
2018年加入去哪儿网技术团队。目前在火车票事业部/技术部小组。个人对一切未涉及的领域有浓厚兴趣。
概要
本文主要讲解 Adaboost 算法:
1.Adaboost 算法的介绍;
2.Adaboost 算法类库的介绍;
3.Adaboost 算法实践示例;
4.Adaboost 算法原理;
5.总结。
通过文本的介绍,希望大家可以掌握 Adaboost 算法的使用与了解它的原理。
参考资料
1.Adaboost 原理分析与实战;
2.Adaboost 算法原理小结;
3.Adaboost 类库使用小结;
4.书籍:周志华-机器学习;
5.维基百科-AdaBoost 详解。
Adaboost算法介绍
Adaboost 属于集成学习 boosting 系列算法。 Boosting 算法的工作机制是首先从训练集用初始权重训练出一个弱学习器 1 ,根据学习误差率更新训练样本的权重,将弱学习器 1 学习误差率高的训练样本的权重升高,让这些样本在弱学习器 2 中得到更多的重视。然后基于调整权重后的训练集来训练弱学习器 2. ,如此重复进行,直到弱学习器数达到事先指定的数目 T ,最终将这 T 个弱学习器通过集合策略进行整合,得到最终的强学习器。
Adaboost算法类库的介绍
scikit-learn 中 Adaboost 类库有 AdaBoostClassifier 和 AdaBoostRegressor 。
从名字就可以看出 AdaBoostClassifier 用于分类,AdaBoostRegressor 用于回归。
下面是 AdaBoostClassifier 和 AdaBoostRegressor 框架参数:
1.base_estimator:弱分类学习器或者弱回归学习器。理论上可以选择任何一个分类或者回归学习器,不过需要支持样本权重。AdaBoostClassifier 默认使用 CART 分类树 DecisionTreeClassifier ,而 AdaBoostRegressor 默认使用 CART 回归树 DecisionTreeRegressor ,一般使用默认值即可。
2.n_estimators: 弱学习器的最大迭代次数,可以认为是最大的弱学习器的个数。n_estimators 太小,容易欠拟合,n_estimators 太大,容易过拟合,默认是 50 。在实际调参的过程中,一般将 n_estimators 和 learning_rate 一起考虑。
3.learning_rate: 每个弱学习器的权重缩减系数 ν ,在原理篇会讲。对于同样的训练集拟合效果,较小的 learning_rate 意味着需要更多的弱学习器的迭代次数,默认是 1 。
4.CART 决策树参数可以参考:http://sharetime.corp.qunar.com/article/34。
Adaboost算法实践示例
导入头文件
#coding=utf-8
import matplotlib.pyplot as plt
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.ensemble import AdaBoostClassifier
