假定你是一个数据科学家, 老板给了你一组数据, 你来让机器完成这个预测的任务。就假定一定老掉牙的任务吧, 房价。 这也是大家所最关心的东西了。
用数据来预测的一个关键要素是寻找数据间的相关性,无论是谷歌搜索预测总统选举, 还是用数据推测买啤酒的用户是不是更容易买花生, 这些相关性都已经存在, 数据能够帮我们发现那些我们看不见的相关性,但是, 首先为前提的是, 相关性必须是已经存在的, 你不能从没有相关性的东西里预测另一个东西, 比如从今天天气的好坏预测汽车板块的股价。
如果给相关性换一个词,那就是信息。你增加的每个数据, 必须让你所要预测的东西更加确定, 否则就是噪声。那么, 什么是最简单的数据预测方法呢? 你所再熟悉不过的东西, 线性回归。
1 线性回归
回归这个词说的其实是一种由果索因的思维, regression拉丁语的原意, 是act of going back, 是回去,往回走的意思。 那么回的是哪里? 我们说, 如果一组变量间存在相关性,比如A,B,C都与D相关。 那么我们就认为A,B,C可以确定D 。 预测D也就是由D回到A,B,C的过程。 线性回归, 就是给A,B,C三者每个变量一个重要性的打分,称为权重,然后按权重对三个有影响的变量做线性带权加和。
让问题再简单一些,如果只保留A这一个影响因素, 你会发现D和A在一条直线上。 无论你一开始发现D的数据如何跳动, 你不停的收集数据, 它的平均数总是要回到那条直线上。
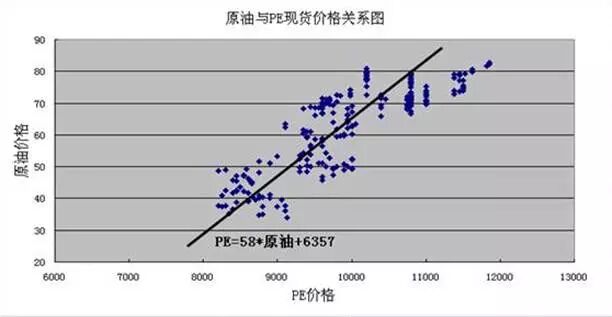
将线性回归的思路用在预测房产的价格,如果你打开链家的网站, 你会发现一个房子的价格决定于非常多的相关因素, 比如房子的地点, 房子的面积, 房子中卧室, 厕所,客厅的数量和面积, 周围环境的交通, 安静与否,有无学校等, 我们要从这些要素中知道房子的价格。如果你是老式的数据专家, 让你找到一个方法预测房价。你的方法一定是到各个地点做调查成交价,然后把它们画成一个表格。这个表格里, 前面是那些链接房产列出来的房屋属性, 最后一个是价格。 你会设法列出一个经验公式来, 比如刚刚的线性公式,然后你认为哪个因素比较重要, 就把前面的系数调大一点, 直到这个公式和你表里的公式符合的比较好。
这个老派数据专家的做法, 换一个专业的术语叫做拟合。 只要是学过中学物理的人对这个东西都不会陌生。 记得我们要求得一些重要参数吗, 比如重力加速度, 还是水的密度。 你的做法都是取不同体积的水, 计算它们的质量,然后把它们画在一张纸上,每一个点对应一次测量, 一般情况下, 你会发现所有的数据点在一条直线来拟合, 而这条直线的斜率,可以帮你计算出水的密度来。 这就是拟合, 也就是老派房价研究者的方法了。 你把房子的大小,屋子的数量算作显著因素, 然后把不同地区的房价平均值作为基准, 就可以给每个地方的房子拟合出这样一个曲线。
好了, 把这门直线拟合的技术交给电脑, 就是机器学习了, 你可以用python完成,也可以用excel。 就是这么简单。 事实上很多人也是这么说的, 它们管机器学习叫做拟合。线性回归一定不像你想的那么简单。 首先, 当下的数据, 早已不是以前那种两个或三个特征的数据。 如果你打开链接, 你可能发现近百个和房价有关的特征。
