
Illustrations by Leon movprint
作者:文建华,小文的数据之旅,数据分析爱好者,不想当码农的伪码农。博客:zhihu.com/c_188462686
先简单介绍一下jieba中文分词包,jieba包主要有三种分词模式:
精确模式:默认情况下是精确模式,精确地分词,适合文本分析;
全模式:把所有能成词的词语都分出来, 但是词语会存有歧义;
搜索引擎模式:在精确模式的基础上,对长词再次切分,适合用于搜索引擎分词。
jieba 包常用的语句:
精确模式分词:jieba.cut(text,cut_all = False),当cut_all = True时为全模式
自定义词典:jieba.load_userdict(file_name)
增加词语:jieba.add_word(seg,freq,flag)
删除词语:jieba.del_word(seg)
《哈利·波特》是英国作家J·K·罗琳的奇幻文学系列小说,描写主角哈利·波特在霍格沃茨魔法学校7年学习生活中的冒险故事。下面将以《哈利波特》错综复杂的人物关系为例,实践一下jieba包。
import numpy as np
import pandas as pd
import jieba,codecs
import jieba.posseg as pseg
from pyecharts import Bar,WordCloud
renmings = pd.read_csv('人名.txt',engine='python',encoding='utf-8',names=['renming'])['renming']
stopwords = pd.read_csv('mystopwords.txt',engine='python',encoding='utf-8',names=['stopwords'])['stopwords'].tolist()
book = open('哈利波特.txt',encoding='utf-8').read()
jieba.load_userdict('哈利波特词库.txt')
def words_cut(book):
words = list(jieba.cut(book))
stopwords1 = [w for w in words if len(w)==1]
seg = set(words) - set(stopwords) - set(stopwords1)
result = [i for i in words if i in seg]
return result
bookwords = words_cut(book)
renming = [i.split(' ')[0] for i in set(renmings)]
nameswords = [i for
i in bookwords if i in set(renming)]
bookwords_count = pd.Series(bookwords).value_counts().sort_values(ascending=False)
nameswords_count = pd.Series(nameswords).value_counts().sort_values(ascending=False)
bookwords_count[:100].index

经过初次分词之后,我们发现大部分的词语已经ok了,但是还是有小部分名字类的词语分得不精确,比如说'布利'、'罗恩说'、'伏地'、'斯内'、'地说'等等,还有像'乌姆里奇'、'霍格沃兹'等分成两个词语的。
#自定义部分词语
jieba.add_word('邓布利多',100,'nr')
jieba.add_word('霍格沃茨',100,'n')
jieba.add_word('乌姆里奇',100,'nr')
jieba.add_word('拉唐克斯',100,'nr')
jieba.add_word('伏地魔',100,'nr')
jieba.del_word('罗恩说')
jieba.del_word('地说')
jieba.del_word('斯内')
#再次分词
bookwords = words_cut(book)
nameswords = [i for i in bookwords if i in set(renming)]
bookwords_count = pd.Series(bookwords).value_counts().sort_values(ascending=False)
nameswords_count = pd.Series(nameswords).value_counts().sort_values(ascending=False)
bookwords_count[:100].index

