作者/Jan
未经授权,谢绝转载
01
Layer 1应该关注状态
如果我们认为区块链分层是未来的发展方向,我们应该从一开始就考虑到上层协议和分层网络的需求,在分层的大框架下去设计区块链协议。
换句话说,从分层的角度来看,现有的区块链设计方式都是过时的。现有的区块链在设计时考虑的是特定的功能(例如支付,或者是运行DApp),并希望在运行一段时间后让上层协议来适应自己。然而如果我们阅读互联网的历史就知道,今天互联网的协议分层不是这样打补丁打出来的,相反是在吸收过去经验之后。这是为什么区块链并不天然是Layer 1,Layer 1是需要设计的。
要弄清Layer 1应该关注什么,先要弄清楚它和上层协议的区别。Layer 2起源与我们发现公有链(这里指permissionless blockchain)的性能不足,很难扩容到满足整个加密经济体需求的水平,同时我们又非常迷恋公有链提供的可用性和极大的服务范围,因此慢慢演化出了一系列可以由区块链来保证安全的Layer 2协议,例如支付通道(payment channel)、 plasma,etc.
这些协议的共同特点是牺牲共识范围来换取性能。公有链最让人惊艳的地方是通过开放网络提供不间断的覆盖全球的服务,这意味着全球共识,也意味着性能底下。
解决这个问题的最好方式是将大部分交易转移到共识范围更小但是性能更好的上层协议中,并且保证上层协议的参与者总是可以在不满意的时候退回到区块链上来解决问题,代价仅仅是一些时间成本。
因此作为Layer 1的区块链,关注点显然不应该是性能,因为Layer 2会承担这个职责。Layer 1是保障上层协议参与者的最后防线,它的关注点应该是安全和去中心化。如果我们观察Layer 2协议与Layer 1交互的模式,我们还会发现,Layer 1负责的是状态共识(存储),Layer 2负责的是状态生成(计算)。
02
状态是什么
如果Layer 1的关注点应该是状态而不是计算 , 在设计Layer1区块链的时候,我们就需要先理解什么是区块链的状态。理解了状态是什么,我们才能理解状态爆炸是什么。
区块链网络中的每一个全节点,在网络中运行一段时间之后都会在本地存储上留下一些数据,我们可以按照历史和现在把它们分为两类:
历史:区块数据和交易数据都是历史,历史是从Genesis到达当前状态的路径。
状态(即现在):节点在处理完从Genesis到当前高度的所有区块和交易后形成的最终结果。状态随着区块的增加一直处于变化之中,交易是造成变化的原因。
共识协议的作用是通过一系列的消息交换,保证每一个节点看到的当前状态是相同的,而实现这个目标的方式是保证每一个节点看到的历史是相同的。只要历史相同(即所有交易的排序相同),处理交易的方式相同(把交易放在相同的确定性虚拟机里面执行),最后看到的当前状态就是相同的。当我们说「区块链具有不可篡改性」的时候,指的是区块链历史不可篡改,相反状态是一直在变化的。
有趣的是,不同的区块链保存历史和状态的方式不同的,其中的差异使得不同的区块链形成了各自的特点。由于这篇文章讨论的话题是状态,而影响状态的历史数据主要是交易(而不是区块头),接下来的讨论历史的时候会侧重交易,忽略区块头。
03
举个例子:Bitcoin的历史和状态
Bitcoin的状态,指的是Bitcoin账本当前的样子。Bitcoin的状态是由一个个UTXO(尚未花费的交易输出)构成的,每个UTXO代表了一定数量的Bitcoin,每个UTXO上面写了一个名字(scriptPubkey),记录这个UTXO的所有者是谁。如果要做一个比喻的话,Bitcoin的当前状态是一个装满了金币的袋子,每个金币上刻着所有者的名字。
Bitcoin的历史由一连串的交易构成,交易内部的主要结构是输入和输出。交易更改状态的方法是,把当前状态中包含的一些UTXO(交易输入引用的那些)标记为已花费,从UTXO集合中移出,然后把一些新的UTXO(这个交易的输出)添加到UTXO集合里面去。
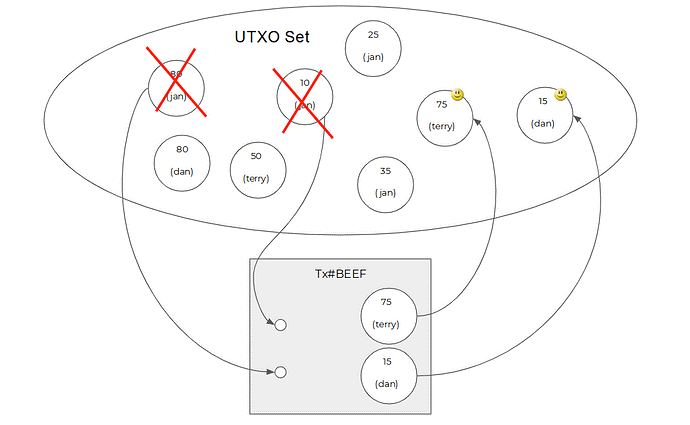
可以看出,Bitcoin交易的输出(TXO,Transaction Output)正是上面说的UTXO,UTXO只不过是一种处于特殊阶段(尚未花费)的TXO。因为构成Bitcoin状态的组件(UTXO),同时也是构成交易的组件(TXO)。