如果你是百度预测广告链接的人, 你会发现你的用户的特征成千上万。难道你不能挑出那些重要的吗? 问题是, 没有人能预先清楚哪些要素重要。
如果给一千个因素列出一个线性回归的公式, 然后把它们的系数解出来, 你看看这件事还容不容易呢 ? 即使是交给电脑, 也不是一两下可以算出。
更关键的是, 你其实预先并不知道你的这些特征有还是没有用, 我们要设计的算法, 要能从这些信息中首先识别, 然后学习价格的pattern(模式),然后得到这个关系。 在此之前, 老派人士的专业知识可以很好的帮我们滤清这个关系, 比如你可以很清晰的甄选出房子的大小和卧室数量很重要。 但是, 一旦特征多起来, 我想就会超出任何人的专业知识, 比如你是否能判断一个地区的男女比例对房价的影响呢?然后我们的数据也很多, 在这样多的数据下, 任何专家都会眼花缭乱。
所以, 我们要建立一个新的思维框架, 来让机器自己完成这个特别繁琐的任务。首先, 我们 把之前说的因素,属性换以一个新的词汇-特征。特征, 就是那些我们认为可以用来预测的因子, 无论它最终是否有作用。一个特征, 可以用一个数表示,更好的理解是它是空间里的一个坐标,就如同下x,y,z。 特征的个数我们通常称之为维度。
这样, 刚刚说的一个问题的特征很多, 我们就换作了一个新的词, 就是维度很高, “高维”, 问题越高维, 就是通常说的越复杂。 维度本身同时决定我们可能需求的数据量多少, 高维度意味着我们需要求解问题的信息量也成比例的增长。由于你我都很难想象高维空间的事情, 我们就拿二维来讲解, 以后, 机器学习就称为在平面画曲线的过程。
然后我们来说算法,特征如何决定预测对象, 哪些特征有用, 哪些没用,用处大小, 就是算法的事情。算法也可以看作机器学习模型,它就像一个机器, 这个机器输入进去数据, 输出我们要预测的对象, 听起来像不像一个函数呢? 但是它不是一个函数, 对机器学习模型更好的理解是一个框架,或者说一大类函数的综合。
比如刚刚我们说的线性回归。 作为机器学习模型的线性回归,可以看作包含了所有的这类很多因素相加的函数, 那些刚刚说的决定每个特征重要性的参数,叫权重。 每一组权重都对应一个特定的函数, 我们也叫它假设。 机器学习与函数的区别在于, 你所拥有的是这样一台机器,你把数据扔进去,它自动给你吐出一个最好的假设, 它能够最好的解释你的数据。
为什么叫模拟人类思维的机器学习模型? 因为这些假设的提出是直接从我们的思维转化的。 比如决定房价的方法就是不同的因素按照一定权重组合。最终得到这组最匹配数据的假设的好处是什么? 机器就可以自动做预测了。 我们不再需要房产专家, 我们用有限驾驭无限。 因为你用来得到这个假设的是你收集的有限的数据, 而你要预测的是无限的情况。
现在我们来说如何求得这个假设, 或者说最佳参数, 这个过程通常称为训练。训练用一句话总结,就是在错误中改进和学习, 假定你是一个房价预测元, 你的评估也许开始是按照自己的经验来是房子的面积比较重要还是地点比较重要, 但是之后他很快被上级打的一塌糊涂,之后在一步步调整权重。机器,也是一样, 我们要写一个程序,模拟小孩挨揍学习的过程。
和人学习的过程不同的是, 我们要从统计的角度, 设计一个自动调节的过程,之前所说的,机器学习模型就是一个框架,我们开始选择的假设(参数)一定是错误的, 而每个数据, 都按照给定的算法一步步的调整模型, 最终得到正确的算法。
