很明显这组数据不符合正态分布。这个分布展示了销售额目标频数随着销售额的增加而减少。这个分布可以理解成:根据层级,渠道,地域等等的区分,需完成的销售额目标也不同。
为了模拟这组数据,可以使用均匀分布,但是给一些值分配较低的概率。这里我们使用了numpy.random.choice模块,代码如下:
sales_target_values = [75_000, 100_000, 200_000, 300_000, 400_000, 500_000]
sales_target_prob = [.3, .3, .2, .1, .05, .05]
sales_target = np.random.choice(sales_target_values, num_reps, p=sales_target_prob)
这组数据其实不具有代表性,这样做只是为了展示如何将不同的分布应用在我们的模型中。
现在有了两组不同分布的模拟数据(销售计划完成百分比数组和销售额目标数组),将它们并入一个DataFrame:
df = pd.DataFrame(index=range(num_reps), data={'Pct_To_Target': pct_to_target,
'Sales_Target': sales_target})
df['Sales'] = df['Pct_To_Target'] * df['Sales_Target']
新的DataFrame如下:
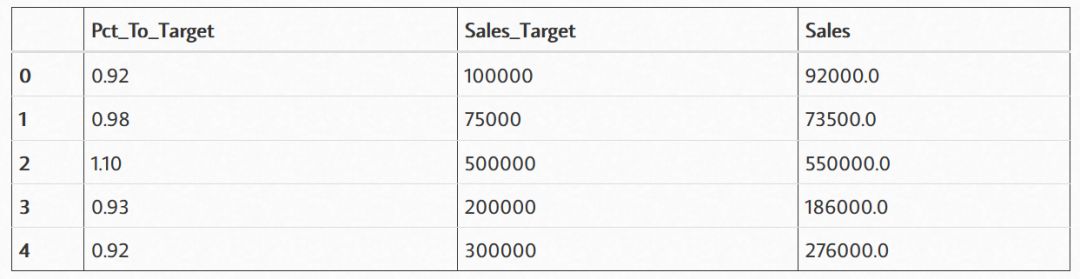
从上边的代码中可以看到我们使用了两组模拟数组计算出了模拟的最终销售额。对于这个情况,最终销售额(sales)也许会随着年份的变化出现大幅波动,但是这组被组合的新数组的分布大体是被前两组数组确定下来的。
最后一步,需要根据销售目标完成进度映射对应的提成比例:
def calc_commission_rate(x):
""" Return the commission rate based on the table:
0-90% = 2%
91-99% = 3%
>= 100 = 4%
"""
if x <= .90:
return .02
if x <= .99:
return .03
else:
return .04
相比Excel,python优势在于可以创建更复杂的逻辑,且更易实现。现在我们向DataFrame里加入对应提成比例和销售佣金,代码如下:
df['Commission_Rate'] = df['Pct_To_Target'].apply(calc_commission_rate)
df['Commission_Amount'] = df['Commission_Rate'] * df['Sales']
最新的DataFrame如下:
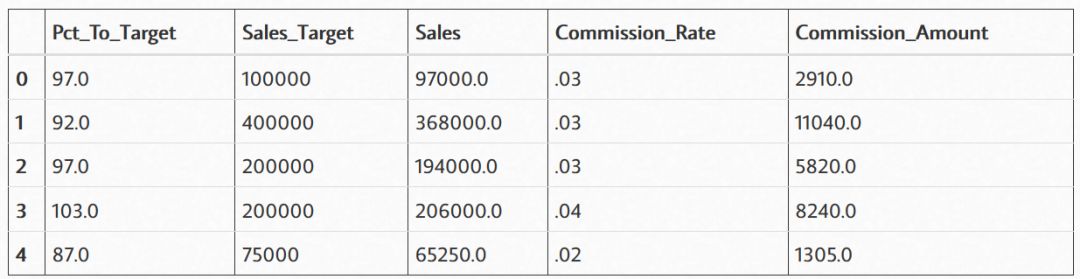
至此,我们完成了一次销售佣金预测。我们复刻了Excel中的算法,并且加入了两组随机分布的数组。从上表,可以计算出这次模拟的销售佣金支出为2,923,100美元。










