本文为 AI 研习社编译的技术博客,原标题 :
DATA CLEANING WITH PYTHON
作者 | Balogun Omobolaji
翻译 | 酱番梨、祝弟弟基督教
校对 | Pita 审核 | 约翰逊·李加薪 整理 | 立鱼王
原文链接:
https://medium.com/machine-intelligence-team/data-cleaning-with-python-d0ca811d6cdf
注:本文的相关链接请访问文末二维码


“数据科学家们80%的精力消耗在查找、数据清理、数据组织上,只剩于20%时间用于数据分析等。”——IBM数据分析
数据清洗是处理任何数据前的必备环节。在你开始工作前,你应该有能力处理数据缺失、数据不一致或异常值等数据混乱情况。在开始做数据清洗前,需要对Numpy和Pandas库有基本的理解。
数据清洗名如其意,其过程为标识并修正数据集中不准确的记录,识别数据中不可靠或干扰部分,然后重建或移除这些数据。
数据清洗是数据科学中很少提及的一点,因为它没有训练神经网络或图像识别那么重要,但是数据清洗却扮演着非常重要的角色。没有它,机器学习预测模型将不及我们预期那样有效和精准。
下面我将讨论这些不一致的数据:
数据缺失
列值统一处理
删除数据中不需要的字符串
数据缺失原因?
在填写问卷时,人们往往未填全所有必填信息,或用错数据类型。问卷结果中缺失的数据在使用前必须做相应的解释及处理。
下面,我们将看到一份关于不同层次学生入学考试的数据集,包括得分、学校偏好和其他细节。
通常,我们先导入Pandas并读入数据集。
import pandas as pd
data = pd.read_csv('Responses.csv')
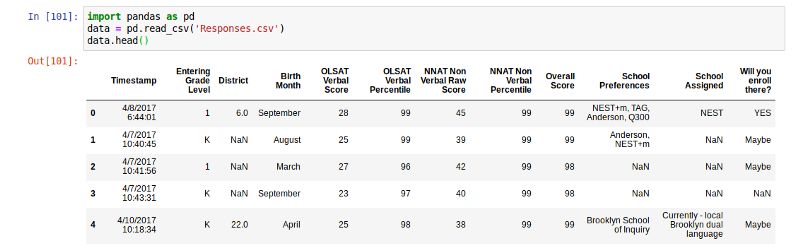
在需要的地方,你可以用NaN的非标准类型(例:'n/a','na','-')来替代缺失的值。
missing_values = ['n/a', 'na', '--']
data =pd.read_csv('Responses.csv', na_values = missing_values)
data.head()
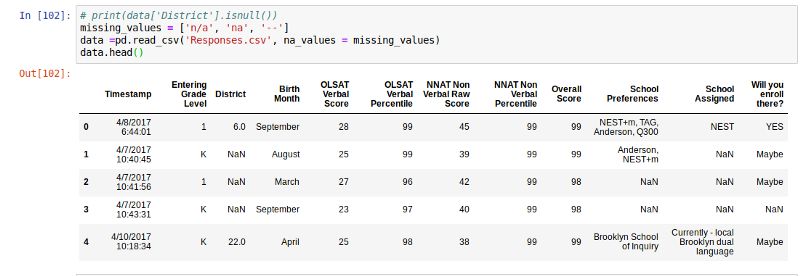
得到"District"列缺值统计数
看District列,我们想检测该列是否有空值并统计空值的总数。
data['District'].isnull().values.any() #To know if there is any missing values
#Returns True
data['District'].isnull().sum()
#Returns 16

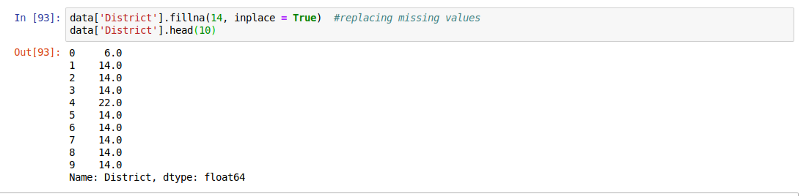
替换全部非数值型值
我们可以用需要的值来替换全部非数值型值,下面先使用14这个值。
data['District'].fillna(14, inplace = True) #replacing missing
#values
data['District']
替换一个指定的非数值型值
我们也可以替换指定位置的值,下面例子是行索引为3。
data.loc[3, 'District'] = 32
# data
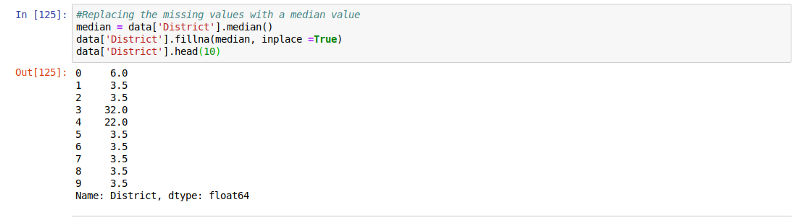
使用中位数替换缺失值
我们可以使用非数值型值所在列的中位数进行替换,下列中的中位是为3.5。(补充说明:中位数这里指非数值型值所在列的全部值,按高低排序后找出正中间的一个作为中位数)