我们来看如何得到这样一个训练算法, 首先, 你会发现由于我们手里有很多特征, 很容易找到一组参数得到完全准确的价格, 假定你有一个待回归的, 有三个特征, 每个特征都有对应的权重,从无数个特征对应权重的组合中找出对数据拟合最好的那个,就是我们的目标 。你也许会说, 这不就是解n元一次方程组吗, 比如你有三个数据,三组特征, 这就是一个三元一次方程组, 然后只要是符合一定条件, 它是有唯一解的。 但你手里不可能只有三个数据, 假定你有几十个几百个特征, 你的数据通常是这个特征的若干倍, 你只基于某几个数据求得的精确解一定会死的很惨。
机器学习训练的根本思维方法就是,我要根据所有的数据求解, 而使得所有数据都拟合的解一定不存在,我要做的是,首先量化模型造成的错误, 然后, 让这个错误最小, 这就是优化的思维。
首先说说量化错误, 记住, 我说的统计的观点, 我们必须针对全体数据衡量这个模型的错误, 这个东西, 通常叫cost function, 你可以理解为由于模型较差引起的花销, 或者是一笔罚款。 在这里, 我们可以把它简单定义为所有数据点预测误差的平方和。
一个要牢牢记住的观点是cost函数是参数的函数, 而不是特征的函数, 记得刚讲过的我们的预测由特征决定的吗? 这里, 我们的代价函数确是由参数决定的, 对应每一个参数, 或者每个假设, 它由一个值。 那些比较符号真实的假设,这个值就越低。你要找的那个模型, 就是错误最少的, 就是最接近真实的。 你可以用只有一个参数的情况做个实验,这个时候我们得到一个抛物线, 最优解就是那个初中你就会算的抛物线的谷底。 这, 就是最优点,在这里, 你就走上了人生巅峰。
寻找这个人生巅峰(谷底)的方法由很多, 这就是数学里的优化理论。 如果你是一个傻子, 你可以用遍历的方法找 , 也就是把所有情况试一遍, 人生不值得,这是一个很值得的事情。 但是, 如果你要讲点效率, 通常我们会换个思维。 ,实际操作中的方法称为梯度下降, 这个想法的核心是, 我不知道那个人生巅峰在哪里, 但是我知道当下每一步我能够做的最好的事情,就是沿着让我自己的cost代价函数下降最快的方向走一步, 就如同水总要向低留,而不是反过来。具体走多远, 步子不要太大别把巅峰给错过了, 也不要太小走的太慢了, 具体自己调一下。
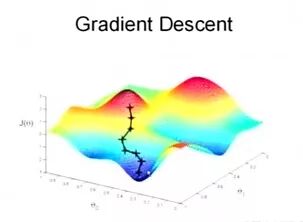
好了, 假定我们已经在这个人生巅峰, 你觉得是不是万事大吉了呢? 有没有一种可能, 是你的数据误导了你, 你发现海淀的房价很低, 但是事实上你手里只有一个海淀的数据 , 而这个房子还是凶宅呢? 这个闹鬼的屋子导致它的价格异常的低, 结果海淀区这个特征被学到了一个极低的房价, 你还自以为你处在人生巅峰。一旦换了下一个五道口的房子, 你就输惨了。
你的模型很强大, 它可以抓住海淀这个特征, 但是恰恰数据有问题, 结果, 你被舞蹈, 这个现象, 构成一个机器学习的核心概念, 过拟合。 它所引出的, 是机器学习和简单的函数拟合的根本区别, 机器学习要的不是最好的拟合一条线, 而是举一反三的泛化能力。
