大量研究者在预印本网站 arXiv 上发表前沿研究,那么基于 arXiv 判断研究趋势是否可行呢?近日,来自德国达姆施塔特工业大学和法兰克福金融管理学院的研究者在 arXiv 上发表论文,试图基于两个 arXiv 论文数据集预测相关领域的研究趋势。
研究者使用的数据集来自 arXiv 上机器学习 (cs.LG) 和自然语言处理 (cs.CL) 两个类别,他们采用自下而上的方法基于这两个数据集检测研究趋势:首先按论文的引用量(经过标准化)对论文进行排序,然后按照论文任务和使用方法将排序靠前的论文分为不同类别,再对得到的主题进行分析。研究者发现 cs.CL 领域中的主导范式是自然语言生成问题,cs.LG 领域的主导研究方向是强化学习和对抗学习。研究者通过外推法(extrapolation),预测这些话题在中短期内仍将是各自领域中的主要问题/方法。
下面展示了前沿研究的任务、方法和目标分布情况。
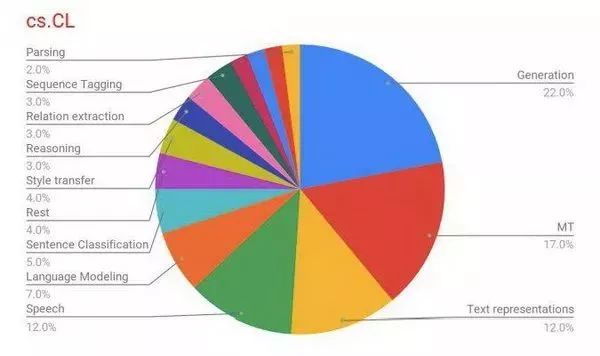
图 1:cs.CL 领域 top-100 论文的任务分布情况。我们可以从中观察到自然语言生成任务是其中的主导任务。
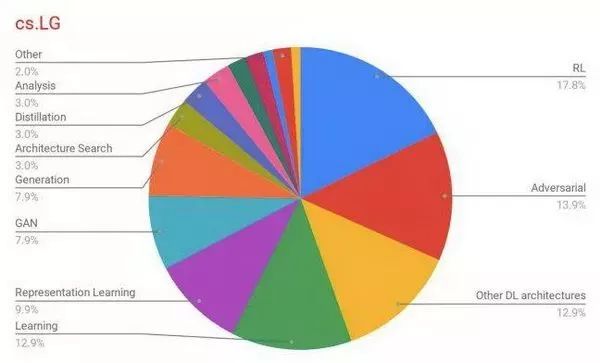
图 2:cs.LG 领域 top-100 论文的方法分布情况。我们可以从中看到强化学习和对抗学习是这些论文中使用最广泛的方法。
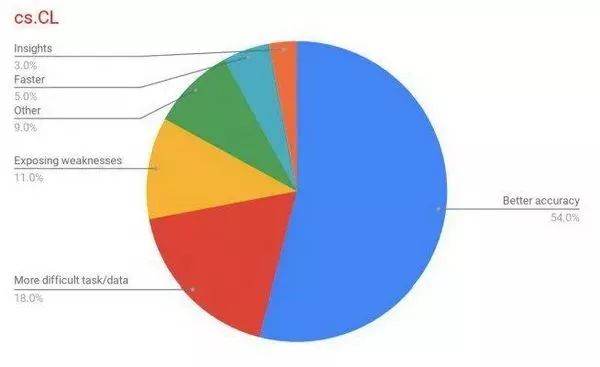
图 3:cs.CL 领域 top-100 论文的目标分布情况。我们可以从中看到超半数研究的目标是提高准确率。
预测研究趋势一直是科学家的梦想。关于流行研究课题的项目往往能够比较轻松地被大会和期刊接收,同时也更容易得到研究经费批准。此外,了解未来研究趋势有益于整个社会,因为这些趋势很可能直接影响劳动市场、技术方向、消费者和产品,以及人类认同性的文化隐喻和定义,对人工智能等领域来说更是如此。但是,随着研究者发布的论文数量逐年攀升,消化这么多信息并从中人工识别出可能具备长期科学影响的话题更加困难。本文介绍的研究开发了一种自动化系统,旨在发现重要的研究趋势,从而帮助研究者更好地规划自己的学术活动。
这个系统从 arXiv 的机器学习 (cs.LG) 和自然语言处理 (cs.CL) 类别中抓取论文及其引用信息,来构建数据集。然后,研究者根据论文引用量(经过标准化处理)判断数据集中有潜力的论文,然后通过人工和自动的方式将这些论文分类。研究者使用 arXiv 论文的原因在于,arXiv 是非常流行的科研成果预印本(及后印本)平台,且近年来影响力逐渐上升。
研究者创建了两个数据集,分别包括来自 arXiv 机器学习 (cs.LG) 和自然语言处理(cs.CL) 类别的论文。选择这两个人工智能子领域的原因是,它们动态变化大,每年都会发生很大的变化和性能改进。收集的数据包括论文标题、摘要和作者,研究者还从 Semantic Scholar 网站抓取了这些论文的引用量信息。数据集中的论文发表于 2017 年 6 月至 2018 年 12 月,包括 4800 篇 cs.CL 领域论文和 12400 篇 cs.LG 论文。
该研究的作者之一手动标注了这两个领域 top-100 论文的摘要,主要标注了三个属性:任务、方法和目标/成果。这些属性回答了论文研究什么、如何研究、为什么研究这几个问题。研究者为 cs.CL 领域论文设置了 15 个任务类别、28 个方法类别和 7 个目标类别,为 cs.LG 设置了 13 个任务类别、15 个方法类别和 13 个目标类别。
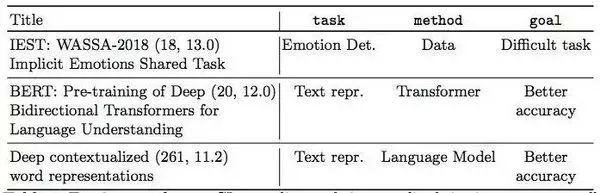
表 1:根据标准化后的引用量得到的 cs.CL 领域 Top-3 论文,及其任务、方法和目标。括号中的数字表示截至 2018 年 12 月时的引用量绝对值和标准化后的值。
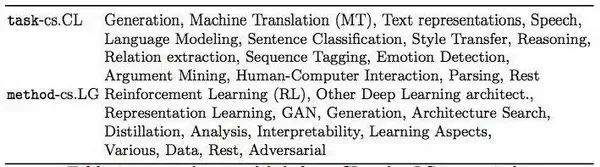
表 2:cs.CL 和 cs.LG 领域各自的任务和方法标签。
论文影响力最简单的衡量方式是引用量,但研究领域和论文发布日期会影响引用量数字的绝对值。因此,研究者对比同一研究领域的论文,并按论文发表时长调整引用量分数,从而对引用量进行标准化处理。这即是 Newman [8,9] 提出的 z-score 方法:根据引用量绝对值的均值和标准差进行标准化。
研究者以 ±10 天作为时间窗口,对数据集中的所有论文执行 z-score 标准化(忽略引用量少于 4 的论文)。
论文:Predicting Research Trends From Arxiv

论文链接:https://arxiv.org/pdf/1903.02831v1.pdf










