模型没有很好地捕捉到数据特征,不能够很好地拟合数据:
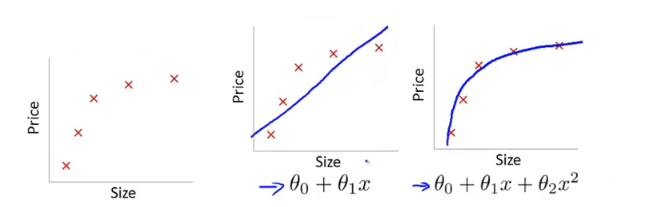
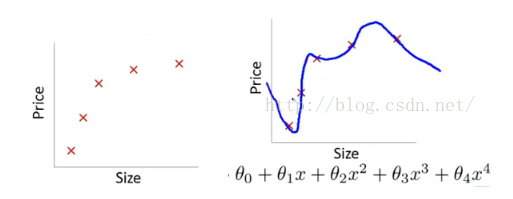
过拟合通俗一点地说就是模型把数据学习的太彻底,以至于把噪声数据的特征也学习到了,这样就会导致在后期测试的时候不能够很好地识别数据,即不能正确的分类,模型泛化能力太差:
随后,完成了清理整合等预处理工作,得到了一份适合建模使用的样本数据:
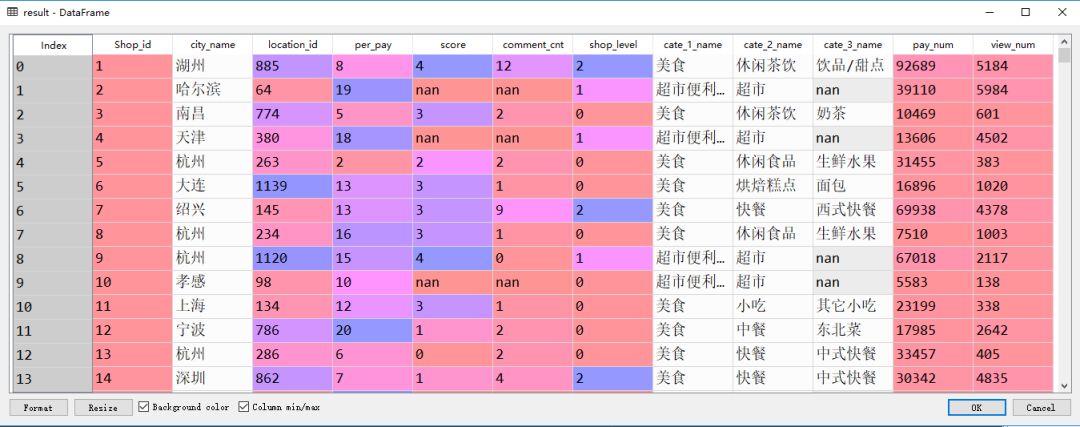
*完整代码可以在文末获取。考虑这份数据比较粗糙,我们仅使用0分店铺和4分店铺的数据
导入所需的包、填充数据空值,再拆分提取训练集和测试集数据,并将数据进行标准化,就为后续的模型构建做足了准备。
▼
#决策树
max_depth_l = [2,3,4,5,6,7,8,9,10]
for max_depth in max_depth_l:
dt_model = DecisionTreeClassifier(max_depth=max_depth)
dt_model.fit(x_train_scaled,y_train)
train_accuracy = dt_model.score(x_train_scaled,y_train)
test_accuracy = dt_model.score(x_test_scaled,y_test)
print('max depth',max_depth)
print('训练集上的准确率:{:2f}%'.format(train_accuracy*100))
print('测试集上的准确率:{:2f}%'.format(test_accuracy*100))
决策树,需要调节的主要参数是树的深度。深度越浅,容易造成欠拟合;而深度越深,则会过拟合。
其实使用这个模型很简单,我们建立一个列表,罗列不同的深度,建立模型进行尝试,最终选择在测试集上表现最好的模型就可以了。