如果你拟合的很好, 而在新数据面前变成弱鸡, 那就一定不是好模型。过拟合最好的例子是星座, 比如你认为有几个星星, 你就想出这像一个大熊。 事实上它可能还是仙鹤, 还是汽车。 无论哪个, 你的观测都不至于让你推断它真的和任何一个动物神似, 你确偏偏从这极少的数据中推到一个结论。 可以想象的是, 如果这些星星真的是某个动物的一部分, 你从这里得到的模型换一组星星一定错 。如果说机器学习预测是模式识别, 过拟合就是一种走火入魔, 从噪声里读出了模式。
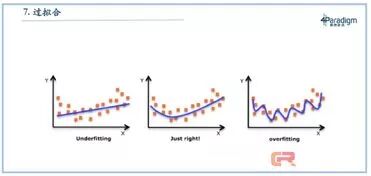
这也告诉我们数据的重要性, 要不你的数据很干净, 没有那些鬼屋一类的脏数据。要不,就是你的数据很多, 有几个脏数据会被很多的好数据纠正。 当然我们也可以从模型角度入手,让它更聪明的去除噪声。
二 做分类的几种方法
分类和回归的区别仅在于预测的数据类型不同, 一种预测的目标是如价格, 人的身高, 国家GDP这种连续的值,后一种通常是预测类别,比如男人女人, 有病没病。 但是在数学上这会造成很大的区别, 所以被分入到两个大类里面。
如果你翻开机器学习的字典, 分类问题独具鳌头, 几乎占领了大部分算法的席位。为什么分类如此重要, 依然类比人类的智能, 我们日常生活中, 大部分都在做是和否的判断,一个东西能不能吃, 一个地方能不能去, 这些大大小小的判断, 都可以看作是分类问题。 因此, 掌握分类, 也成为让机器掌握智能的关键。
设想一个最简单的问题, 莫过于分辨物体, 一个机器学习特别俗套的问题就是分辨鸢尾花儿, 这种十分美丽的植物有很多品种但都相似,有一个著名的植物学家收集了所有这类花的数据,然后构建了一个数据集, 这个数据集后来被机器学习专家用作了一个经典的试验所, 你像做一个自动的分类器, 就先拿它来试。

如果让你构建这样一个分类器, 什么是第一要素呢? 刚刚我们讲了模式隐藏在特征之中, 与你预测相关性越高的那些特征作用就越大。 此处, 构建分类器的第一步也就是抓取关键特征, 当然这一步已经被植物学家完成, 一般来说, 这类花最大的分别度在于花瓣和萼片的长度, 这也正是植物学家要提取的特征。 大家注意这一步是传统机器学习的关键, 在深度学习以前, 它决定了学习的成败, 而特征提取, 也特别需要专业知识。
好了, 有了关键特征, 我们如何进一步让机器来辨识花儿? 想象下人的情况, 你最常用的思维方法是什么? 做比较! 我要预测华清嘉园的房子价格, 你最可能做的是看看旁边和它差不多的展春园的价格怎么样, 就可以估测的八九不离十。
那么机器也是一样的 我们完全可以寻找那些和我目前数据最相近的数据,然后由它们确定我的数据的类别。 这个方法, 就是机器学习的KNN-K最近邻法。 当然,我们这里所说的最近, 不是那个地理的最近, 而是特征空间里得最近。说到近, 就要有距离的概念。 我们可以用初中学习的勾股定理计算欧式距离, 也可以用其它非常多的距离计算方法。比如拿两个特征得情况, 这个时候, 我们有一个特征平面, 那个这个距离就和我们所说的平面上两点的距离没有区别。总之, 你要量化这个数据间的差别大小 , 然后, 就可以通过距离做预测。
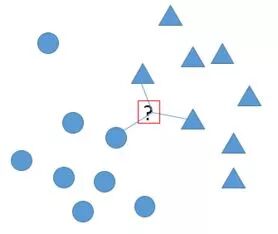
