
大家好!本教程重点介绍计算机视觉算法的实现,并深入讨论实现的模型的细微差别。读到最后。包括实施有效CNN的提示和技巧。
我们使用图像分类的示例了解了很多这些概念。顺便说一句,这里是来自图像分类的100个开放数据集的列表,您可以选择任何您感兴趣的人。
让我们从一个基本问题开始吧。为什么我们需要使用深度学习来增强计算机视觉?要回答这个问题,让我们把图像看作一个庞大的矩阵(张量)。 8位图像中的数据表示为像素数组,其中每个像素的值介于0到255之间。我们如何理解随机数值数据?
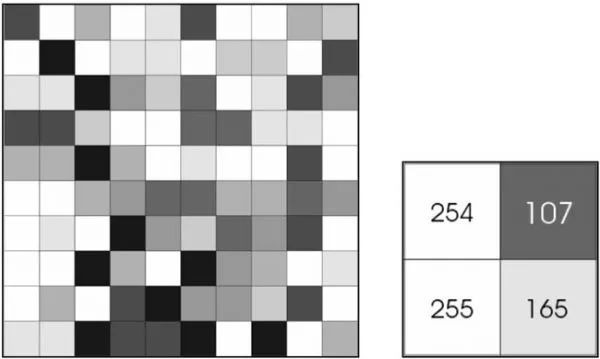
图像中的像素值
整个过程称为特征提取,信号处理和数字图像处理的优雅之处在于算法设计用于提取边缘,轮廓等特征。有几种算法,如SIFT和SURF,可以从图像中提取特征。这些特征是图像的关键描述符,它们被用作发送到机器学习算法的数据,用于进一步创建假设函数(模型),然后可以在测试数据上进行测试。
另一方面,深度学习通过卷积过程简化了特征提取的过程。卷积是一种数学运算,它绘制出能量函数,它是两个信号之间相似性的度量,或者在我们的例子中是图像。因此,当我们使用蓝色滤光片并将其与白光卷积时,所产生的能谱就是蓝光。因此,白光与蓝色滤光器的卷积导致蓝光。因此,术语卷积神经网络,其中特征提取是通过卷积过程完成的。
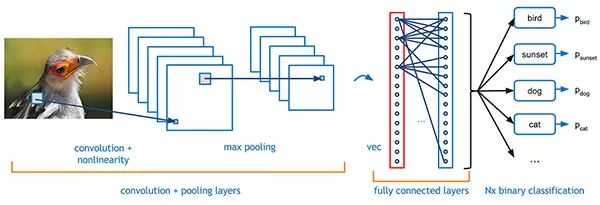
卷积神经网络
让我们从CNN开始吧。这是数据驱动方法的一部分。通过这种方式,我们可以参考深度学习框架对大量数据的依赖性。数据驱动方法是一种使哑巴模型变得聪明的有效方法,因为它可以接触更多数据。

前几个转换层提取边缘等功能。更深的转换层提取复杂的特征,如面部,数字等,这是感兴趣的对象。这种说法过于概括,但从更广泛的层面来看,这是事实。
让我们详细了解每一步。
卷积:我们已经看到了卷积是什么。最初,滤波器通过高斯分布随机初始化。定义这些过滤器使得每个过滤器了解某些模式,并且这些过滤器在网络变得更深时学习更多模式。现在你必须问,相同的过滤器如何从相同的数据中获得不同的见解?要回答这个问题,我们来谈谈汇集。
 Max Pooling with Stride 2
Max Pooling with Stride 2
合并:嗯,合并是一种子采样技术。池的使用是在卷积后减小输入图像的尺寸。有两种类型,最大池和平均池。最大池的插图!猜猜上面的GIF有什么步伐……
批量标准化:我们最初添加此图层,以标准化所有功能。从技术上讲,批量标准化通过减去批次平均值并除以批次标准偏差来标准化先前激活层(最初为输入层)的输出。这使得模型更加健壮并且有效地学习。直观地说,我们正在防止过度拟合!
