机器学习和互联网意味着海量数据和复杂的联系,同时也意味着人类无法理解的运行过程——人工智能的“黑箱”是近期学界热议的一个话题,当我们无法理解算法和它生产出的内容,它会怎样改变人类的思想和整个世界的运行?与此同时,完全无法理解这些数据意味着什么的人工智能,真的是在分析世界吗?技术发展伴随而来的是人类对自身的怀疑,也许在未来,关于世界的知识和对世界的理解之间的鸿沟会日渐加深。
原文标题为Machine Learning Widens the Gap Between Knowledge and Understanding,摘自David Weinberger的新书《日常混乱:技术、复杂性以及我们如何在一个充满可能性的新世界中发展》(EVERYDAY CHAOS: Technology, Complexity, and How We’re Thriving in a New World of Possibility)。
图片来源:peepo/Getty Images
Deep Patient的程序不知道被敲头会让人类感到头晕,也不知道糖尿病人不应该一次吃5磅的三角巧克力,它甚至不知道肱骨和腕骨相连。它只知道研究人员在2015年给它提供的东西:70万名患者的医疗记录。这是一堆完全没有可理解框架的混乱数据。
然而,在分析了这些数据之间的关系之后,Deep Patient不仅能够诊断出个别患者罹患特定疾病的可能性(在某些情况下,它甚至比人类医生更准确),包括一些迄今为止完全无法预测的疾病。
如果你问你的医生,为什么Deep Patient认为现在就开始服用他汀类药物或做个预防性手术可能比较明智,你的医生可能没法告诉你原因,但这不是因为他/她不够聪明,也不是因为他/她医术不高。Deep Patient是一种深度学习的人工智能(它本身就是机器学习的一种),尽管它不知道这些数据代表什么,但它可以发现数据之间的关系。
基于此,它组装了一个信息点网络——每个信息点都有权重,能够决定它所连接的点有多大可能会“触发”(该触发会影响它们所连接的点,就像触发大脑中的神经元一样)。举个例子,Deep Patient认为,某个病人有72%的几率患上精神分裂症,想要理解它为什么会作出这样的诊断,医生就必须进入这数百万个信息点以及它们之间的联系和权重网络之中——这实在是太多了,他们之间的关系也太复杂了。
当然,作为一名患者,你可以选择拒绝接受Deep Patient的概率性结论,但这样做是有风险的。现实情况是,在某些情况下,Deep Patient比人类医生的预测准确得多,但是它完全无法解释它的预测,这是一种人工智能“黑箱”。
这也是未来,远超医学这一个领域。
你手机的导航系统、输入预测、语言翻译、音乐推荐等等功能都依赖于机器学习。
随着人工智能变得越来越先进,它会越来越神秘。谷歌的AlphaGo对围棋一无所知,“只是”从13万场有记录棋局中分析出6000万步棋,但它依然击败了全世界排名最高的人类棋手。如果你研究AlphaGo的原理,想弄明白它为什么会下这一步棋而不是那一步棋,你可能只会看到数据之间一组复杂得难以形容的加权关系。AlphaGo可能无法用人类能够理解的方式告诉你,为什么它会下这样一步棋。
然而,AlphaGo的一步棋让一些评论者哑口无言,围棋大师樊麾说:“这不是人类的一步棋。我从来没见过人类这么走。”然后他轻轻地感叹:“太美了,太美了。”
深度学习的算法之所以有效,是因为它们比任何人类都能更好地捕捉到宇宙的复杂性、流动性,甚至是宇宙之美——每件事都在影响着其他事物,世界是普遍联系的。
诸如机器学习这样的工具和策略正越来越多地让我们直面我们日常生活中难以理解的错综复杂。但这种好处是有代价的:我们需要放弃我们对于理解世界和世界上发生的事情的坚持。
我们人类长期以来都有这样的印象:如果我们能够理解事物发生背后那不可改变的规律,我们就能够完美地预测、计划和管理未来。例如,如果我们知道天气变化的原理,天气预报就能告诉我们上班时是否要带把伞;如果我们知道是什么让人们在Facebook信息流中点击这个帖子而不是另一个帖子,我们就能策划出完美的广告方案;如果我们知道流行病背后的发生机制,我们就能阻止它的传播……通过发现支配我们世界的规律和模式,我们了解了事情是如何发生的,我们对理解世界感到义不容辞。