金融投资在评估企业价值的时候有一个价值比较法。首先, 你要得到一组决定公司估值的特征, 然后, 你要按照这个特征公司放到这个空间里, 最后,寻找与你要估值公司最近的公司经过一系列校准进行估值。
KNN依然可以用于分类,也可以用于回归。 只要你有足够多的数据点, 而且特征不太多, 就不可以用。 为什么说特征不太多呢? 因为你我都不擅长思考高维空间的几何。 但是数学家可以证明, 在极高维度的空间里, 随着数据变的稀疏,距离这个概念并不是特别有用, 因为大家的距离其实都差不多。
这个时候, 建立在距离之上的KNN就没有那么好用了。 但是这样的例子实际上非常之多, 尤其是在自然语言识别上。比如一类经典的问题就是考证一些经典的作者:
1787年5月,美国各州(当时为13个)代表在费城召开制宪会议;1787年9月,美国的宪法草案被分发到各州进行讨论。一批反对派以“反联邦主义者”为笔名,发表了大量文章对该草案提出批评。宪法起草人之一亚历山大·汉密尔顿着急了,他找到曾任外交国务秘书(即后来的国务卿)的约翰·杰伊,以及纽约市国会议员麦迪逊,一同以普布利乌斯(Publius)的笔名发表文章,向公众解释为什么美国需要一部宪法。他们走笔如飞,通常在一周之内就会发表3-4篇新的评论。1788年,他们所写的85篇文章结集出版,这就是美国历史上著名的《联邦党人文集》。
《联邦党人文集》出版的时候,汉密尔顿坚持匿名发表,于是,这些文章到底出自谁人之手,成了一桩公案。1810年,汉密尔顿接受了一个政敌的决斗挑战,但出于基督徒的宗教信仰,他决意不向对方开枪。在决斗之前数日,汉密尔顿自知时日不多,他列出了一份《联邦党人文集》的作者名单。1818年,麦迪逊又提出了另一份作者名单。这两份名单并不一致。在85篇文章中,有73篇文章的作者身份较为明确,其余12篇存在争议。
像这样一个问题, 在没有机器学习的时代, 可以耗费一个考据学家10年20年也不一定能有结果。 但是用机器学习一个叫朴素贝叶斯的方法, 就可以解开。(参考贝叶斯推理实用入门)
我们来看这个方法是怎么样的,首先, 不同的作者写作风格的差异很大体现在用词上, 因此, 我们可以找到一组两个作者都会使用但是和使用频率不同的关键词作为特征。 我们可以想象, 这个特征的数量很大。 然后, 我们可以统计在作者身份明确的稿子里这些词出现的频率, 已经身份明确的稿子的总量有了这个信息后。
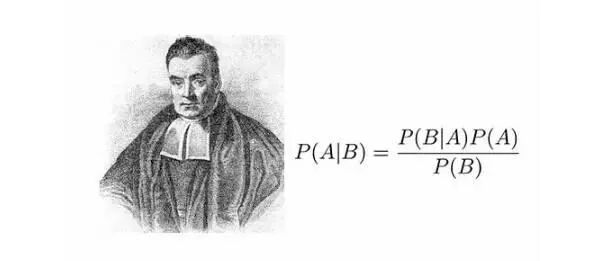
我们就可以展开贝叶斯公式, 直接计算某个稿子是某人的概率, 当然, 这里出现了一组包含很多特征的条件概率, 朴素贝叶斯的核心, 就是假定特征之间是独立的吗, 这样,我们就可以展开成概率连乘的形式, 在这个连乘的形式里,我们看到了我们刚刚计算的那些频率, 如此, 我们就可以直接计算出谋篇未知文章的概率。 神奇的是, 朴素贝叶斯可以对一些从未出现过的特征组合做预测,只要那些特征之前出现过就好。
关于多个特征下的分类, 事实上最常用的方法是一大类被称为树模型的家族, 而最基本的称为决策树。 它能体现好几个人类理性的基本要素。
决策树是一个极为典型的模拟人类逻辑的思路,简单的说, 决策树就是分而治之。按照特征把事物分成很多小组,然后对所有的情况分开判断, 如果A符合某条件就是是, 不符合就是否。我在简史课里给大家讲过这个分而治之最大的问题是要列举的可能太多了, 假定你有N个特征, 每个特征两个情况,你就有2的N次方个组合的情况, 要做到天网恢恢疏而不漏, 那得看到什么时候。