median = data['District'].median()
median
data['District'].fillna(median, inplace =True)
data['District']
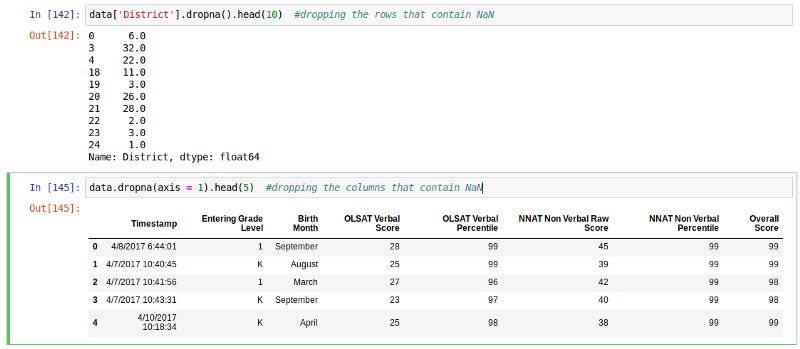
删除缺值项
如果你只是想简单地排除缺值项,可以用dropna函数配合axis参数进行。缺省情况下,axis=0表示沿横轴(行)删除含有有非数值型字段的任何行。
# Drop any rows which have any NaNs
data.dropna()
# Drop columns that have any NaNs
data.dropna(axis=1)
如果数列中超过90%的数据是“非数”,我们将其删除
这是我最近学到的一个有趣的功能。参数 thresh = N要求数列中至少含有N个非数才能得以保存。在将它们视为模型的候选者之前,你只需要具有90%可用功能的记录。
# Only drop columns which do not have at least 90% non-NaNs
data.dropna(thresh=int(data.shape[0] * .9), axis=1)
#Returns a data with the shape of 117rows and 8 columns
#Recall that the original data 117rows and 12columns
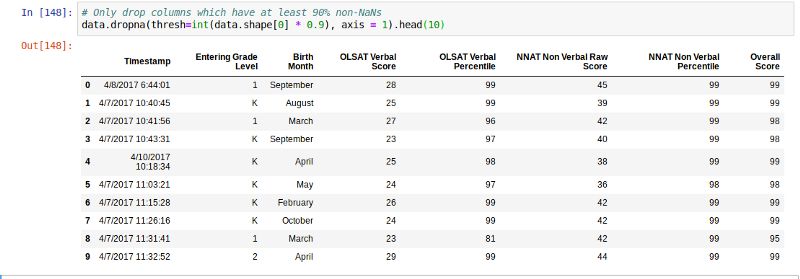
所以,这意味着4列超过90%的数据相当于“非数”。这些对我们的结果几乎没有影响。
执行上述操作的另一种方法是手动扫描/读取列,并删除对我们的结果影响不大的列。
to_drop = ['District', 'School Preferences', 'School Assigned' 'Will you enroll there?']
data.drop(columns=to_drop, inplace=True)
删除字符串中的某些字符
假设我们想要处理一个大型数据集,它包含一些我们不希望包含在模型中的字符串,我们可以使用下面的函数来删除每个字符串的某些字符。
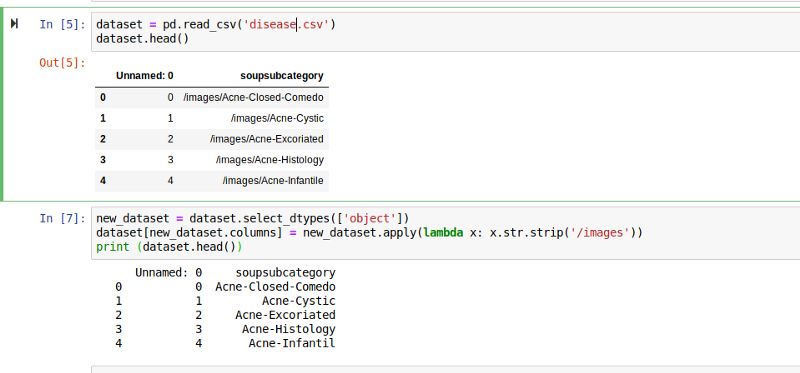
上面的屏幕截图显示了如何从字符串中删除一些字符
soupsubcategory是唯一一个数据类型为'object'的列,所以我们选择了select_dtypes(['object']),我们正在使用lambda函数从该列中的每个
new_dataset = dataset.select_dtypes([‘object’])
dataset[new_dataset.columns] = new_dataset.apply(lambda x: x.str.strip(‘/images’))
print (dataset)
我们可以对我们的数据执行其他一些功能和方法,本文未介绍这些功能和方法。您可以从本课程中了解更多信息。
结论
网络上有大量资源可以帮助您更深入地了解Python for Data Science。以上只是数据科学所需要的一小部分。清理完数据后,您可以在处理数据之前对其进行可视化(数据可视化),并根据结果进行预测。
请查看以下链接,以查找有助于您进行Python数据科学之旅的其他资源:
感谢阅读。
想要继续查看该篇文章相关链接和参考文献?
点击底部【阅读原文】或长按下方地址/二维码访问:
https://ai.yanxishe.com/page/TextTranslation/1495