
本文为 AI 研习社编译的技术博客,原标题 :
Credit Scoring with Machine Learning
作者 | Hongri Jia
翻译 | 胡瑛皓
校对 | 酱番梨 审核 | 约翰逊·李加薪 整理 | 立鱼王
原文链接:
https://medium.com/henry-jia/how-to-score-your-credit-1c08dd73e2ed
注:本文的相关链接请访问文末【阅读原文】
信用评分是衡量人们信用的数字表示。银行业通常用它作为支持信贷申请决策的方法。本文讲述如何用Python(Pandas、Sklearn)开发标准评分卡模型,它已成为一种最受欢迎且最简单的衡量客户信用的形式。

如今信用对每个人来说都非常重要,因为它是衡量一个人是否可靠的一种指标。很多时候服务提供商在提供服务前会先评估客户的信用记录,然后决定是否提供服务。可是审核个人资料并手工生成信用报告是非常耗时的。信用评分节省时间而且容易解读,所以就被开发出来服务这些目的。
产生信用分的过程称为信用评分,它被广泛应用于许多行业特别是银行业。银行通常用信用分决定谁应该授信、授信额度是多少、使用什么样的操作策略去避免信用风险。总体来说主要是两部分:
建立统计模型
应用统计模型为信用申请或现有信用帐户打分
本文会介绍最受欢迎的信用评分方法,我们称为评分卡模型。有两个原因使其成为主流的方法。首先,评分卡模型很容易跟没有相关背景和经验的人(诸如客户)解释说明。其次,评分卡模型的开发过程很标准且被广泛接受,这意味着公司不需要投入太多研发经费。以下是评分卡的样例,后面会讲到如何使用。
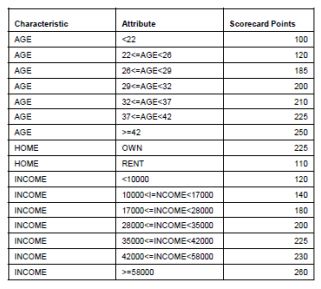
图1 评分卡样例
接下来将详细说明如何开发评分卡模型。我用的数据集来自Kaggle竞赛。 图2列出该数据集的数据字典信息。其中第一个变量是目标变量,二元分类变量,其余变量是特征。
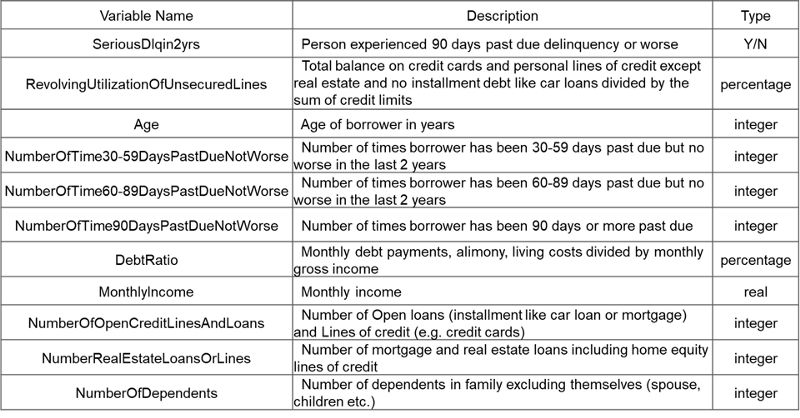
图2 数据字典
浏览完数据后,开始用一些特征工程的方法处理一下数据。首先检查每个特征变量是否包含缺失值,然后用中位数估算补齐。
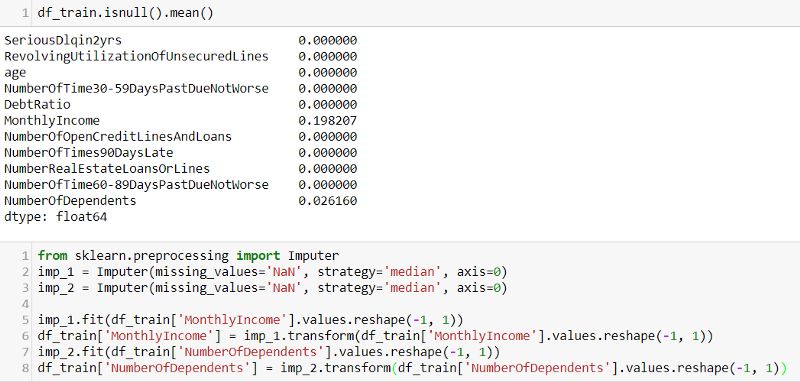
