
我最近在2019年欧洲Django大会(https://2019.djangocon.eu/ )上发表了一场关于Django ORM的演讲。在这次演讲中,我展示了使用Django ORM进行复杂查询时可以使用的各种技术。这篇文章将部分总结这次演讲,但我也会扩展和添加我无法在30分钟内完成的额外的内容。

首先,ORM代表对象关系映射,是一个帮助你处理数据库的工具。Django ORM提供了一个Python接口,用于处理数据库中的数据。它对你有两大好处: 它通过使用模型定义和迁移来帮助你设置和维护数据库结构,并通过管理器和查询集帮助你编写针对数据库的查询。
Django ORM没有开放一个接口来让你编写自定义SQL。该接口只关注你定义的模型。这使得使用ORM非常容易,但也使得使用ORM编写某些查询更困难——甚至不可能。
示例模型
在本文中,我将在大多数例子中使用下面定义的模型:

自定义管理器和查询集
我们在Kolonial.no上大量使用的东西是为我们的模型定制的Manager(管理器)和QuerySet(查询集)。在这里,你可以保持与你的模型相关的可重用逻辑。例如,我们可以在订单QuerySet中添加一个方法,该方法给出一个未发货订单的列表:

类似地,我们可以创建一个自定义管理器,例如使用一个帮助器方法来简化新订单的创建:

为了设置order(订单)模型的默认管理器,我们设置了objects属性:

检查QuerySet
另一个需要知道的有用技巧是如何检查一个QuerySet。假设你想知道为什么一个特定的QuerySet不能准确地返回你所期望的结果。那么,打开一个shell并实际检查数据库中正在运行的查询是非常有用的。这里我特别想强调两件事: 如何查看某个QuerySet生成的SQL查询,以及如何在数据库中运行一个EXPLAIN查询。

你还可以访问Django中的数据库连接包装器,并检查在该连接上运行的最后查询:

这将给出执行的SQL语句的列表和每个查询的运行时间。
避免额外的查询
当使用Django ORM时,很容易出现视图生成过多查询的情况。如果你有一个相关的模型,并对QuerySet中的每个实例进行访问,则默认行为是一次获取一个相关的模型。

为了避免这种情况,你可以使用select_related和prefetch_related。它们有着非常相似的名字和行为。第一个用于获取数据库中的对象,这些对象每一个都和一行相关联,并生成一个JOIN查询,其中所有相关对象都在一个SQL查询中获取。当你的数据库中每一行拥有多个相关对象时,你可以使用第二种方法。它将首先获取原始QuerySet的所有对象,而不是创建一个JOIN查询。然后,它将运行第二个查询来获取所有相关对象,然后在Python中而不是数据库中来连接它们。因此,通过在我们的Orders QuerySet中添加以下两行代码,我们最终会得到两个查询:

但是请注意,你不应该盲目地优化。有时运行两个或多个查询比运行一个大型查询更快。所以,在研究性能问题时,请记住这一点。
避免竞争条件
如果你正在处理数据库中的对象,这些对象可以通过多个请求并发地进行修改,那么你需要确保这些更改是按照正确的顺序应用的。这可能很重要,例如,如果我们在产品模型上保持库存数量,我们希望确保该数量正确地递增和递减。对此的一种解决方案是,当我们从数据库中获取对象时,对数据库中的行进行锁定。这样,我们就可以保证不允许其他请求获取和修改相同的行。

就性能而言,这是一个相当繁重的解决方案,在事务完成之前,不允许任何其他数据库连接访问这一行。在对你的数据进行建模时,请记住这一点。也许你可以通过对数据进行不同的建模来提前避免这个问题?
子查询
当你需要从另一个表(有时甚至是同一个表)获取一些数据,但在Django模型中又没有任何直接相关字段时,子查询非常有用。在这种情况下,Django目前不允许执行连接。另一个用例是当要获取或搜索的数据量太大,执行普通连接的速度太慢的时候。
我的第一个示例向你展示了如何将来自一行的单个值注释到一个QuerySet上。在这个例子中,我用客户下最后一笔订单的时间来标注每个客户对象:

这里两个有趣的部分是Subquery和OuterRef类。第一个是一个包装器,它接受一个普通的QuerySet并将其作为子查询嵌入到另一个QuerySet中。OuterRef类用于引用嵌入子查询的QuerySet中的字段。在本例中,我们使用它进行筛选,以便只获得属于当前行客户的订单。然后按日期排序,只选择日期列,然后只返回第一个结果。
除了从另一个QuerySet中选择一个特定的值,我们还可以使用Exists类检查另一个对象是否存在:

如果你对选择结果不感兴趣,而只是想过滤,那么Django目前不支持这种方法。这很不幸,因为这会导致查询速度变慢。幸运的是,目前有一个开放的推送请求(https://github.com/django/django/pull/8119 )来解决这个问题,所以在Django的未来版本中,很可能会支持这个功能。
上面的两个例子只是从数据库中的另一个对象中选择一个值,但是我们也可以使用聚合的结果运行更复杂的查询。下面是如何聚合子查询中匹配行的总和的例子:
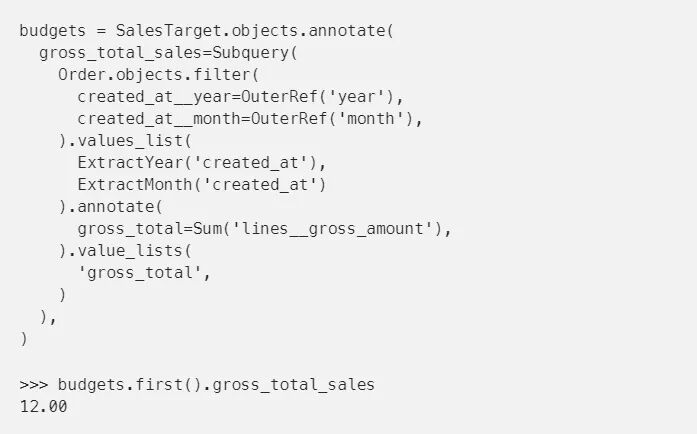
这里我们要做的第一件事是过滤出我们感兴趣的一组行。然后,我们使用values_list只选择年和月的结果。当我们在此之后使用聚合函数进行注释时,查询结果将根据所选的行进行分组,这些行对于匹配筛选器的任何行来说都是惟一的。然后,我们只选择聚合值并将其注释到外部QuerySet上。
在本例中,我们可以使用默认可用的Django基本类型生成这个查询,但是如果我们想要聚合一些行,而这些行中没有惟一的东西可以进行分组,该怎么办呢?我们不能在子查询中使用aggregate,因为它会立即运行数据库查询。相反,我们需要做的是在ORM周围使用一些技巧。假设我们有这张订单表,并想计算所有周六和周日的总销售额:

我们没有任何独特的东西可以用来分组,但是我们可以尝试删除values_list调用。不幸的是,这并没有带给我们想要的结果:

这不起作用的原因是,每当我们使用带注释的Django向QuerySet添加一个聚合时,都会添加一个group by语句,在本例Order.pk中,默认情况下,这是QuerySet模型的主键。结果是我们只得到第一个订单的和。相反,我们必须使用一个不继承自Aggregate类的数据库函数。在Django中,SUM SQL函数只能作为一个聚合子类使用,但是我们可以相对容易地通过直接使用Func类来解决这个问题:

虽然这不是特别漂亮,但它确实给出了我们想要的结果。虽然我并不总是建议使用这个方法,但是知道它是一个可用选项是很有用的。
自定义约束和索引
Django在很长一段时间内都支持唯一性约束,但是只有当你希望字段的组合在表中的所有行中都是唯一的时候才需要使用它:

我们还可以选择向表中的某些列添加额外的索引,但同样只针对整个表。从Django2.2开始,我们可以更好地控制如何创建唯一性约束和自定义索引。我们现在可以指定一个唯一性约束只检查表中所有行的一个子集:

在本例中,我们将每个用户限制为只有一个未发货订单。虽然这可能是一个相对简单的例子,但是条件唯一性约束给了我们很大的灵活性。假设我们有一个数据库表,其中我们希望只允许一行具有NULL值。因为在SQL中NULL是不等于NULL的,所以每一行都被认为是惟一的,我们不能使用一个普通的unique=True或unique_together来限制这一点。但是,我们可以添加一个约束,在字段为NULL的情况下检查它是否是唯一的。
我们还可以创建自定义检查约束。这类似于Django中的字段验证器,但是它们是由数据库执行的。这可以保护我们不受Python代码中的bug的影响,该检查甚至可以在bulk_create和类似的平台上运行,如果你从另一个非django项目访问相同的数据库时,该检查也会运行。例如,我们可以创建一个检查约束来验证给定的月份数字是否有效:

类似地,我们可以创建自定义的部分索引,它只覆盖表的一部分。如果只查询表的一个子集,或者表的很大一部分包含空NULL值时,这将非常有用。在我们的示例模型中,在准备发货时,我们很可能会频繁地访问未发货的订单。下面是如何创建只包含未发货订单的索引的示例。这将有助于加快我们最常用的数据库查询:

窗口函数
在Django2.0中,使用DjangoORM运行窗口函数进行查询得到了支持。这将在查询中生成一个OVER语句来查看行分区。这是很有用的,例如,如果我们想查找某个客户的上一个订单,查看该客户上一次下订单的时间,或者计算来自该客户的订单总和。下面是一个示例,演示如何使用来自同一客户的上一个订单的id来注释一个订单的QuerySet:

我们使用Window类来生成OVER语句,然后生成Lag来从第n行中选择一个值,在本例中是前一行,因为我们将n指定为1。
不幸的是,由于SQL标准限制,我们不能在窗口函数上进行过滤。但是,这可以通过使用通用表表达式(CTEs)来补救,但是Django目前不支持这种方法。
使用自定义数据库函数进行扩展
有时候Django ORM不允许你做你想做的事情。在许多情况下,实际上可以通过扩展内置基本类型来添加自己的功能。例如,如果你想使用Django没有公开的自定义SQL函数,这可以通过子类化Func函数来轻松添加:

这就是所需的全部。现在,我们可以像使用任何Django公开的SQL函数一样使用它。
我们也可以用更复杂的函数来扩展。假设我们用单独的日期和时间列建立了一个模型,但是需要将其与使用日期时间的另一个表进行比较。我们可以通过实现一个自定义函数来实现这一点。没有跨数据库的通用方法可以做到这一点,但是Django允许我们为想要支持的每个数据库分别实现这一点。下面是用于PostgreSQL和Sqlite的例子:
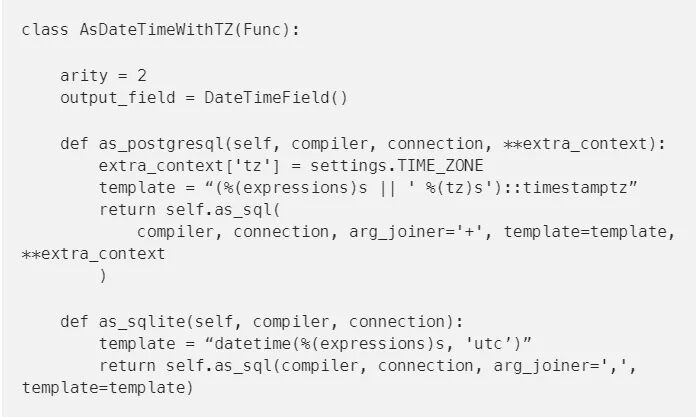
接着,我们就可以使用这个函数来在QuerySet上注释一个日期时间:

运行自定义SQL
如果我们想要做的事情使用Django提供给我们的功能不能直接实现,我们有时可以直接编写自定义SQL。Django提供了多种实现方法。例如,我们可以用一个自定义SQL表达式来对QuerySet进行注解:

我们也可以用QuerySet的extra方法来做同样的事情:

extra有很多的选项,所以请查阅文档。
如果我们想自己编写整个SQL查询,这也是一个选项。返回的列将按名称映射到模型字段。任何与现有字段名不匹配的列都将作为注解字段添加。

如果我们不想返回模型对象,我们也可以直接在数据库游标上运行自定义SQL查询:

这将返回一个包含列的元组。
自定义迁移
向Django添加额外数据库功能的另一种方法是编写自定义迁移。在Django获得对自定义约束和索引的支持之前,在自定义迁移中使用RunSQL是向数据库添加这类选项的一种方法。另一种可能性是使用RunSQL向数据库添加自定义视图,并将其作为一个模型公开:
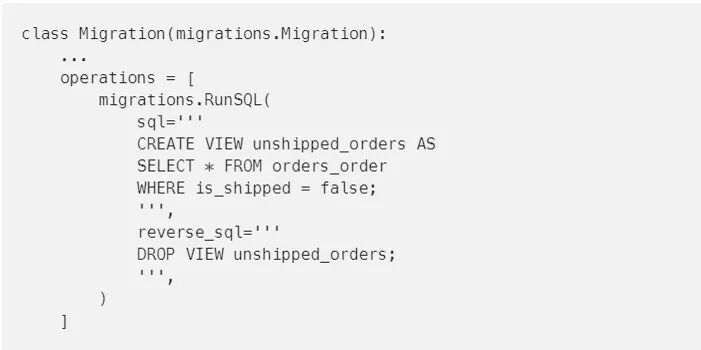
自定义迁移的另一个用例是数据迁移。如果你的数据库中有一组始终可用的初始数据,那你可以使用数据迁移将其添加到自定义迁移中。如果你在运行测试时使用迁移,那么相同的初始数据集也将在测试中可用。要做到这一点,你可以在你的迁移文件中使用RunPython类:

我将向你展示的与迁移相关的最后一个基本类型是SeparateDatabaseAndState类。Django在运行迁移时,除了数据库中的实际状态外,还保留一个内部状态来表示模型的预期布局等。使用这个类,你可以分别修改这两个状态。如果你需要将这两者分开,例如出于高可用性的原因,这个类将非常有用。这就需要用到列表,一个在内部状态下执行操作,一个在数据库中执行操作:

总结
我希望本文为你提供了一些关于在使用Django ORM时如何优化或改进数据库查询的想法。
这绝不是一个完整的列表,所以请查看Django文档(https://docs.djangoproject.com/ )获取详细内容。我建议从QuerySet API reference(https://docs.djangoproject.com/en/2.2/ref/models/querysets/ 0部分开始,然后从那里跟随链接去查看可用的API。
英文原文:https://qiniumedia.freelycode.com/vcdn/1/%E4%BC%98%E8%B4%A8%E6%96%87%E7%AB%A0%E9%95%BF%E5%9B%BE3/pushing-django-orm-to-its-limit.pdf
译者:忧郁的红秋裤