样本数据
# 仍然使用自带的digits 数据
digits = datasets.load_digits()
划分训练数据和测试数据
# 随机标记75%的样本作为训练样本
x_train,x_test,y_train,y_test = train_test_split(digits.data,digits.target,test_size=0.25,random_state=0)
训练模型
# 训练模型,限制树的最大深度5
clf = AdaBoostClassifier(base_estimator = DecisionTreeClassifier(max_depth=2,
min_samples_split=20, min_samples_leaf=5), learning_rate = 0.7, n_estimators = 200)
# 开始训练
clf.fit(x_train,y_train)
预测验证
# 通过测试集进行预测
y_predict = clf.predict(x_test)
计算准确率
# 显示预测准确率
diff = 0.0;
for num in range(0,len(y_predict)):
if(y_predict[num] != y_test[num]):
diff = diff + 1
rate = (diff / len(y_predict));
print 1 - rate
# 显示拟合分值
print clf.score(x_train,y_train)
# 也就是说拟合训练集数据的分数还不错。当然分数高并不一定好,因为可能过拟合。
n_estimators和score之间的关系
#绘图准备
fig = plt.figure()
#将画板切成1*1的区域,选择第1个区域
ax = fig.add_subplot(1,1,1)
#获得最大迭代次数
estimators_num = len(clf.estimators_)
#生成0~最大迭代次数的数组
X = range(1,estimators_num+1)
#绘画训练数据集生成的score的曲线
ax.plot(list(X),list(clf.staged_score(x_train,y_train)),label='Traing score')
#绘画测试数据集生成的score的曲线
ax.plot(list(X),list(clf.staged_score(x_test,y_test)),label='Testing score')
#设置横坐标轴名称
ax.set_xlabel("estimator num")
#设置纵坐标轴名称
ax.set_ylabel("score")
#设置标题
ax.set_title("AdaBoostClassifier")
#显示
plt.show()
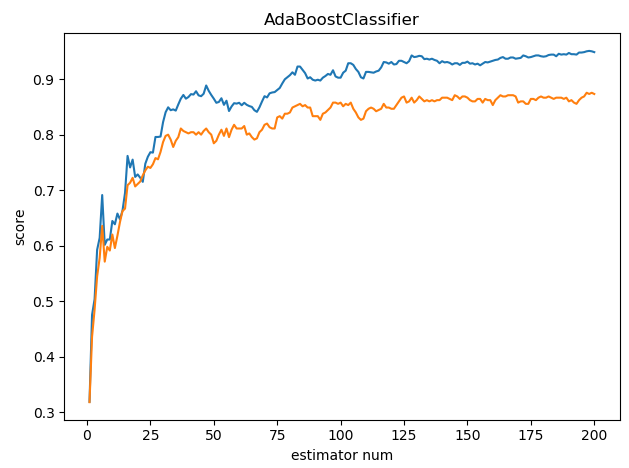
可以看到 score 会随着 estimators_num 的数量增加而增加,但是不是越高越好,有可能会过拟合。AdaBoostRegressor 与 AdaBoostClassifier 类似,就不介绍了。
