大家好,从5月份开始,狗熊会将上新一门课程:深度学习入门。这门课程由熊大亲自制作,共包含11讲,主要介绍了深度卷积网络及其在图像分类中的重要应用。作为助教团队的一员,水妈每周会整理一讲内容,在推文跟大家分享。视频课程请同学们移步阅读原文,登录狗熊会的个人会员进行学习。
大家好,我是熊大,这是咱们深度学习这门课的第一讲。在这一讲,我想和大家探讨一下深度学习与回归分析之间的关系。
深度学习作为人工智能领域备受关注的模型方法,在媒体上可以看到大量的宣传材料。客观地说,很多宣传其实是有失偏颇的,甚至是误导的,把深度学习和人工智能给过度神化了。而回归分析不一样,它是当前很多高校学生的必修课。它听起来不是那么的高大上,但好处是人们对它非常熟悉。而通过这一讲的学习,我想告诉大家的是,这两种方法其实渊源很深,因为深度学习其实就是一种特殊的非线性回归分析方法。
想要深刻的理解和学习深度学习,就必须深刻的理解和学习回归分析。对回归分析的理解有三个不同的层面:第一、模型的层面;第二、业务的层面;第三产品的层面。在绝大多数课堂上,同学们学习的主要都是模型的层面,而我想通过一个实际的例子来给同学们讲解一下这三个层面有什么异同、有什么相互支撑的关系。
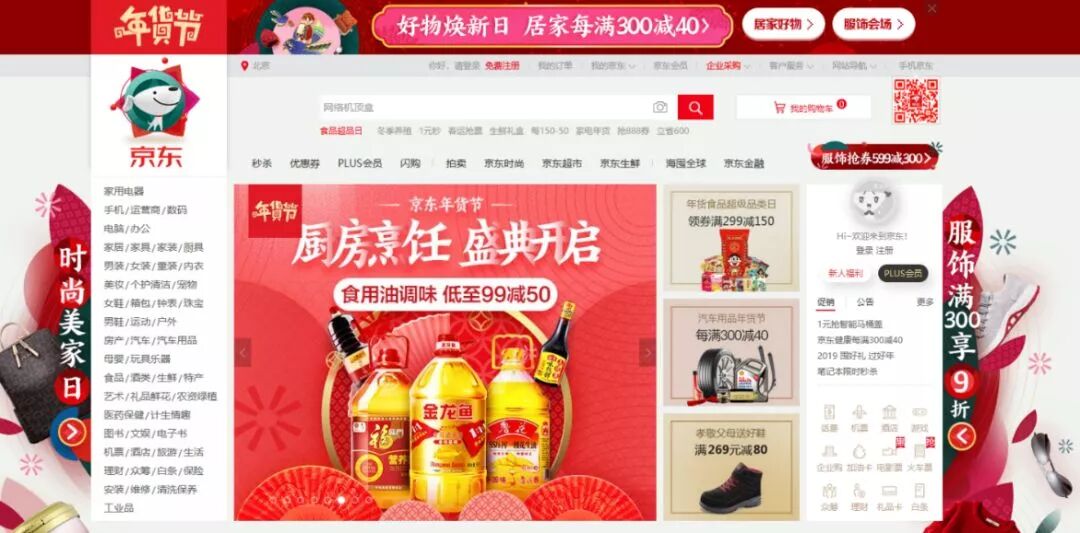
这是一张京东首页的截屏,在正中间有金龙鱼的地方,是一个广告位。京东负责广告位的同事,有一个业务问题,就是在既定的时间、既定的地点、既定的展示机会,应该展示怎样的广告,才能达到最好的业务效果。这就是回归分析在业务层面的一个表达。显然这个业务问题太模糊了,无法对它进行数据化分析。应该有一种数据思维的方式,把这个业务问题转化为一个数据可分析问题。
首先应该有一个清晰的指标Y,也就是因变量,它应该能反映我们对业务的核心诉求。在这个场景下,核心诉求就是广告效果好。请问什么样的效果才叫好?是点击,还是加入购物车,又或是购买,甚至是重复购买。根据不同的业务场景,不同的实际需求,这些定义可能是不一样的,但它们都是良好的定义。我们假设这个场景中追求的好就是有点击,广告是按点击收费的。那么这里的Y就是点击与否。