而决策树得核心智慧, 就是优先级算法, 虽然特征很多, 但是并不是每个特征都一样重要, 我们如果先按照最重要得特征进行判断, 依此往下, 你可能不需要2得N次方个情况, 而是按照树结构做N次判定即可。 优先级, 也是人类智慧得核心,事实上, 我们永远在抓轻重缓急,在抓主要矛盾, 无论是有意的还是无意的,当然大部分人的轻重缓急是按照时间来的,时间比较近的就是比较重要的, 这也是为什么很多人有拖延症。
很多人说到优先级算法很想到相亲, 其实这也是一种人类思维自然使用的决策树, 比如女生找男朋友通常心理都有一个优先级构成的树, 首先, 对方的年龄多大? 如果对方年龄大于50岁直接pass, 然后看工资,如果工资小于20万直接pass,工资在20和30万间看下学历, 学历小于本科直接pass。 这其实就是一个决策树的结构。
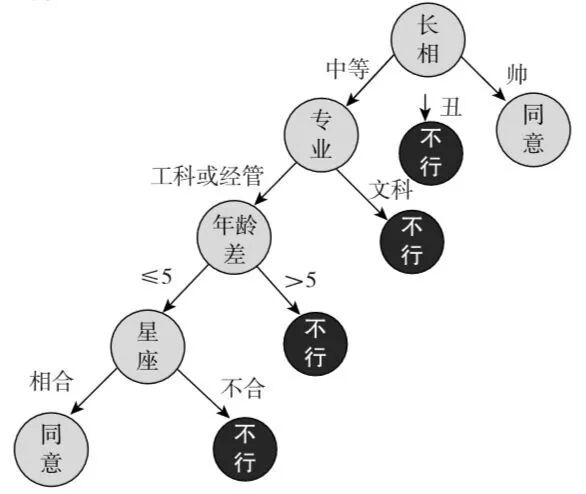
那么从机器算法的角度看,算法是完全类似的, 你可以把整个问题看成一个树,树的根部是你选择的第一个特征, 更好的角度是把特征看成一个问题,树的根部是你要问的第一个问题, 根据这个问题的回答, 数据会在左边右边分成两组。 然后在每个答案的基础上, 你继续问下一个问题, 所谓的决策树的分叉, 每个枝杈就是一个新的问题。 如此,就会形成一个树的结构。
构建这个树的主要难点, 在于要由机器决定哪个问题先问, 哪个问题后问, 如何选择这个优先顺序? 这我们又回到数学物理一个古老而重要的概念 – 信息。 记得我说的信息是特征与预测的相关性吗? 这里, 同样的套路换一个思路, 那就是, 你每增加一个问题,我的预测从模糊变得清晰了吗? 变清晰了多少? 如果你是一个人的话,就是你比先前更肯定了多少? 变得清晰的越多, 变得肯定的越多, 这个问题就是能够给我们带来更多的信息。 能够增加最多信息的特征,就是优先特征。 我们可以做一个思想实验,还是人们用举决策树相亲的例子, 假定你要找一个男生, 告诉你它不会做菜, 这个一般情况下, 对你判定要不要见他影响不大,因为大部分男生都不会做菜 ,而且一般你也都会叫外卖。它在数字上的表现是什么? 就是来了10个男生,5个被你pass, 5个被你保留, 但是两边的人里做菜的数量和不会做菜的数量都差不多。
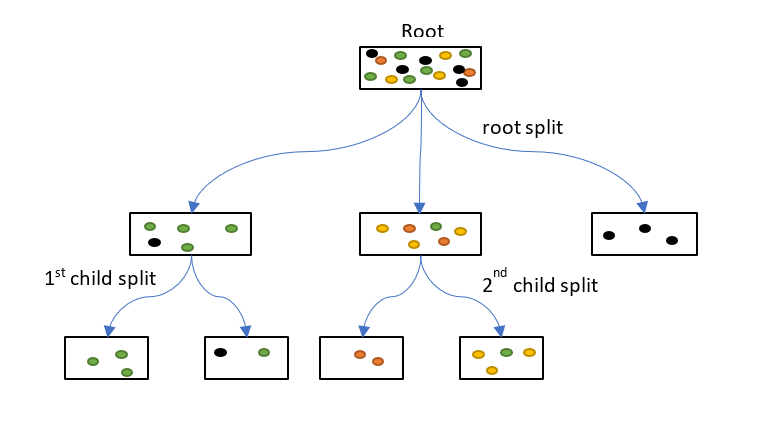
用数学的角度看, 这就是信息熵, 你问了这个问题, 信息熵不变,这就是一个很糟糕的问题。而如果你问的是年龄呢? 年薪呢? 显然两边的yes or no的比例会非常不同。 因此,年龄或年薪带来的信息增益就更多。 建立决策数的一种经典方法所谓ID3, 就是把描述的这些变成程序了。刚刚说的过程非常容易的称为一个迭代的过程。 迭代的起点是哪个信息量最大的问题也就是父问题, 然后, 根据回答的yes or no把样本分堆, 每个堆里会出现一个最终预测标签的分布, 根据同样方法选择子问题, 在子问题之下样本继续分堆, 预测标签重新分化, 我的要求就是, 每一次分化, 结果的分布都更纯净, 每个问题回答的yes or no下, 都是同一个标签。 最终达到稳定后过程停止。