Adaboost算法原理
Adaboost算法原理
AdaBoost 是 Boosting 大家族的一员,那么我们来看看 Boosting 算法系列的基本思想,如下图:

从图中可以看出,Boosting 算法的工作机制是首先从训练集用初始权重训练出一个弱学习器 1 ,根据学习误差率更新训练样本的权重,使学习误差率高的训练样本权重变高,这样这些误差率高的样本在后面的学习器中得到更多的重视。然后将调整权重后的训练集训练弱学习器 2. ,如此重复进行,直到弱学习器数达到事先指定的数目 T ,最终将这 T 个弱学习器通过集合策略进行整合,得到最终的强学习器。
Adaboost算法流程
1.首先,初始化训练数据的权值分布。 每个训练样本最开始时都被赋予相同的权值:
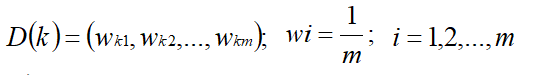
2.进行迭代 t=1,2,...,T
(1)选取一个当前误差率最低的弱分类器 H 作为第 t 个弱分类器 Ht ,并计算弱分类器 Ht ,该弱分类器在分布 Dt 上的误差为:
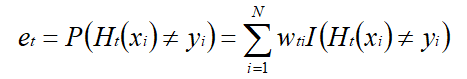
由上述式子可知,Ht(x) 在训练数据集上的误差率 et 就是被 Ht(x) 误分类样本的权值之和。
(2)计算该弱分类器在最终分类器中所占的权重(弱分类器权重用 a 表示):
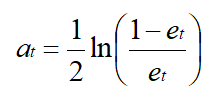
(3)更新训练样本的权值分布 Dt+1 :
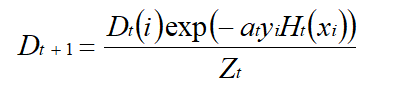
其中:
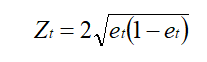
省略推倒过程:错误分类样本,权重更新:
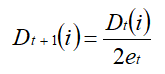
正确分类样本,权值更新:
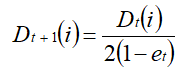
3.最后,按弱分类器权重 at 组合各个弱分类器,即:
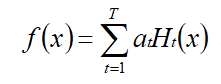
通过符号函数sign的作用,得到一个强分类器为:
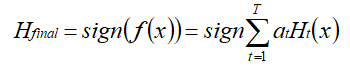
AdaBoost示例详解
Adaboost 是由 N 个弱分类器构成,为了更好的讲解 AdaBoost 算法,我们给出了一些比较简单的分类器。给定如图所示的训练样本,弱分类器采用平行于坐标轴的直线,用 Adaboost 算法的实现强分类过程。
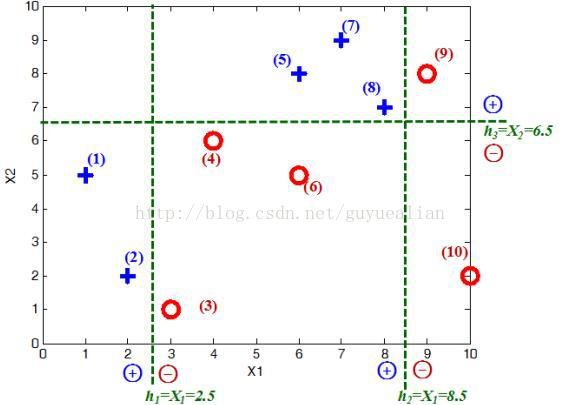
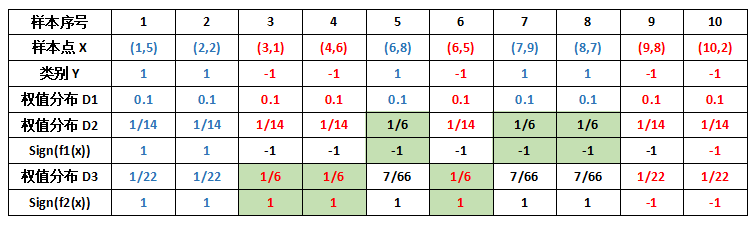
将这 10 个样本作为训练数据,根据 X1 和 X2 的对应关系,可把这 10 个数据分为两类,图中用“+”表示类别 1 ,用“O”表示类别 -1 。本例使用水平或者垂直的直线作为分类器,图中已经给出了三个弱分类器,即:
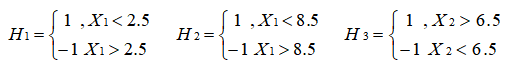
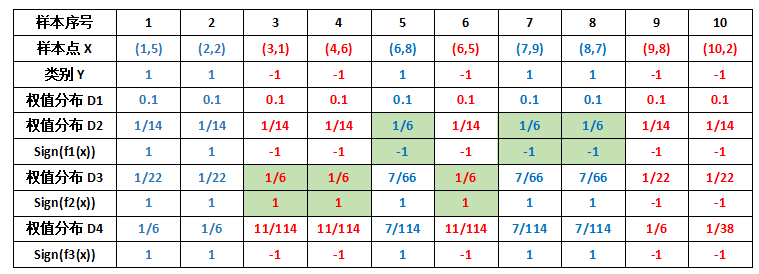
首先需要初始化训练样本数据的权值分布,每一个训练样本最开始时都被赋予相同的权值:w = 1/m ,这样训练样本集的初始权值分布 D1(i) : 令每个权值 1/m = 0.1 ,其中,m = 10,i = 1,2, ..., 10,然后分别对于 t= 1,2,3, ... 等值进行迭代( t 表示迭代次数),下表已经给出训练样本的权值分布情况:

1.第 1 次迭代
初试的权值分布 D1 为 0.1 ,取已知的三个弱分类器 H1、H2 和 H3 中误差率最小的分类器作为第 1 个弱分类器(三个弱分类器的误差率都是 0.3 ,那就取第 1 个吧)。
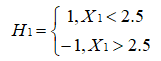
PS:某个分类器的误差率等于该分类器的被分错类样本的权重之和。
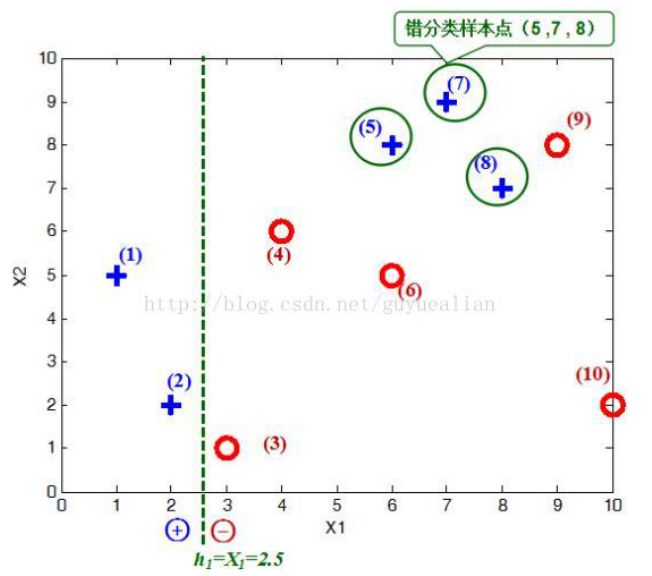
在分类器 H1(x) 中,样本点“5 7 8”被错分,因此弱分类器 H1(x) 的误差率为:
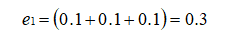
根据误差率 e1 计算 H1 的权重:
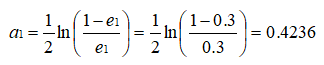
PS:这个 a1 代表 H1(x) 在最终的分类函数中所占的权重为 0.4236 。 可见,被误分类样本的权值之和影响误差率 e ,误差率 e 影响弱分类器在最终分类器中所占的权重 a 。 然后,更新训练样本的权值,用于下一轮迭代,对于正确分类的训练样本“1 2 3 4 6 9 10”(共 7 个)的权值更新为:
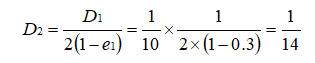
PS:正确分类的样本权值由原来的 1/10 减小到 1/14 。 对于所有错误分类的训练样本“5 7 8”的权值更新为:
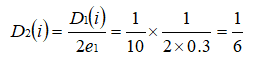
PS:错误分类的样本权值由原来的 1/10 增大到 1/6 。 这样,第 1 轮迭代后,最后得到各个样本新的权值分布:
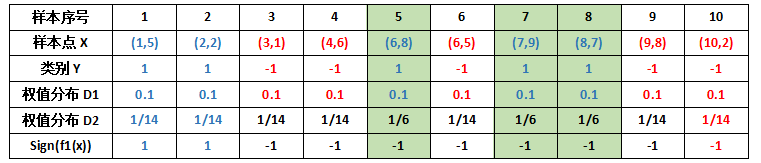
用浅绿色底纹标记的表格,是被 H1(x) 分错的样本。 可得分类函数:
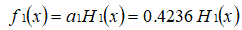
2.第 2 次迭代
在权值分布 D2 的情况下,再取三个弱分类器 H1、H2 和 H3 中误差率最小的分类器作为第 2 个弱分类器:
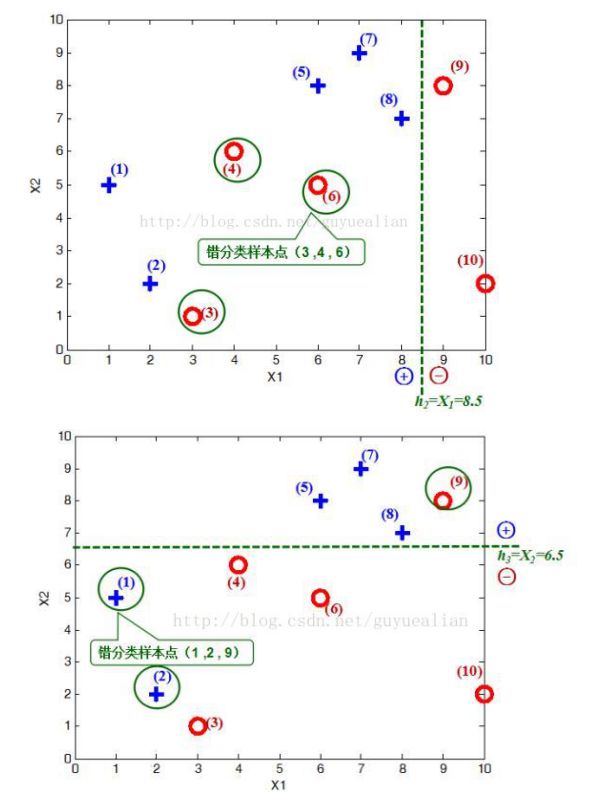
当取弱分类器 H1 时,被错分的样本为 5,7,8 。误差率 e=1/6+1/6+1/6=3/6=1/2; 当取弱分类器 H2 时,被错分的样本为 3,4,6 。误差率 e=1/14+1/14+1/14=3/14 ;当取弱分类器 H3 时,被错分的样本为 1,2,9 。误差率 e=1/14+1/14+1/14=3/14 。因此,取当前最小的分类器 H2 或 H3 ,我们将 H2 作为第 2 个弱分类器。
