前言
在《从零开始学Python【34】--CART决策树(理论部分)》期中我们介绍了有关CART决策树的构造和节点选择的理论知识,但理论终究需要实战进行检验。本文我们就从实战的角度,继续介绍CART决策树的实际应用。
语法介绍
CART决策树是一个非常优秀的数据挖掘模型,它既可以解决离散型因变量的分类问题,也可以处理连续型因变量的预测问题,而且该算法对数据的分布特征没有任何的要求。在本次的实战项目中,将利用CART决策树对患者的肾小球滤过率作预测分析。
Python中的sklearn模块选择了一个较优的决策树算法,即CART算法,它既可以处理离散型的分类问题(即分类决策树),也可解决连续型的预测问题(即回归决策树)。这两种树分别对应DecisionTreeClassifier类和DecisionTreeRegressor类,接下来简单介绍一下这两个类的语法和参数含义:
DecisionTreeClassifier(criterion='gini', splitter='best', max_depth=None, min_samples_split=2,
min_samples_leaf=1, min_weight_fraction_leaf=0.0, max_features=None,
random_state=None, max_leaf_nodes=None, min_impurity_decrease=0.0,
min_impurity_split=None, class_weight=None, presort=False)
DecisionTreeRegressor(criterion='mse', splitter='best', max_depth=None, min_samples_split=2,
min_samples_leaf=1, min_weight_fraction_leaf=0.0, max_features=None,
random_state=None
, max_leaf_nodes=None, min_impurity_decrease=0.0,
min_impurity_split=None, presort=False)
criterion:用于指定选择节点字段的评价指标,对于分类决策树,默认为'gini',表示采用基尼指数选择节点的最佳分割字段;对于回归决策树,默认为'mse',表示使用均方误差选择节点的最佳分割字段;
splitter:用于指定节点中的分割点选择方法,默认为'best',表示从所有的分割点中选择最佳分割点;如果指定为'random',则表示随机选择分割点;
max_depth:用于指定决策树的最大深度,默认为None,表示树的生长过程中对深度不作任何限制;
min_samples_split:用于指定根节点或中间节点能够继续分割的最小样本量, 默认为2;
min_samples_leaf:用于指定叶节点的最小样本量,默认为1;
min_weight_fraction_leaf:用于指定叶节点最小的样本权重,默认为None,表示不考虑叶节点的样本权值;
max_features:用于指定决策树包含的最多分割字段数,默认为None,表示分割时使用所有的字段,与指定'auto'效果一致;如果为具体的整数,则考虑使用对应的分割字段数;如果为0~1之间的浮点数,则考虑对应百分比的字段个数;如果为'sqrt',则表示最多考虑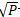 个字段;如果为'log2',则表示最多使用
个字段;如果为'log2',则表示最多使用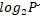 个字段;
个字段;
random_state:用于指定随机数生成器的种子,默认为None,表示使用默认的随机数生成器;
max_leaf_nodes:用于指定最大的叶节点个数,默认为None,表示对叶节点个数不作任何限制;
min_impurity_decrease:用于指定节点是否继续分割的最小不纯度值,默认为0;
min_impurity_split:同参数min_impurity_decrease含义一致,该参数在0.21版本以剔除;
class_weight:用于指定因变量中类别之间的权重,默认为None,表示每个类别的权重都相等;如果为balanced,则表示类别权重与原始样本中类别的比例成反比;还可以通过字典传递类别之间的权重差异,其形式为:{class_label:weight};
presort:bool类型参数,是否对数据进行预排序,默认为False,如果数据集的样本量比较小,设置为True可以提高模型的执行速度,但数据集的样本量如果比较大,则不易设置为True;
不管是ID3、C4.5还是CART决策树,在建模过程中都可能存在过拟合的情况,即模型在训练集上有很高的预测精度,但是在测试集上效果却不够理想。为了解决过拟合问题,通常会对决策树作剪枝处理,下一期中我们将介绍有关决策树的几种剪枝方法,并通过图形的方式解释理论背后的运转。
CART决策树的预测实战
本节使用CART决策树进行项目实战,需要注意的是因变量为连续的数值型。使用的数据集是关于患者的肾小球滤过率,该指标可以反映患者肾功能的健康状况,该数据集一共包含28,009条记录和10个变量。首先预览一下该数据集的前几行信息:
NHANES = pd.read_excel(r'C:\Users\Administrator\Desktop\NHANES.xlsx')
NHANES.head()
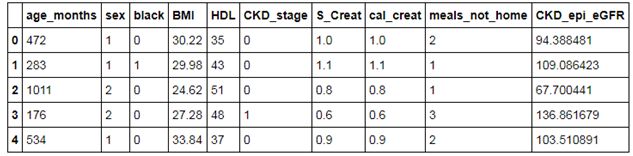
如上表所示,数据集中的CKD_epi_eGFR变量即为因变量,它是连续的数值型变量,其余变量包含患者的年龄、性别、肤色、身体质量指数及高密度脂蛋白指数等。由于数据集预先做了相应的清洗,这里就直接使用读入的数据进行建模,代码如下:
predictors = NHANES.columns[:-1]
X_train, X_test, y_train, y_test = model_selection.train_test_split(NHANES[predictors], NHANES.CKD_epi_eGFR,
test_size = 0.25, random_state = 1234)
max_depth = [18,19,20,21,22]
min_samples_split = [2,4,6,8]
min_samples_leaf = [2,4,8,10,12]
parameters = {'max_depth':max_depth, 'min_samples_split':min_samples_split, 'min_samples_leaf':min_samples_leaf}
grid_dtcateg = GridSearchCV(estimator = tree.DecisionTreeRegressor(), param_grid = parameters, cv=10)
grid_dtcateg.fit(X_train, y_train)
grid_dtcateg.best_params_
out:
{'max_depth': 20, 'min_samples_leaf': 2, 'min_samples_split': 4}
如代码所示,由于训练数据集的样本量比较大,所以设置的树深度在20左右。经过10重交叉验证的网格搜索,得到各参数的最佳组合值为20,2,4。接下来利用这个参数值,构建回归决策树,代码如下:
CART_Reg = tree.DecisionTreeRegressor(max_depth = 20, min_samples_leaf = 2, min_samples_split = 4)
CART_Reg.fit(X_train, y_train)
pred = CART_Reg.predict(X_test)
metrics.mean_squared_error(y_test, pred)
out:
1.8355765418468155
由于因变量为连续型的数值,所以不能再使用分类模型中的准确率指标进行评估,而是使用均方误差MSE或均方根误差RMSE,如果该指标越小,说明模型拟合效果越好。通过模型在测试集上的预测,计算得到MSE的值为1.84。
最后,读者也不妨试试别的预测算法,如之前介绍的KNN算法,并通过比较各算法之间RMSE,确定哪个算法更能够有较好的预测效果。不幸的是,在sklearn模块中,并没有提供决策树剪枝的现成函数,但比较好的解决方案是选择随机森林拟合数据。关于随机森林的介绍和实战,读者可以查看我的新书《从零开始学Python数据分析与挖掘》,里面有对应的知识讲解。
结语
OK,关于CART决策树算法的实战我们就分享到这里,如果你有任何问题,欢迎在公众号的留言区域表达你的疑问。同时,也欢迎各位朋友继续转发与分享文中的内容,让更多的人学习和进步。

长按扫码关注我