由此,Bitcoin有一个奇妙的性质:任意时刻的状态都是历史的一个子集,历史和状态包含的数据类型是同一维度的。交易的历史(所有被打包的交易的集合,即所有产生过的TXO的集合)即状态的历史(每个区块对应的UTXO集合的集合,也是所有产生过的TXO的集合),Bitcoin的历史只包含交易。
在Bitcoin网络中,每一个区块,每一个UTXO都要持续占用节点的存储空间。目前Bitcoin整个历史的大小(所有区块加起来的大小)大约是200G,而状态的大小只有大约3G(由大约5000万个UTXO组成)。Bitcoin通过对区块大小的限制很好的管理了历史的增长速度,由于其历史和状态之间的子集关系,状态数据大小必然远小于历史数据大小,因此状态增长也间接的受到区块大小的管理。
04
再举个例子:Ethereum的历史和状态
Ethereum的状态,也叫做「世界状态」,指的是Ethereum账本当前的样子。Ethereum的状态是由账户构成的一棵Merkle树(账户是叶子),账户里面不仅记录了余额(代表一定数量的ether),还有合约的数据(例如每一只加密猫的数据)。Ethereum的状态可以看作一个大账本,账本的第一列是名字,第二列是余额,第三列是合约数据。
Ethereum的历史同样由交易构成,交易内部的主要结构是:
to:另一个账户,代表交易的发送对象
value:交易携带的ether数量
data:交易携带的任意信息
交易更改状态的方法是,EVM找到交易发送的目标账户,
1.根据交易的value计算目标账户的新余额;
2.将交易携带的data作为参数传递给目标账户的智能合约,运行智能合约的逻辑,在运行中可能会修改任意账户的内部状态生成新的状态;
3.构造新的叶子存放新的状态,更新状态Merkle树 。
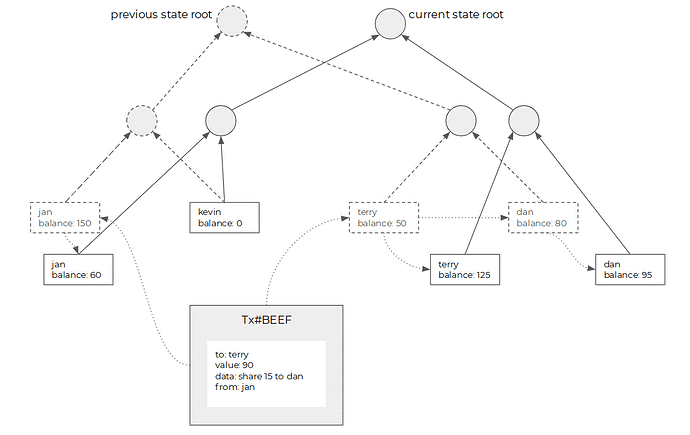
可以看出,Ethereum的历史和交易结构与Bitcoin相比有非常大的不同。Ethereum的状态是由账户构成的,而交易是由触发账户变动的信息构成,状态和交易中记录的是完全不同类型的数据,二者之间没有超集和子集的关系,历史和状态所包含的数据类型是两个维度的,交易历史大小与状态大小之间没有必然的联系。
交易修改状态后,不仅会产生新的状态(图中实线框的叶子),而且会留下旧的状态(图中虚线框的叶子)成为历史状态,因此Ethereum的历史不仅仅包含交易,还包含历史状态。
因为历史和状态属于不同的维度,Ethereum区块头中不仅仅包含交易的merkle root, 也需要显式包含状态的merkle root。
Ethereum中每一个区块,每一个账户都会持续占用节点的存储空间。Ethereum节点在同步的时候有多种模式,在Archive模式下所有的历史和状态都会保存下来,其中历史包括历史交易和历史状态,所有数据加起来大小超过了2TB;在Default模式下,历史状态会被裁剪掉,本地只保留历史交易和当前状态,所有数据加起来大约是170G,其中交易历史大小是150G,当前状态大小是10G。
Ethereum中所有的开销管理都被统一到gas计费模型之下,交易的大小需要消耗对应的gas ,而每一条EVM指令消耗的gas,不仅考虑了计算开销,也将存储开销考虑在内。通过每个区块的gaslimit,间接限制了历史和状态的增长速度。
ps. 常见的一个误解是,Ethereum的「区块链大小」已经超过1T了。从上面的分析我们可以看到,「区块链大小」是一个非常模糊的定义,如果把历史状态算进去,确实超过了,但对于全节点来说,把历史状态删掉没有任何问题,因为只要有Genesis和交易历史,任意时刻的历史状态都可以重新被计算出来(不考虑计算需要的时间)。
真正有意义的数据,是全节点必须的数据的大小,Bitcoin是200G,Ethereum是170G,两者是基本相同的,而且在平均配置的云主机都能装下,因此人们观察到的Ethereum全节点减少并不是由于存储增加导致的(根本原因是同步时的计算开销)。
考虑到Ethereum的历史长度(当前区块的timestamp减去genesis的timestamp)不到Bitcoin的一半,可以看出Ethereum的历史和状态大小增长更快。