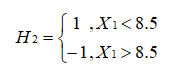
根据 D2 可知样本 3 的权重是 1/14 ,样本 4 的权重是 1/14 , 样本 6 的权重是 1/14 ,所以 H2 在训练数据集上的误差率:
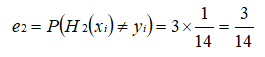
根据误差率 e2 计算 H2 的权重:
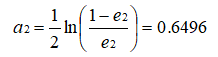
更新训练样本的权重分布,对于正确分类的样本权值更新为:

对于错误分类的权重更新为:
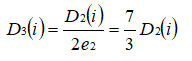
这样,第 2 轮迭代后,最后得到各个样本数据新的权值分布:
用浅绿色底纹标记的表格,是被 H2(x) 分错的样本。 可得分类函数:
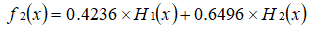
3.第 3 次迭代
在权值分布 D3 的情况下,再取三个弱分类器 H1、H2 和 H3 中误差率最小的分类器作为第 3 个弱分类器。
当取弱分类器 H1 时,被错分的样本点为 5,7,8 ,误差率 e=7/66+7/66+7/66=7/22
当取弱分类器 H2 时,被错分的样本点为 3,4,6,误差率 e=1/6+1/6+1/6=1/2=0.5
当取弱分类器 H3 时,被错分的样本点为 1,2,9,误差率 e=1/22+1/22+1/22=3/22
因此,取当前最小的分类器 H3 作为第 3 个弱分类器。
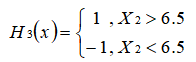
根据 D3 可知样本 1 的权重是 1/22 ,样本 2 的权重是 1/22 , 样本 9 的权重是 1/22 ,所以 H3 在训练数据集上的误差率:
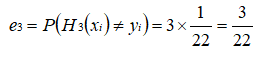
根据误差率 e3 计算 H3 的权重:
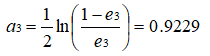
更新训练样本数据的权值分布,对于正确分类的样本权值更新为:
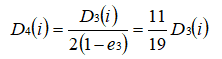
对于错误分类的权值更新为:
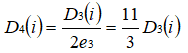
这样,第 3 轮迭代后,得到各个样本数据新的权值分布为:
可得分类函数:
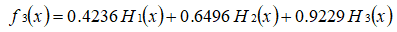
至此,整个训练过程结束。整合所有分类器,可得最终的强分类器为:
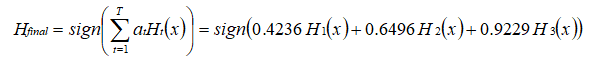
总结
优点
1.Adaboost 作为分类器时,分类精度很高。
2.在 Adaboost 的框架下,可以使用各种回归分类模型来构建弱学习器,非常灵活。
3.作为简单的二元分类器时,构造简单,结果可理解。
4.不容易发生过拟合。
缺点
Adaboost 算法易受噪声干扰。