这样形成的决策树, 我们会形成任何一个情况下的优先级。 或许长的帅的人工资不重要。 或许学历高的人年龄不重要。 这种不同情况不停调整优先级的思维, 真的是被决策树利用到了极致! 从原始数据里提炼的决策树, 可以对无限的新情况进行预测。
三 降维与聚类
我们刚刚讲过的几种简单的回归与分类方法, 事实上都建立在一个基础上, 就是你的数据必须包含连个部分, 一部分是特征, 一部分是预测对象的值。 这对于数据的要求其实还挺严格的。 但是, 如果我手里拿到一大批数据, 但是这批数据偏偏没有要预测的值呢? 我们是不是就无能为力了呢? 不是这样的, 还是以刚刚的房价数据为例, 如果我把那些房子的价格都抹掉, 你可以做什么呢?
事实上,机器学习模型依然可以帮助你发现数据的内在结构。 即使这些结构不能帮助你预测价格, 却可以对你产生重大的启示。
还记得我们刚刚说过的那个问题, 现在的数据经常具有非常多的特征, 我们称之为高维吗? 但是你要知道, 真实的数据里通常没有那么大的信息量。 比如刚刚的房价数据, 你看到的那个车库的面积其实和房屋的总面积是高度正相关的, 这就说明, 信息里存在大量冗余。 这种冗余信息, 有时候对你分析和理解数据没有好处。
我们会介绍一个方法叫PCA。什么是PCA? PCA- 其名称 principle component analysis 就是一种能够从高维度数据里提取信息的方法。PCA让我们假设数据的特征分布符合高斯分布,但是特征不是独立的,而是存在大量线性相关的特征, 线性相关的特征使得数据的表现维度高于真实维度, 这将加深维度灾难,使得训练缓慢。
你想把这些冗余数据去掉, 你想给老板画出一份漂亮的数据分析报告, 直接告诉它数据里的那些特征是最主要的, 或者你想把一些比较表面的特征化城一个更本质的合成指数,比如房屋综合质量指数? 这时候, 我们可以用PCA。PCA, 其实做的是一个坐标变换, 把线性相关的特征合成一个, 重新合成一组正交的特征。听着有点晕,可以画图看一下。
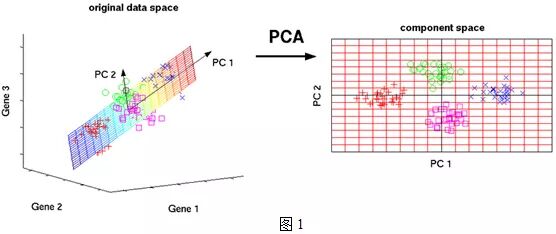
我们知道,要显示两个不同的特征是否线性相关的做法一般是求解其谐方差, 如果我们所有特征的两两相关系数放到一个矩阵里,这个时候得到一个矩阵叫谐方差矩阵, 这已经是对我数据内部的相关性的最好的表示。我们知道,要抽取一组特征里的相关性。
我们想象,如果把特征看成一个向量空间,我们第一段描述的那个事情,无非是要找到那么一组基底,让原来的数据在新的空间里线性无关,换句话也就是说原来的数据在经过一个线性变换后, 数据可以被投影到一组正交的特征上, 新的特征之上, 每个特征尽量独立。
这里我给我们的PCA流程加入一个细节, 就是在求解特征根前不仅要减去均值,还要让每个方向的方差值相等,也就是说, 进入处理之前得到的矩阵对角线是相等的。这个过程叫做归一化,归一化对我后面要说的一件事至关重要。
