深度学习构建块:映射,非线性和目标
深度学习包括以巧妙的方式组合具有非线性的线性。非线性的引入允许强大的模型。在本节中,我们将使用这些核心组件,组成一个目标函数,并查看模型是如何训练的。
映射
深度学习的一个工作核心就是映射,他是函数f(x),定义为:f(x) = Ax + b ,对于一个矩阵A和向量x及b。这里要学习的参数是 A 和 b。通常 b 被称为偏差项。
人话:就是高中数学里面的函数映射,y = ax+b,
这里就是学习参数a和b。
PyTorch和大多数其他深度学习框架的工作方式与传统的线性代数有一点区别。它映射输入的行而不是列。也就是说,下面输出的第i行是A下输入的第i行的映射,加上偏差项。请看下面的例子。
人话:这里就是线性代数里面的的外积或叉乘。
import torchimport torch.nn as nnimport torch.nn.functional as Fimport torch.optim as optim
torch.manual_seed(1)
lin = nn.Linear(5,3) ''' 例子: 0.21 0.21 0.81 0.42 0.11 0.51lin= 0.33 0.28 0.14 0.74 0.41 0.28 0.55 0.9 0.85'''#数据是2×5.data = torch.randn(2,5)
'''例子: 0.21 0.61 0.91 0.75 0.23data = 0.31 0.81 0.41 0.65 0.42'''
data = lin(data)'''data
'''
print(data)print(data.grad_fn)
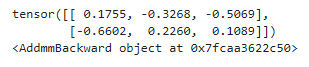
非线性函数
首先,注意接下来的事实,这将解释为什么我们首先需要非线性。假如,我们有两个映射f(x) = Ax+b 和 g(x)=Cx+d。f( g(x))是什么呢?
f( g(x)) =A(C x+d)+b =ACx+(Ad+b)
AC是一个矩阵,Ad+b是一个向量,所以,我们看到构成映射的又给了一个映射。
从这,你可以看出,如果你想神经网络组成一个长的映射链,这样增对你的模型没有任何作用,只是做单个映射。
如果我们在映射层之间引入非线性函数,将不会是这样,我们可以构建更加强大的模型。
这是少数几个核心的非线性函数。tanh(x),σ(x),ReLU(x) 非常常用。你可能会想:“为什么是这些函数?我可以想到一堆其他的非线性函数。”主要原因是他们有梯度同时容易计算,计算梯度是学习的本质。例如:
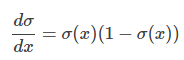
(sigmoid函数的导数)。
快速说明:虽然您可能已经在AI的介绍课程中学习了一些神经网络,其中σ(x)是默认的非线性,但在实践中人们通常会回避它。这是因为随着参数的绝对值增加,梯度消失得非常快。小渐变意味着很难学习。大多数人默认为tanh或ReLU。
data = torch.randn(2,2)print(data)print(F.relu(data))
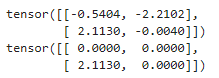
Softmax和概率(probabilities)
Softmax(x) 函数也是一个非线性的,但是它特殊在于它通常是网络的最后操作。这是因为它接收实数向量并返回概率分布。它的定义如下。x__ 是实数向量(没有约束正数还是负数)。那么Softmax(x)__ 的第i个分量是
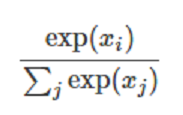
这非常清楚输出是概率分布:每个元素都是非负的,并且所有分量的总和是1。
您还可以将其视为仅将元素指数运算符应用于输入,以使所有内容都为非负值,然后除以标准化常量。
data = torch.randn(5)
print(data)print(F.softmax(data,dim=0))print(F.softmax(data,dim=0).sum())print(F.log_softmax(data,dim=0))
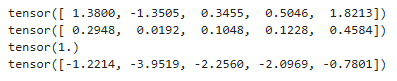
目标函数
目标函数是您的网络正在被训练以最小化的功能(在这种情况下,它通常被称为损失函数或成本函数)。首先选择一个训练实例,通过神经网络运行它,然后计算输出的丢失。然后通过获取损失函数的导数来更新模型的参数。直观地说,如果你的模型对答案完全有信心,答案是错误的,你的损失就会很高。如果它对答案非常有信心,答案是正确的,那么损失就会很低。
最小化训练示例中的损失函数背后的想法是,您的网络将有希望地进行一般化,并且在您的开发集,测试集或生产中看不见的示例有很小的损失。一个示例损失函数是负对数似然丢失,这是多类分类的一个非常常见的目标。对于有监督的多类分类,这意味着训练网络以最小化正确输出的负对数概率(或等效地,最大化正确输出的对数概率)。
优化和训练
那么我们可以为实例计算损失函数呢?我们该怎么做?我们之前看到,Tensors知道如何根据用于计算它的东西来计算渐变。好吧,因为我们的损失是Tensor,我们可以根据用于计算它的所有参数计算梯度!然后我们可以执行标准渐变更新。设 θ__为我们的参数, __L(θ)为损失函数, η 为正学习率。那么:
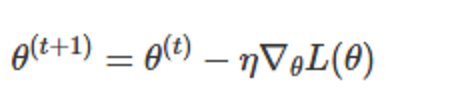
有许多算法和积极的研究,试图做更多的东西,而不仅仅是这个香草梯度更新。许多人试图根据训练时间发生的事情来改变学习率。除非您真的感兴趣,否则您无需担心这些算法的具体用途。Torch在torch.optim包中提供了许多,它们都是完全透明的。很多复杂的算法就如同使用最简单的梯度更新。尝试不同的更新算法和更新算法的不同参数(如不同的初始学习率)对于优化网络性能非常重要。通常,只需用Adam或RMSProp等优化器替换SGD就可以显着提升性能。
用PyTorch创建网络
在我们把注意力放在NLP之前,让我们使用仿射映射和非线性来做一个在PyTorch中构建网络的注释示例。我们还将看到如何使用PyTorch内置的负对数似然来计算损失函数,并通过反向传播更新参数。
所有网络组件都应该从nn.Module继承并覆盖forward()方法。就样板而言,就此而言。从nn.Module继承可为组件提供功能。例如,它使其跟踪其可训练参数,您可以使用 .to(device) 方法在CPU和GPU之间交换它,其中设备可以是CPU设备 torch.device("cpu")或CUDA设备torch.device("cuda:0")。
让我们编写一个带注释的网络示例,该网络采用稀疏的词袋表示,并在两个标签上输出概率分布:“英语”和“西班牙语”。这个模型只是逻辑回归。
例子:逻辑回归Bag-of-Words分类器
我们的模型将映射稀疏的BoW表示以记录标签上的概率。我们为词汇中的每个单词指定一个索引。例如,假设我们的整个词汇是两个单词“hello”和“world”,分别为0和1。句子“hello hello hello hello”的BoW向量是
[4,0]
如"hello world world hello",就是
[2,2]
通常,他是
[Count(hello),Count(world)]
将此BOW向量表示为X。我们网络的输出是:
logSoftmax(AX + b)
也就是说,我们参入的输入值经过映射然后做log softmax。
data = [('me gusta comer en la cafeteria'.split(),'SPANISH'), ('Give it to me'.split(),'ENGLISH'), ("No creo que sea una buena idea".split(), "SPANISH"), ("No it is not a good idea to get lost at sea".split(), "ENGLISH") ]
test_data = [("it is lost on me".split(), "ENGLISH"), ("Yo creo que si".split(), "SPANISH"), ("this is english".split(), "ENGLISH") ]
#word_to_ix将词汇中的每个单词映射到一个唯一的整数,#这将是它的单词向量包的索引
word_to_ix={}
for sent , _ in data + test_data: for word in sent: if word in sent: if word not in word_to_ix: word_to_ix[word] = len(word_to_ix)
print(word_to_ix)
VOCAB_SIZE = len(word_to_ix)NUM_LABELS = 2
class BoWClassifier(nn.Module): def __init__(self,num_labels,vocab_size): super(BoWClassifier,self).__init__() self.linear = nn.Linear(vocab_size,num_labels) def forward(self,bow_vec): return F.log_softmax(self.linear(bow_vec),dim=1)
def make_bow_vector(sentence,word_to_ix): vec = torch.zeros(len(word_to_ix)) for word in sentence: vec[word_to_ix[word]] += 1 return vec.view(1,-1) def make_target(label, label_to_ix): return torch.LongTensor([label_to_ix[label]])
#初始化模型model = BoWClassifier(NUM_LABELS, VOCAB_SIZE)
for param in model.parameters(): print(param)
with torch.no_grad(): sample = data[0] print(sample) bow_vector = make_bow_vector(sample[0], word_to_ix) log_probs = model(bow_vector) print(log_probs) kind = torch.max(log_probs,1) print(kind[1].item())