考虑到我们的知识总是不完善的,这个假设建立在一个更深奥的假设之上:可知论。似乎我们与宇宙之间有一个不成文的约定,那就是如果我们足够努力、足够清晰地思考,宇宙就会交出它的秘密,因为宇宙是可知的,至少在某种程度上是顺从我们意志的。
但是现在,我们的新工具(特别是机器学习和互联网)让我们认识到我们周围数据和信息的广泛性,我们开始接受世界的复杂性远远超过我们以往用来解释它的法则和模型。我们创造的这些新的、容量大的机器比我们更接近于“理解世界”的层次。
而它们,作为机器,什么都不理解。

David Weinberger的《日常混乱:技术、复杂性以及我们如何在一个充满可能性的新世界中发展》(EVERYDAY CHAOS: Technology, Complexity, and How We’re Thriving in a New World of Possibility)封面
这反过来又挑战了我们在更深层次上持有的另一种假设:宇宙可知,是因为(我们假设)我们人类足够独特,能够理解宇宙的运行。至少从古希伯来人开始,我们就认为自己是上帝创造的独一无二的生物,有能力接受上帝对真理的启示。自古希腊以来,我们就把自己定义为理性的生物,能够看到世界表面混乱之下的逻辑和秩序。我们最基本的战略依赖于我们和世界之间的这种特殊关系。
放弃人类这个物种的传统自我认知是无比痛苦的。感觉被信息过载压碎,紧张地等待接下来的发生在商业、政府、文化中的混乱……这些情绪只是深层问题的局部痛感:我们并不像我们认为的那样能很好地适应我们的宇宙。我们的大脑无法像人工智能那样准确、快速地分析或预测事件。进化给了我们适应生存的思维,但这种思维只是顺便发现了真相。我们的物种与众不同,我们有情感、直觉、创造力,这种主张开始变得过于一厢情愿,甚至有点绝望。
这种幻灭是我们应该接受的——不仅仅是因为不管我们接受与否,它都在发生。我们理解和管理未来的能力正开始经历伟大飞跃:我们开始制定相关策略,开始考虑世界的复杂性,而不是总要把世界缩小到一个我们可以预测、控制、感到舒适的大小。
我们正在经历这一飞跃,因为它已经使我们能够更高效、更有成效地与更多人、更多想法接触,更有创意,更快乐。它已经使我们在商业和个人生活中的许多最基本的想法和最习惯的做法重新语境化。它正在我们文化的每一个角落产生回响。
这些迹象在我们周围随处可见,但在许多情况下,它们隐藏在看似正常且显而易见的实践和想法中。例如,在机器学习出现之前,互联网已经让我们习惯了这些变化。
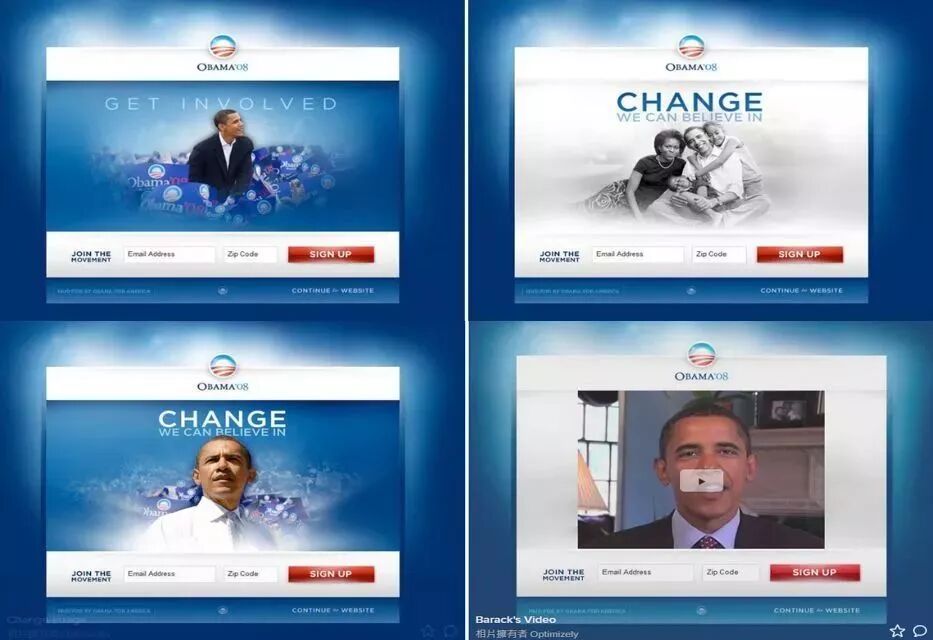
当巴拉克·奥巴马(Barack Obama)第一次参加总统竞选时,他在自己的网站上试用了两个版本的注册按钮,结果发现,与“现在加入我们(Join Us Now)”或“现在注册(Sign Up Now)”此类按钮名称相比,标有“了解更多(Learn more)”的按钮吸引了更多的点击。
另一项测试显示,奥巴马一家的一张黑白照片获得的点击量,出人意料地远超此前使用的彩色照片。
然后,他们在同一页面放入“了解更多”按钮和黑白照片,结果是:注册人数增加了40%。
图片来源:网络
总的来说,在竞选中,1300万邮件列表名单中将近三分之一的名单、大约7500万美元的捐款都是由于这样的A/B测试提高了网站的表现。A/B测试即网站把一个广告或内容的不同版本分发给一定量的几组随机用户,然后用测试结果来决定用户最终将会看到哪个版本的内容。
更令人惊讶的是,奥巴马团队发现,与纯文本信息相比,奥巴马在集会上煽动群众的视频点击率要低得多。考虑到奥巴马作为演说家的才能着实不一般,这种差异该怎么解释啊?团队并不知道,他们也并不需要知道。数据告诉他们应该在竞选网站上发布哪些内容,即使没有告诉他们原因,他们也照做不误。结果很好:更多的点击、更多的捐款、可能更多的选票。