我们得到的这个E矩阵是个对角阵,每个值代表的是新特征的方差, 我们把方差从大到小排列,并且重整其特征向量的顺序得到最终的坐标变换矩阵。那么我要问大家,为什么一开始的特征方差是相等的,而后面不同不同了?正是因为存在线性相关的特征,而新的特征进行了特征的重组之后把线性相关的特征进行了重新组合,使得原先均等的方差变得不等了, 你可以理解为如果存在大量变化趋势相同的更向量,使得数据的方差在某个放向加强, 比如说在一个股市大盘里很多股票是正向关联变化的, 这样的方向我们通常称之为主成分。排在头上的特征又被称作第一主成份。 如果是股市,我们可以想象为它是引领股市变化的板块。
如果我们的数据是很多篇文章,每个文章是一个数据点,特征是一组关键词在文章的频率, 如果我们做这样一个PCA的工作, 就会实现对一些类似文章中常出现的文章被聚集在一个新特征上。新特征就是这样类似单词的组合, 每个新特征, 都代表了一系列文章。 比如政治类很可能被聚成一类, 而其它也如此。
PCA的本质,就是寻找数据内的冗余维度, 一言以蔽之, 就是找核心矛盾。 在众多特征里找到最重要的特征。 PCA可以实现对复杂特征的降维处理,大家注意, 这也是我们接触的第一个无监督算法。因为你的数据无需包含你要预测的变量, 比如刚刚说的文章的例子, 你并不需要有文章类别有关的信息,PCA还是可以帮你把你数据库的主成分抓出来。
因此用PCA你也可以实现压缩, 比如你电脑里的电影,大型游戏,和照片,大多存储称为JPDEG压缩格式, 它们的本质其实也是降维, 把原始数据格式的照片, 用一套新特征,给编码出来, 这套新特征, 比之前的数据要少很多, 但是保持大部分信息。由于保存了大部分信息, 你打开一张Jpeg照片和原始格式照片并不能区分很大。
而PCA,则是一个最简单的压缩方法。 在刚说的机器学习方法里,压缩了的数据往往更加好用, 这里面教给我们的, 一个是数据不等同于信息,你的数据量大, 不一定信息就多, 事实上数据的维度表现很高, 而真正的信息其实往往没有那么多维度。 而以PCA为代表的降维工具, 就是让我们实现这种对信息的浓缩, 让我们节省大量计算机硬盘还是我们大脑资源的同时, 得到最难主要的信息。
当你手里的数据特征太多维度灾难发生的时候,你的电脑根本跑不动,这个方法就十分有用。一类是你缺乏带标注的数据, 这种情况十分常见, 因为数据的标注是最昂贵的, 这种昂贵的情况最好的解决方法就是先用没有标注的数据提取它的信息。 而无监督学习是极好的工具。用PCA对大量无标注信息做训练, 然后得到的新特征用于少量标注数据的有监督学习,会省掉不少麻烦。
大家注意任何模型的都是都是错的,有些是有用的。 什么时候有用, 取决于我们的假设。 我们对PCA的假设是数据符合高斯分布, 当然,实际中数据可能不符合这种假定, 但并不代表模型不能用, 因为所有模型都是错的, 只是它的有用性会打个折扣。
降维不仅在机器学习里, 而且在日常生活里是一个重要的思维方法,人脑能够处理的信息量极少,降维,抓住主要矛盾,所谓擒贼先擒王,是人生的制胜法宝。
最后提一句聚类,所谓聚类算法, 也是在没有预测标签的时候我们可以玩的一个方法, 只不过, 这个时候我们是要根据特征的相似度, 把数据分成一撮一撮的, 说不定, 这样我们就可以发现一个新物种, 或者一个具有特别商业价值的客户群。这里常用的方法K-means也是基于数据点在特征空间上距离的,类似之前提到的KNN。先随机给出K个簇的中心点,再一步步的根据数据调整当前的中心簇的位置,从而使数据能够分开。
更多阅读
与不确定性作战-从物理模型到特征提取