再次分词之后,我们可以看到在初次分词出现的错误已经得到修正了,接下来我们统计分析。
bar = Bar('出现最多的词语TOP15',background_color = 'white',title_pos = 'center',title_text_size = 20)
x = bookwords_count[:15].index.tolist()
y = bookwords_count[:15].values.tolist()
bar.add('',x, y,xaxis_interval = 0,xaxis_rotate = 30,is_label_show = True)
bar
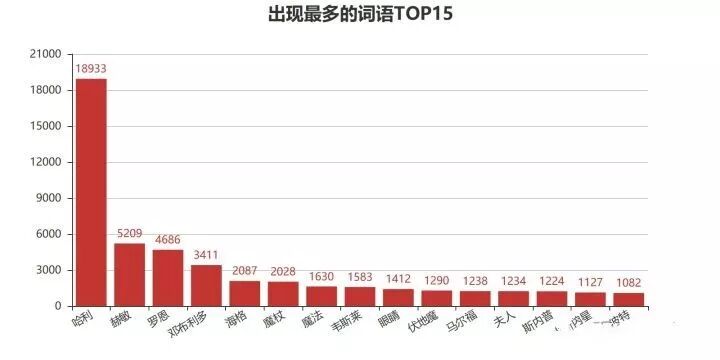
整部小说出现最多的词语TOP15中出现了哈利、赫敏、罗恩、邓布利多、魔杖、魔法、马尔福、斯内普和小天狼星等字眼。
我们自己串一下,大概可以知道《哈利波特》的主要内容了,就是哈利在小伙伴赫敏、罗恩的陪伴下,经过大法师邓布利多的帮助与培养,利用魔杖使用魔法把大boss伏地魔k.o的故事。当然啦,《哈利波特》还是非常精彩的。
bar = Bar('主要人物Top20',background_color = 'white',title_pos = 'center',title_text_size = 20)
x = nameswords_count[:20].index.tolist()
y =nameswords_count[:20].values.tolist()
bar.add('',x, y,xaxis_interval = 0,xaxis_rotate = 30,is_label_show = True)
bar
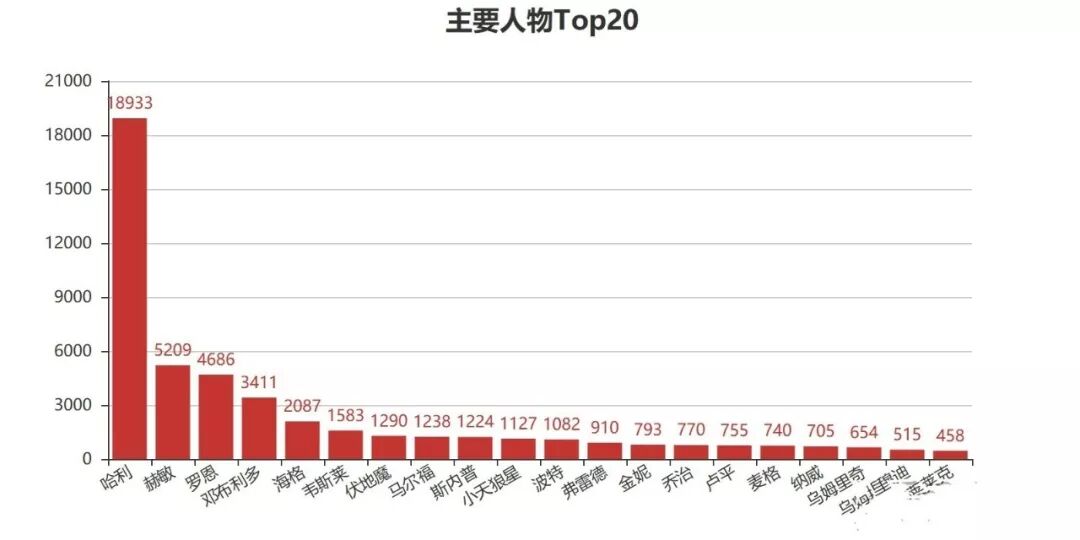
整部小说按照出场次数,我们发现哈利作为主角的地位无可撼动,比排名第二的赫敏远超13000多次,当然这也是非常正常的,毕竟这本书是《哈利波特》,而不是《赫敏格兰杰》。
name = bookwords_count.index.tolist()
value = bookwords_count.values.tolist()
wc = WordCloud(background_color = 'white')
wc.add("", name, value, word_size_range=[10, 200],shape = 'diamond')
wc

#人物关系分析
names =
relationships =
lineNames = []
with codecs.open('哈利波特.txt','r','utf8') as f:
n = 0
for line in f.readlines():
n+=1
print('正在处理第{}行'.format(n))
poss = pseg.cut(line)
lineNames.append([])
for w in poss:
if w.word in set(nameswords):
lineNames[-1].append(w.word)
if names.get(w.word) is None:
names[w.word] = 0
relationships[w.word] =
names[w.word] += 1
for line in lineNames:
for name1 in line:
for name2 in line:
if name1 == name2:
continue
if relationships[name1].get(name2) is None:
relationships[name1][name2]= 1
else:
relationships[name1][name2] = relationships[name1][name2]+ 1
node = pd.DataFrame(columns=['Id','Label','Weight'])
edge = pd.DataFrame(columns=['Source','Target','Weight'])
for name,times in names.items():
node.loc[len(node)] = [name,name,times]
for name,edges in relationships.items():
for v, w in edges.items():
if
w > 3:
edge.loc[len(edge)] = [name,v,w]
处理之后,我们发现同一个人物出现了不同的称呼,因此合并并统计,得出88个节点。
node.loc[node['Id']=='哈利','Id'] = '哈利波特'
node.loc[node['Id']=='波特','Id'] = '哈利波特'
node.loc[node['Id']=='阿不思','Id'] = '邓布利多'
node.loc[node['Label']=='哈利','Label'] = '哈利波特'
node.loc[node['Label']=='波特','Label'] = '哈利波特'
node.loc[node['Label']=='阿不思','Label'] = '邓布利多'
edge.loc[edge['Source']=='哈利','Source'] = '哈利波特'
edge.loc[edge['Source']=='波特','Source'] = '哈利波特'
edge.loc[edge['Source']=='阿不思'
,'Source'] = '邓布利多'
edge.loc[edge['Target']=='哈利','Target'] = '哈利波特'
edge.loc[edge['Target']=='波特','Target'] = '哈利波特'
edge.loc[edge['Target']=='阿不思','Target'] = '邓布利多'
nresult = node['Weight'].groupby([node['Id'],node['Label']]).agg({'Weight':np.sum}).sort_values('Weight',ascending = False)
eresult = edge.sort_values('Weight',ascending = False)
nresult.to_csv('node.csv',index = False)
eresult.to_csv('edge.csv',index = False)
有了节点node以及边edge后,通过gephi对《哈利波特》的人物关系进行分析:

(节点的大小表示人物的出场次数,线的粗细表示人物之间的交往关系)

▼ 点击下方阅读原文
免费成为社区注册会员,会员可以享受更多权益