A/B测试已经成为一种常见的实践:谷歌的搜索结果是A/B测试的结果;Netflix上电影的布局来自A/B测试;甚至《纽约时报》使用的一些标题也是A/B测试的结果……2014年至2016年,必应的软件工程师进行了2.12万次A/B测试,其中三分之一的测试给服务带来变化。
A/B测试有效果,甚至不需要懂它为什么有效。为什么在亚马逊上,如果笑容灿烂的女性图片在网页左边的话,该广告会提高销量呢?我们可以制造一个理论,但我们仍然建议针对下一个广告的位置进行A/B测试。奥巴马的黑白照片吸引了更多点击,并不意味着他的对手约翰·麦凯恩(John McCain)也应该弃用他的彩色照片。亚马逊为户外烧烤架进行推广活动时,使用蓝色背景而不是绿色背景,这让我们没有理由认为它有可能会适用于室内烧烤。
事实上,影响人们偏好的因素完全有可能是微观的、短暂的。也许50岁以上的男性更喜欢模特在左边的广告,但前提是广告的标题很有趣,而来自底特律的女性在两天阴沉沉的天气之后终于呼吸到灿烂的阳光,她们这会儿更喜欢模特在右边的广告。也许有些人刚看完对比度强烈的视频,他们现在更喜欢黑白照片,而其他人则可能因为洋基队刚输掉一场比赛而更喜欢彩色的版本。也许会出现一些能够归纳的理论,也许不能,我们不知道。原因可能和世界本身一样千差万别。
我们从小就相信,世界的真相和现实是由一些不可改变的规律来表达的。学习规律,你就能做出预测。发现新的规律,你就能预测更多的事情。如果有人想知道你是如何做出预测的,你可以向他们展示你所掌握的规律和数据。但是在A/B测试中,我们通常没有心理框架来解释为什么一个版本的广告比另一个版本更好。
想想扔沙滩球。你认为球将向你扔的方向呈抛物线运动,因为我们的心理模型——我们思考事物相互作用的一套规则——考虑了重力和动能。如果球向另一个方向运动了,你也不会认为模型错了,相反,你会认为你没有考虑到一些因素:也许你手滑了一下。
这正是我们在A/B测试中不需要做的事情。我们不需要知道为什么一张黑白照片和一个“了解更多”按钮会增加竞选捐款。如果我们发现民主党人的竞选广告经验对他/她的共和党对手不起作用——他们很可能确实不会起作用——那也没关系,因为再做一次A/B测试就好,A/B很便宜。
A/B测试只是一个例子,它在不知不觉中向我们表明:原理、规律和归纳并不像我们想象的那么重要。也许,只是也许,当我们无法处理现实的细枝末节时,我们才会用到原理。
我们刚刚看了两个基于计算机的技术案例,它们完全不同:一个是编程技术(机器学习),另一个是全球性的空间(互联网),我们在互联网遇到更多的人,欣赏他们对意义和创造力的表达。当然,这些技术通常是相互交织的:机器学习需要使用互联网大规模收集信息,越来越多基于互联网的服务同时使用、喂养机器学习。
这两种技术至少有三个共同点:巨大性、联系性、复杂性,这三个共同点一直在教导我们世界是如何运行的。
巨大性——即它们的规模——与我们参观世界上最大的麻绳球故乡或想象把世界上所有的土豆都堆在一起时完全不同。巨大性的重要性在于机器学习和互联网能达到的细节水平。这两种技术都依赖于细节和独特性,而不是通过归纳或压制“边缘”信息和思想来摆脱细节。
联系性意味着,这两种技术所包含的各个部分可以相互影响,而无需顾虑物理距离造成的障碍。联系性对这两种技术至关重要:只能连接两个部分、一次只能连接一对的网络可不能叫做互联网,只能叫做旧的电话系统。我们新技术的联系性是规模巨大的、多途径的、无距离的,也是必不可少的。
机器学习和互联网的巨大性和联系性导致了它们的复杂性。规模巨大的碎片之间的联系有时会导致一连串的事件,而这些事件的结局可能与它们开始的地方相去甚远。微小的差异可能导致这些系统出现意想不到的巨大转折。
我们不是因为这些技术的巨大性、联系性、复杂性而使用这些技术,我们使用它们是因为它们有效。我们利用这些技术的成功——而不是技术本身——向我们展示了世界比我们想象的更加复杂和混乱,这反过来鼓励我们探索新的方法和策略,挑战我们对理解和解释的本质和重要性的假设,并最终引导我们对世界有一个新的认识。
译者:喜汤











