
比较Python中的东西。这听起来几乎是不需要教的,但是我发现Python的比较运算符经常被Python新手误解和低估。
我们来回顾一下Python的比较运算符如何处理不同类型的对象,然后看看如何使用这些比较运算符来提高代码的可读性。
Python中的比较运算符
我这里所说的 “比较运算符”是指相等运算符(== 和 !=)和排序运算符(,>=)。
我们可以用这些运算符来比较数字,正如你所期望的:

除此之外,我们也可以用这些运算符来比较字符串:

甚至于元组:

许多编程语言都没有与Python非常灵活的比较运算符等价的运算符。
稍后我们将看一看这些运算符如何处理元组和更复杂的对象,我们先从简单一点的开始:字符串比较。
Python中的字符串比较
字符串的相等和不相等十分简单。如果两个字符串有完全相同的字符,那么它们是相等的:

注意,我忽略了一个非常大的例外: unicode字符。通常有多种方法可以表示相同的文本,在将这些不同的表示视为相等之前,必须对它们进行标准化。为了简单起见,本文将坚持使用ASCII字符。
字符串的排序是Python中比较有趣的部分:

字符串“pickle”比字符串“python”小,因为我们是按字母顺序排序的…大小写有一部分作用:

字符串“Python”小于“pickle”,因为P小于p。
这里我们与其说是按照字母顺序还不如说是按照ASCII- 码顺序排序的 (因为我们在python3中实际是使用unicode-码)。这些字符串是按照它们的字符的ASCII码值排序的(ASCII码中p是112,而P是80)。

从技术上讲,Python是比较这些字符的Unicode代码点(这是ord函数所做的事情),而这恰好与比较ASCII字符的ASCII码值结果相同。
字符串的排序规则是:
使用==操作符比较每个字符串的第n个字符(从第一个字符开始,索引为0);如果它们相等,则对下一个字符重复这个步骤
对于两个不相等的字符,取具有较低代码点的字符,并声明其所在字符串“小于”另一个
如果所有字符都相等,那么字符串也是相等的
如果一个字符串在步骤1中耗尽字符(一个字符串是另一个字符串的“前缀”),则较短的字符串“小于”较长的字符串
Python用于比较字符串的排序算法可能看起来很复杂,但它与字典中使用的排序算法非常相似;不是Python中的字典,而是物理字典(我们在互联网出现之前使用的那些东西)。当在字典中对单词排序时,我们优先考虑第一个字符,如果一个单词是另一个单词的前缀,那么它就会排在前面。
元组的比较
我们可以问元组是否相等,就像我们可以问字符串是否相等一样:

但是我们也可以使用排序运算符(,>=)来比较元组:

字符串排序可能有些直观(我们大多数人在Python之前就已经学习了字母排序),但是元组排序一开始并不那么直观。但实际上你已经对元组排序有点熟悉了,因为元组排序和字符串排序使用相同的算法。
元组排序的规则(本质上与字符串排序相同):
使用==运算符比较每个元组的第n项(从第一个项开始,索引为0);如果它们相等,则对下一项重复这个步骤
对于两个不相等的项,“小于”的项使包含它的元组也“小于”另一个元组
如果所有项都相等,则元组相等
如果一个元组在步骤1中耗尽了项(一个元组是另一个元组的“子集”),则较短的元组“小于”较长的元组
在Python中,这个算法看起来可能有点像这样:

注意,我们永远不会这样编写代码,因为Python已经为我们完成了所有这些工作。上面整个函数与使用<运算符效果相同:

字典排序
这种给予一个迭代中第一项优先权并类似于按字母顺序的排序方式称为字典排序。你不需要知道这个短语,但是如果你需要描述Python中排序的工作方式,就可以使用lexicographic这个词。
字符串和元组是按字典顺序排列的,正如我们所见,列表也是这样:

实际上,Python中的大多数序列都应该按字典顺序排列
(range对象是一个例外,因为根本无法对它们进行排序)。
但并不是Python中的所有集合都依赖于字典排序。
字典和集合的比较
Python中的许多对象都可以进行相等比较,但不是都能够排序。
例如,字典比较“相等”时,它们所有的键和值都相同:
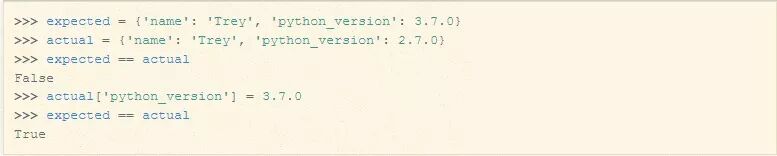
但是字典不能使用<或>运算符来排序:

集合也是类似的,除了集合可以使用排序运算符……它们只是不使用这些运算符来排序:

集合重载了这些运算符,以便回答关于一个集合是否是另一个集合的子集还是超集的问题(请参阅文档中关于集合的部分)。
深度相等
Python中两种数据结构之间的比较往往是深度比较。无论我们是在比较列表、元组、集合还是字典,当我们询问其中两个对象是否“相等”时,Python将递归遍历每个子对象并询问它们是否“相等”。
因此,给定一个字典就可以将其中的元组映射到元组列表:

询问两个字典是否相等等价于递归地询问每个键值对是否相等:

字典会问它们的每个键“你在另一个字典里吗”,然后问这些键对应的每个值“你等于另一个值吗”。但是,每一个操作都可能(就像在本例中)需要另一层深度的操作:键是需要遍历的元组,而值是需要遍历的列表。在这种情况下,需要更深入地遍历这些值,即列表,因为它们包含更多的数据结构:元组。
不过,我们不必担心这些:Python会自动地为我们做这些深入的比较。
虽然你不需要关心深度比较是怎样进行的,但是,实际上Python的比较深度是轻易就能知道的。。
例如,如果我们有一个带有x、y和z属性的类,我们想要在我们的__eq__方法中进行比较,而不是使用这个冗长的布尔表达式:

我们可以将这些值处理成含有3个项的元组,来替代布尔表达式进行比较:

我发现这更易于阅读,主要是因为我们在代码中添加了对称性:我们有一个==表达式,它的两边都有相同类型的对象。
深度排序
这种“深度比较”适用于相等比较,但也适用于排序。
深度排序的例子不如深度相等的例子明显,但是确定哪些地方可以方便地进行深度排序可以帮助你极大地提高代码的可读性。
举个例子方法:
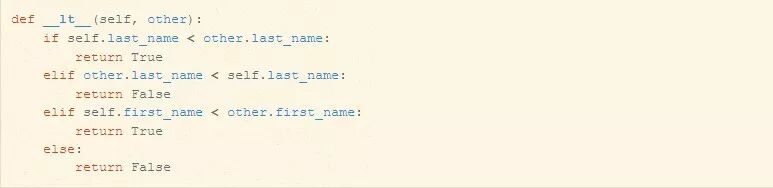
这个 __lt__ 方法在其类上实现了<运算符,如果self小于other,则返回True。以这种方式存储和比较first_name和last_name属性是一种反模式,但在本例中我们将忽略这一点。
上面的__lt__方法会给予last_name优先权:只有当这两个对象的last_name属性恰好相等时才会检查first_name。
如果我们想打破这个逻辑,我们可以这样重写我们的代码:

或者,我们也可以使用元组的深度排序来代替:

在这里,我们按照字典顺序(首先按照它们的第一个项排序)排列元组。我们的元组正好包含字符串,这些字符串也会按字典顺序排序(首先按其第一个字符排序)。因此,我们对这些对象进行了深度排序。
一次按多个属性排序
在对Python对象排序时,了解Python序列的词典排序和深度排序非常有用。从Python的角度来看,排序实际上就是一遍又一遍地排列顺序。
Python内置的sorted函数接受一个key函数,它可以返回一个相应的key对象,并以此来对这些项进行排序。
这里我们指定了一个key函数,它接受一个单词并返回一个元组,该元组由两部分组成:单词的长度和大小写规范化的单词:

使用上面的key函数,我们可以先根据水果的长度排序,然后根据它们的大小写标准化的等价项排序。所以“jujube”排在第一位,因为它是6个字母(比如longan 和 Loquat),但它按字母顺序也是排在longan 和 Loquat之前。
如果我们只是按长度排序,我们会有一个不同的顺序:

旁注:在Python中,深度比较实际上早于sorted 函数的key参数。在key函数出现之前,Python开发者会创建元组列表,对元组列表进行排序,然后从该列表中获取他们关心的实际值(文档中对此进行了讨论)。
元组排序并不只是适用sorted函数。任何能看到key函数的地方都可以考虑使用元组排序。例如min和max函数:

在Python执行排序操作的任何地方,你都可以使用Python数据结构的深度排序。
深度哈希性 (和不可哈希性)
Python既具有深度相等性,又具有深度可排序性。但是Python的深度比较还不止于此:还有深度哈希性。
这主要是由元组带来的的。元组可以用作字典中的键(正如我们前面看到的),它们可以在集合中使用:

但这只适用于包含不可变值的元组:

包含列表的元组是不可哈希的,因为列表是不可哈希的:元组里边的每个对象都必须是可哈希的,这样元组本身才是可哈希的。
因此,虽然包含列表的元组是不可哈希的,但是包含元组的元组是可哈希的:

元组通过分派给它们包含的项的哈希值来计算自身的哈希值:

虽然哈希性是一个很大的主题,但这就是我要说的全部。你不需要真正了解Python中的哈希过程是如何工作的,所以如果你发现这一部分令人困惑,也没有关系!
这里的要点是Python支持深度哈希,这就是我们可以使用元组作为字典键的原因,也是我们可以在集合中使用元组的原因。
深度比较是一种需要记住的工具
当你有一段以特定顺序比较两个基于子部分的对象的代码时:

你可以优先考虑元组排序:

如果你正在进行很多东西的相等比较时:

你或许可以优先考虑深度相等:

如果你需要使用一个带有由多个部分组成的键的字典时,并且这些部分都是可哈希的,你可以使用一个元组:

Python对词典排序和深度比较的支持常常被来自其他编程语言的人忽视。请记住这些特性:你今天可能不需要它们,但在某个时候它们肯定会派上用场。
英文原文:https://treyhunner.com/2019/03/python-deep-comparisons-and-code-readability/
译者:天天向上