接下来处理异常值。总体来说,需要根据异常的类型进行处理。例如 如果异常值是由机械错误或测量导致的,可以用缺失值的方法进行处理。在这个数据集中有很大的数值,不过这些值看起来都很合理,所以取top/bottom coding。图3中表明当采用top coding后,数据分布看起来更接近于正态。
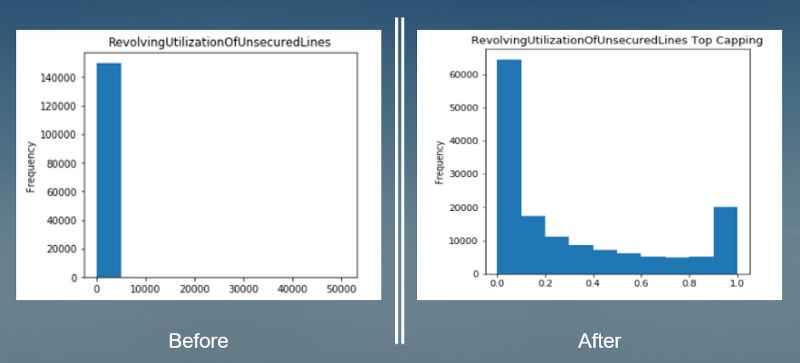
图3 用Top coding处理异常值
如图1中样例评分卡所示,很显然每个特征已被分组为不同的属性(或属性组),分组原因如下:
那么我们可以采用分桶法,处理后每个值被赋予它所应在的一个属性,这样一来数值特征便被转化为分类特征。以下是分桶后的输出样例。
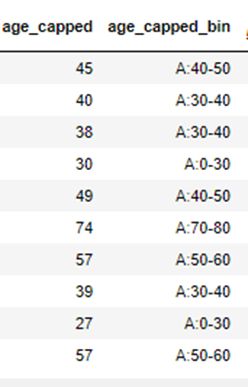
图4 分桶处理“年龄”
所有特征分组后,特征工程就完成了。接下来是计算每个属性的证据权重(WoE)以及每个特点(特征)的信息价值。之前提到将所有数值类型都分桶处理后转换为分类型特征。然而不能直接用这些分类模型去拟合模型,所以需要给这些分类特征赋予一些数值。计算证据权重(WoE)的目的是为每个分类变量分配一个唯一值。信息价值(IV)用来衡量特征的预测力,将被用于特征选择。下面给出WoE和IV的公式。这里“Good”意思是客户不会有严重逾期或者目标变量=0,而“Bad”客户会产生逾期目标变量=1.
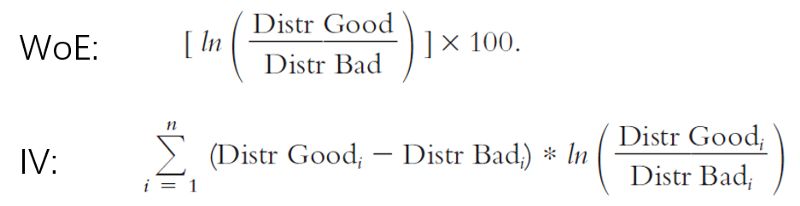
通常特征分析报告可提供WoE和IV。我在Python中定义了一个函数自动生成这个报告。以“Age”特征为例,其特征分析报告如图5所示
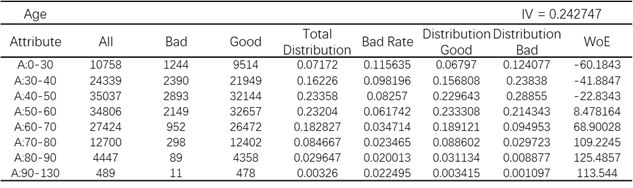
图5 “Age”特征分析报告
绘制一张柱状图,方便比较各种特征的IV。从柱状图中可以看到最后两个特征“NumberOfOpenCreditLinesAndLoans”和 “NumberRealEstateLoansOrLines”的IV值较小,因而只选用其他8个特征训练模型。
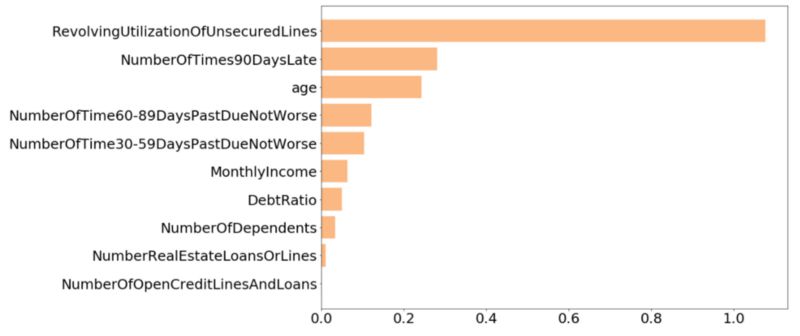
图6 特征预测力
特征选取完成后,用WoE替换原有变量的值进行建模。训练模型的数据已经准备好了。评分卡模型开发通常使用的模型是逻辑回归,它是一个通用的二分类模型。我通过交叉验证和网格搜索调整参数,然后用测试数据集检查模型的精度。 由于Kaggle不会给出目标变量的值,我不得不在线提交以获得精度。为了证明这些数据处理是有效的,我分别用原始数据和处理后的数据进行建模。Kaggle给出的结果,经过数据处理精度从0.693956提升至0.800946。