以上哪个值对应于ENGLISH的对数概率,哪个对应SPANISH?我们从来没有定义它,但是如果我们想训练这个东西我们需要。
label_to_ix = {"SPANISH": 0, "ENGLISH": 1}
所以让我们训练!为此,我们传递实例以获取log概率,计算损失函数,计算损失函数的梯度,然后使用渐变步骤更新参数。损耗函数由Torch在nn包中提供。nn.NLLLoss()是我们想要的负对数似然丢失。它还定义了torch.optim中的优化函数。在这里,我们将使用SGD。
请注意,NLLLoss的输入是日志概率向量和目标标签。它不计算我们的日志概率。这就是我们网络的最后一层是log softmax的原因。损失函数nn.CrossEntropyLoss()与NLLLoss()相同,除了它为您执行log softmax。
with torch.no_grad(): for instance, label in test_data: bow_vec = make_bow_vector(instance, word_to_ix) log_probs = model(bow_vec) print(log_probs)
print(next(model.parameters())[:, word_to_ix["creo"]])
loss_function = nn.NLLLoss()
optimizer = optim.SGD(model.parameters(), lr=0.1)
for epoch in range(100): for instance ,label in data: model.zero_grad() bow_vec = make_bow_vector(instance,word_to_ix) target = make_target(label,label_to_ix) log_probs = model(bow_vec) loss = loss_function(log_probs,target) loss.backward() optimizer.step()
with torch.no_grad(): for instance, label in test_data: bow_vec = make_bow_vector(instance, word_to_ix) log_probs = model(bow_vec)
result = torch.max(log_probs,1) print(result[1].item())
print(next(model.parameters())[:, word_to_ix["creo"]])