Dropout:这是Batch Norm之前使用的另一种正则化技术。这种方式的工作方式是,权重随机变化很小……模型最终会学习变化并再次防止过度拟合。单个节点以1-p的概率从网络中丢弃或以概率p保持,以便留下减少的网络;还将删除退出节点的传入和传出边缘。
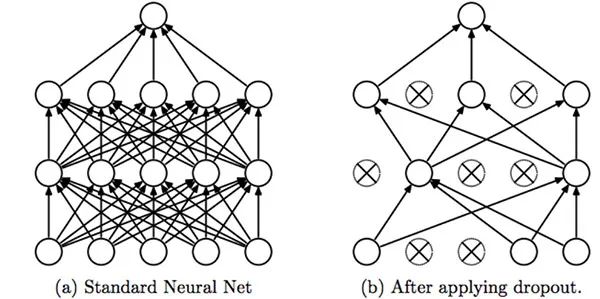
Srivastava,Nitish,et al。 “辍学:防止神经网络过度拟合“
零填充:这有助于防止卷积期间的维数损失。因此,对于非常深的网络,我们通常更喜欢这个。零在卷积期间不会增加能量商,并有助于将维度保持在所需的水平。
完全连接的网络:卷积层的输出表示数据中的高级特征。虽然该输出可以展平并连接到输出层,但添加完全连接的层是学习这些特征的非线性组合的一种方式。基本上,卷积层提供有意义的,低维度的,有些不变的特征空间,并且完全连接的层正在学习由该空间中的激活函数引起的非线性函数。类似于人工神经网络架构。
我们将实施CNN并检查批量规范的效果……当我们的数据集中的图像数量非常少时,我们该怎么做。我们使用转学习。这是一个过程,我们使用预先训练的权重并训练我们数据集的最后几层。
让我们开始吧:这些代码可以在Dataturks官方github帐户上找到。 PyTorch的实现也可以在他们的网站上找到……

Dataturks上的图像分类数据集。
让我们从数据集开始。要开始注释图像,您可以使用dataurks工具。完成注释后,您可以将图像导入Keras格式。 Keras格式本质上是在不同文件夹中具有不同类的所有图像。从dataturks下载json格式文件。相信我!它非常易于使用。
这是一个你可以尝试使用的超级有趣的数据集,分类为权力的游戏中约70个字符的面部图像。
#This script has been solely created under dataturks. Copyrights are reserved
#EXAMPLE USAGE
#python3 keras_json_parser.py –json_file “flower.json” –dataset_path “Dataset5/” –train_percentage 80 –validation_percentage 20
import json
import glob
import urllib.request
import argparse
import random
import os
def downloader(image_url , i):
file_name = str(i)
full_file_name = str(file_name) + ‘.jpg’
urllib.request.urlretrieve(image_url,full_file_name)
if __name__ == “__main__”:
a = argparse.ArgumentParser()
a.add_argument(“–json_file”, help=”path to json”)
a.add_argument(“–dataset_path”, help=”path to the dataset”)
a.add_argument(“–train_percentage”, help=”percentage of data for training”)
a.add_argument(“–validation_percentage”, help=”percentage of data for validation”)
args = a.parse_args()
if args.json_file is None and args.dataset_path is None and args.train_percentage is None and args.validation_percentage is None:
a.print_help()
sys.exit(1)
with open(args.json_file) as file1:
lis = []
for i in file1:
lis.append(json.loads(i))
train = float(int(args.train_percentage) / 100)
test = float(int(args.validation_percentage) / 100)
folder_names = []
label_to_urls = {}
for i in lis:
if i[‘annotation’][‘labels’][0] not in folder_names:
folder_names.append(i[‘annotation’][‘labels’][0])
label_to_urls[i[‘annotation’][‘labels’][0]] = [i[‘content’]]
else:
label_to_urls[i[‘annotation’][‘labels’][0]].append(i[‘content’])
print(label_to_urls.keys())
os.mkdir(args.dataset_path)
os.chdir(args.dataset_path)
os.mkdir(“train”)
os.mkdir(“validation”)
os.chdir(“train/”)
for i in label_to_urls.keys():
os.mkdir(str(i))
os.chdir(str(i))
k = 0
for j in label_to_urls[i][:round(train*(len(label_to_urls[i])))]:
#print(label_to_urls[i][:round(0.8*(len(label_to_urls[i])))])
downloader(j , str(i)+str(k))
k+=1
os.chdir(“../”)
print(os.getcwd())
os.chdir(“../validation/”)
for i in label_to_urls.keys():
os.mkdir(str(i))
os.chdir(str(i))
k = 0
for j in label_to_urls[i][round(0.8*(len(label_to_urls[i]))):]:
downloader(j , str(i)+str(k))
k+=1
os.chdir(“../”)
获得数据集后…运行以下代码以开始培训。使用keras中的flow_from_directory模块导入数据集。
我的朋友Sameer在keras和tensorflow中都实现了CNN分类器。在这里查看他的博客。
接下来,如果我们的数据集很小,那么我们可以使用转移学习。让我们开始吧 …
from keras import applications
from keras.preprocessing.image import ImageDataGenerator
from keras import optimizers
from keras.models import Sequential, Model
from keras.layers import Dropout, Flatten, Dense, GlobalAveragePooling2D
from keras import backend as k
from keras.callbacks import ModelCheckpoint, LearningRateScheduler, TensorBoard, EarlyStopping
from keras.models import load_model
import os
import pickle
from keras.models import model_from_json
import matplotlib.pyplot as plt
image_width, image_height= 256, 256
nb_train_samples= 11000
nb_validation_sample=2000
batch_size = 8
model = applications.VGG19(weights= “imagenet”, include_top=False, input_shape=(image_height, image_width,3))
#freezing the first 5 layers, to avoid excess computation.