最后一步是为每个属性计算评分卡得分系数,这样就得到了最终的评分卡。评分卡模型的得分可以通过以下式子计算得到:
Score = (β×WoE+ α/n)×Factor + Offset/n
此处:
β —含 给定属性的逻辑回归模型的系数
α —逻辑回归模型的截距
WoE — 给定属性的证据权重
n —模型特征数量
Factor, Offset — 缩放参数
前四个参数的计算方法在前面已经提到过,这里给出最后两个参数factor和offset的计算方法。
这里pdo意思是加倍odds需要的点数,坏样本率在之前的特征分析报告中已计算过了。如果评分卡模型的基础odds是50:1,其得分为600,那么pdo=20 ,也就是说每增加20点odds翻一倍,具体来说factor和offset公式如下:
Factor = 20/Ln(2) = 28.85
Offset = 600- 28.85 × Ln (50) = 487.14
算完这些之后,评分卡开发就完成了,图7中列出了评分卡的部分结果。
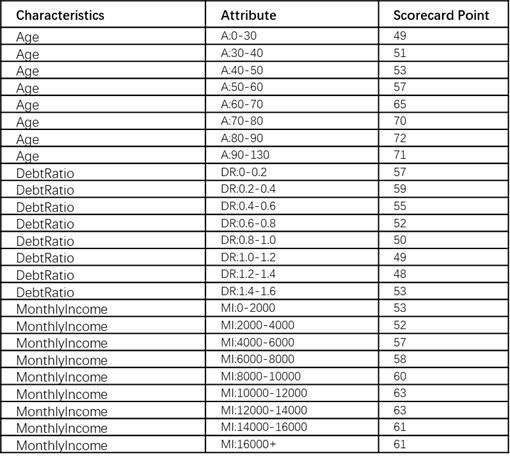
图7 最终评分卡 部分特征
如果来了一个新客户,你可以立刻查表找出特征对应的得分,然后评分卡最终的得分是每个特征得分值之和。比如说,银行开发了一位新的信用卡申请人,年龄45岁、负债率0.5、月收入5000美元。其信用评分为 53 + 55 + 57 = 165。
如需要开发更精准的评分卡,开发人员需要考虑更多场景。例如有些个人属于“Bad”,然而申请却通过了。或者一些个人属于“Good”,但申请被拒绝。因此拒绝推断需要结合到开发过程中。这里并未实现,因为在我的数据集中缺少拒绝数据。如果你想更深入了解这部分,推荐你阅读Naeem Siddiqi写的 《Credit Risk Scorecards — Developing and Implementing Intelligent Credit Scoring》。
想要继续查看该篇文章相关链接和参考文献?
点击底部【阅读原文】即可访问:
https://ai.yanxishe.com/page/TextTranslation/1626
点击阅读原文,查看本文更多内容↙