接下来要研究的是对于什么样的产品,在什么样的时间,什么样的地点,给什么样的消费者推送,才会产生点击行为,或者说点击的可能性有多大。之前已经定义了Y,接下来需要定义一系列的X,来描述什么是产品,什么是时间,什么是地点,什么是消费者。例如对于产品而言,X可能就是它属于哪一大类,它是食品吗,它是电脑吗,它是家具吗?这种指标在行业中也被叫作标签。我们还需要标签来定义时间、地点、消费者,他是男生还是女生,他的年龄,收入状况,以前的购买行为等等。
大家看,这就是回归分析的模型层面。我们通过对业务的理解,把一个业务问题具象成为一个数据可分析问题。什么是数据可分析问题?它有清晰的Y,有清晰的X,科学家可以通过现有的各种各样的方法去研究X与Y之间的关系。进而对产品推送的时间、地点、目标对象都有了一个清晰的判断。有了这个判断之后,在产品层面是怎么被表达出来的,就变成了精准营销的推荐系统。这就是回归分析在产品层面的表达。
稍微总结一下,想要深刻的理解深度学习,就必须深刻的理解回归分析。回归分析不仅仅是我们课堂上所学到的,例如线性回归。回归分析至少包含三个层面。第一、模型层面,要把一个业务问题定义成为X和Y的数据可分析问题。第二、在这个前提之上,应该有业务的理解。第三、我们希望把它作为一个产品呈现出来。当然作为产品呈现的时候,可能消费者已经完完全全感受不到X,Y和模型框架了,在他面前只是一个非常美好的体验。
高校中的相关课程讲的都是模型层面,而在业务和产品层面讨论的书籍非常少。在这里插播一则广告,向大家推荐狗熊会团队出品的两本书,都是关于数据思维的。其中第一本书,《数据思维:从数据分析到商业价值》,是由我领衔主编的,主要是偏概念性的,以案例为主,没有数据和代码。而第二本书,是由水妈领衔创作的《数据思维实践》,对数据思维如何变成在课堂中可被实施的教学方案做了详细的阐述。有数据,有代码,非常详细,可以支撑一门两学分的课程。在模型层面,我向大家推荐由布丁带队写的《R语言:从数据思维到数据实践》,非常详细,丰富有趣。

既然我们经典回归分析的框架已经非常完备了,为什么我们还需要深度学习呢?如前所述,深度学习是一种特殊的非线性回归分析方法,它特殊在哪里,为什么以前经典回归分析方法不能处理深度学习所面对的问题呢?