当深度增加的时候,模型在训练集上的准确率越来越高,而在测试集上的准确率在降低,这个就是过拟合的表现。在深度为5的时候,测试集的准确率为最高的73.39%,所以这组模型为决策树的最佳模型。
▼
模型的效果——用混淆矩阵查看
绘制一个混淆矩阵查看模型效果:
dt_model = DecisionTreeClassifier(max_depth=5)
dt_model.fit(x_train_scaled,y_train)
predictions = dt_model.predict(x_test_scaled)
test_accuracy = dt_model.score(x_test_scaled,y_test)
print(classification_report(y_test,predictions))
print('决策树的准确率:{:2f}%'.format(test_accuracy*100))
cnf_matrix = confusion_matrix(y_test,predictions)
plot_confusion_matrix(cnf_matrix, classes=[0,1],
title='Confusion matrix')
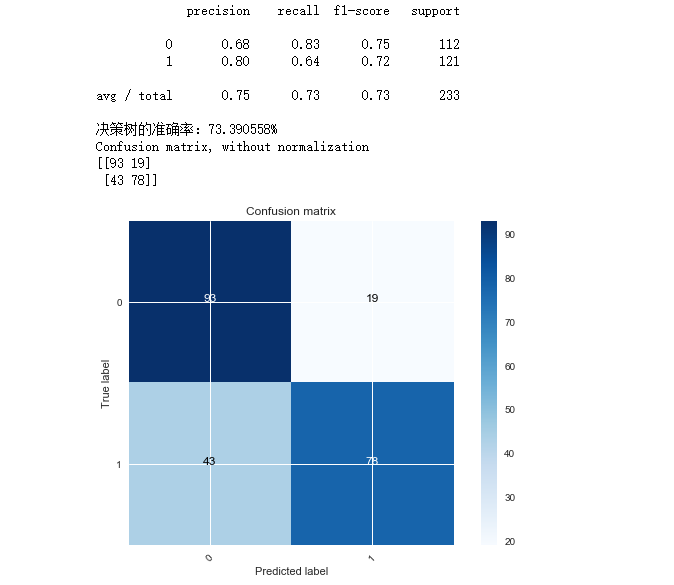
*横坐标是预测值,即“模型认为该店铺为差评/优质店铺”,纵坐标代表真实值,即“该店铺为差评/优质店铺”。0为差评,1为优质
模型在预测优质店铺上容易误杀,把优质店铺预测为差评店铺,错误达到43个,不过店铺茫茫多,错过这个还有下个,本着宁可错杀,不能放过的原则,模型还是可以的。
▼
更强大的模型:随机森林
如果想要有更好的方案,那么我们就用许多模型组合在一起,强强联手,称之为集成模型。
这里我用随机森林,主要原理是构建多棵决策树,每棵决策树都会有一个结果,最后通过投票机制,选出最终结果。
from sklearn.ensemble import RandomForestClassifier
tree_param_grid = {'n_estimators':[10,20,30,50,80],
'min_samples_split':[2,8,10,20,30,50,60,70,80],
'min_samples_leaf':[2,5,10,20,30,50],
'random_state':[2]
}
grid = GridSearchCV(RandomForestClassifier(),param_grid=tree_param_grid,cv=5)
grid.fit(x_train_scaled,y_train)
best_model = grid.best_estimator_
acc1 = best_model.score(x_train_scaled,y_train)
acc2 = best_model.score(x_test_scaled,y_test)
print('随机森林模型训练准确率:{:2f}%'.format(acc1*100))
print('随机森林模型预测准确率:{:2f}%'.format(acc2*100))
print('随机森林模型最佳参数:{}'.format(grid.best_params_))
随机森林模型训练准确率:76.559140%
随机森林模型预测准确率:78.111588%
随机森林模型最佳参数:{'min_samples_leaf': 2, 'min_samples_split': 70, 'n_estimators': 50, 'random_state': 2}
新模型在预测集上达到了78.11%的准确率,对比前面有了较大提升~如果我们有更优质的数据、尝试更多的集成模型,还能再有进步。
接下去只要把目标店铺代入模型就能知道店铺到底好不好了,你的压岁钱保不保得住我就不知道了 ,但一定会得到最优利用。

如果对这方面感兴趣,送出相关的免费直播课程,内容有干货但是也不会太深奥,同时附赠免费答疑福利:
免费直播课
直播主题:深度学习算法从理论到实践的应聘指南
<2月19日 周二 20:00>
直播大纲:
1.计算机视觉深度学习算法体系
2.教你选择适合的学习路线
3.技术细节讲解,以fasterrcnn为例
4.AI计算机视觉岗位招聘攻略
Part.2
《7天入门计算机视觉》免费课程
Day1 安装python环境
Day2 Python语言入门(一)
Day3 Python语言入门(一)
Day4 OpenCV图像处理(一)
Day5 OpenCV图像处理(二)
Day7 神经网络算法
Day8 猫狗分类演练
1. 6G Python入门资料:AI学习的必备帮手
2. 120+篇最新最全的AI报告:遍布政府、证券、咨询、IT等相关行业
3. 6门行业权威亲自授课的在线免费课程:160+篇涉及深度学习、计算机视觉各方向的论文(中英兼备,既泛且精
4. 20+部从小白到高手都能获益的人工智能PDF资料:含人工智能和机器学习领域国际权威学者吴恩达手稿
领取方式
扫码加入QQ群
群号:929246020

席位有限,先到先得~
覆盖JAVA/PHP/IOS/测试等领域
80%级别在P6及以上,含P9技术大咖30人
技术总监和CTO 500余人