for layer in model.layers[:5]:
layer.trainable = False
#creating a fully connected layer.
x=model.output
x=Flatten()(x)
x=Dense(1024, activation=”relu”)(x)
x=Dropout(0.5)(x)
x=Dense(384, activation=”relu”)(x)
x=Dropout(0.5)(x)
x=Dense(96, activation=”relu”)(x)
x=Dropout(0.5)(x)
#Dense(num, activation=”softmax”), the num signifies the number of classes in the dataset.
predictions = Dense(30, activation=”softmax”)(x)
model_final =Model(input=model.input, output=predictions)
#model_final = load_model(“weights_VGG.h5″)
model_final.compile(loss=”categorical_crossentropy”, optimizer=optimizers.nadam(lr=0.00001), metrics=[“accuracy”])
train_datagen = ImageDataGenerator(rescale = 1./255,
shear_range = 0.2,
zoom_range = 0.2,
horizontal_flip = True,
fill_mode=”nearest”,
width_shift_range=0.3,
height_shift_range=0.3,
rotation_range=30)
test_datagen = ImageDataGenerator(rescale = 1./255,
horizontal_flip = True,
fill_mode = “nearest”,
zoom_range = 0.3,
width_shift_range = 0.3,
height_shift_range=0.3,
rotation_range=30)
training_set = train_datagen.flow_from_directory(‘./HE_Chal’,
target_size = (256, 256),
batch_size = 8,
class_mode = ‘categorical’)
test_set = test_datagen.flow_from_directory(‘./Validation’,
target_size = (256, 256),
batch_size = 8,
class_mode = ‘categorical’)
#train the model
model_final.fit_generator(training_set, steps_per_epoch = 1000,epochs = 80, validation_data = test_set,validation_steps=1000)
表示数据
评估
优化
#DeepHacks:P
当我们有更少的数据时该怎么办?如果可能,请使用Bing / Google图像搜索API来增加数据集。如果数据集非常具体,请尝试在受控环境中创建数据集,我的意思是环境光照条件,良好分辨率的相机等。使用Dataturks注释工具快速标记数据集中的每个图像。数据集决定了您的输出质量。转移学习是解决数据较少的特定问题的最佳解决方案。
学习率:我们如何确定哪种学习率最好?到目前为止,我遇到的最好的技术是比较损失与学习率的技术。为此,在数据集上运行1个纪元,并比较每个学习速率的损失。绘制图表并进行分析。每当损失变化率最高时,相应的学习率是最佳的,通常在10 ^ -3-10 ^ -5之间……当使用预训练模型时,学习率必须小于与新线性分类器的(随机初始化的)权重相比,进行微调。这是因为我们期望ConvNet的权重相对较好,所以我们不希望过快和过多地扭曲它们。
权重初始化:权重的初始化对神经元的激发产生巨大影响。在使用ReLU激活功能时,我们更喜欢Xavier初始化。
在Keras,PyTorch上的实现相对简单,但与Tensorflow上的训练时间相比,它们在训练时间上相当慢。我个人会建议使用tensorflow来掌握概念并提高编码技巧。
以上内容仅关注图像分类。但计算机视觉不仅仅是分类任务。分类物体的检测,分割和定位同样重要,例如在自动驾驶汽车中。因此,我强烈建议您浏览R-CNN及其变体。这是一个拥有大量高效实现的庞大领域。
小编推荐HOT
 机器视觉在制造业应用的10个案例
机器视觉在制造业应用的10个案例

机器视觉系统集成发展的现状和前景
2019年光技术发展的十大趋势
机器视觉:PC式视觉系统与嵌入式视觉系统区别
干货:变成计算机视觉大师,需要经历的几个阶段
计算机视觉和图像处理之间有什么区别?
基于HALCON的机器视觉开发,C++或C#如何选择?
 End
End