我们得到了正确的答案!您可以看到,在第一个示例中,西班牙语的对数概率要高得多,而对于测试数据,第二个例子中英语的对数概率要高得多,应该如此。
现在,您将了解如何创建PyTorch组件,通过它传递一些数据并执行渐变更新。我们已经准备好深入挖掘NLP的深层内容。
总结
本节,作者主要介绍了一下几点内容:
PyTorch中线性和非线性函数的特点和功能。
着重介绍了Softmax函数,Softmax函数输出的是概率分布。
简单介绍了目标函数(一般称为损失函数),通过优化器不断优化参数,以达到逼近目标的目的。
介绍了优化器和训练。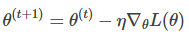 ,通过不断更新参数,降低损失。
,通过不断更新参数,降低损失。
构建一个词袋的分类器。首先构建一个分类模型,模型需要继承nn.Module,并重写 forward()函数;其次定义损失函数和优化器;然后训练。第一步,模型梯度清零;第二步:制作我们的BOW向量,第三步:训练模型;第四步:计算损失、梯度并使用optimizer.step()函数更新参数。
如果你也有想分享的干货,可以登录天池实验室(notebook),包括赛题的理解、数据分析及可视化、算法模型的分析以及一些核心的思路等内容。
小天会根据你分享内容的数量以及程度,给予丰富的神秘天池大礼以及粮票奖励。分享成功后你也可以通过下方钉钉群👇主动联系我们的社区运营同学(钉钉号:yiwen1991)
天池宝贝们有任何问题,可在戳“留言”评论或加入钉钉群留言,小天会认真倾听每一个你的建议!

点击下方图片即可阅读

如何使用sklearn优雅地进行数据挖掘?

为何推荐sklearn做单机特征工程?【下】

学会【超参数与模型验证】,大不了我请你吃辣条~

迁移学习教程(Transfer Learning tutorial)