大家看这张身份证的样证,里面有很多信息。例如这位同学的姓名叫李久熙,性别是女,民族是汉,出生于1996年11月24日,还有她的地址和照片。如果这些信息作为解释性变量放入一个回归分析模型里的时候,会出现什么情况?我们会发现,传统的回归分析模型,无论是线性还是非线性的,都非常善于处理结构化的X数据。什么是结构化的X数据,如果数据能够在excel表里对齐,这基本上就是一个结构化的数据。但是当我们想用这位同学的照片作为X变量做回归分析的时候,会发现图像是一个几乎不可能用一个excel表对齐的数据格式,它是一个高度复杂的非结构化数据,经典的回归分析方法似乎都不太容易实施了。
通过这个案例,希望你明白深度学习主要应用的领域是处理非结构化数据。而当数据是结构化的时候,从我个人的经验看,深度学习没有任何明显的优势,甚至在绝大多数时候还不如经典回归分析方法。在处理大规模非结构化数据时,传统的回归分析方法将不堪一击,而深度学习此时将展现出明显的优势。
有很多朋友会问,在什么样的场景下,人们会拿一个人的脸部图像去做X变量,再去做一个回归分析呢?其实这非常常见,而且有着重要的应用。

请看这个案例,这张照片是谁,是我们那位天天用加强学习打麻将的博士生。这张照片当中,大家能看到一个小方框框出他这张帅气的脸。用这张照片作为X变量,人们就学习出来,他的性别是男,年龄,人种,还知道他没有戴帽子,知道他带了眼镜,知道他头发不算很长。
这是一个特别典型的应用场景,这个场景特别的重要,为什么?在大量超市的环境中,管理者希望能够了解是什么样的人购买了商品,什么样的消费者走进了店铺,希望知道他的年龄、性别、购物习惯、是否满意等等。这些数据可以通过传统的问卷收集,但显然效率较低。现在有了深度学习的加持,可以直接通过图像识别分析技术得到。
那么在这么重要的一个应用场景中,有了这样一张图片作为X,它又是如何变成一个回归分析模型的呢?例如我想从脸部特征来判断这个人是男生还是女生,那么可以定义Y就是性别,1表示男,0表示女。假设手中有1万张这样的图片,X就是这些图片,而Y就是人手工标注出来的性别。有了这个样本之后,就可以跑一个基于深度学习而产生的逻辑回归模型,通过这样一个模型去预测判断图片上的脸部特征是来自于男性还是女性。这其实就是一个逻辑回归模型,X是脸部特征,Y是性别。如果把Y改成年龄,就可以粗糙地判断他的年龄;如果把Y改成他是否戴帽子,就可以根据脸部特征判断他是不是戴了帽子。所以你会发现这么重要的应用场景对应着许多回归分析模型,这里的Y诸如年龄性别都是传统的结构化数据,而它的X是脸部特征,是高度非结构化数据,是传统模型不擅长处理的,而是深度学习极具竞争优势的地方。
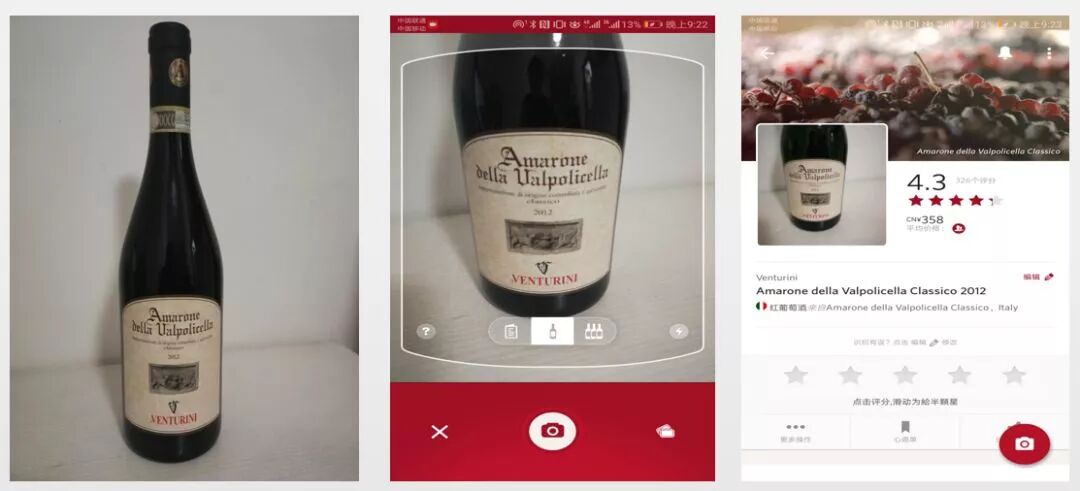
最后给大家出一道有趣的思考题,叫作商品识别。我本人非常喜欢喝红酒,但喝了这么多年,我对红酒却毫无研究。后来我发现了一个APP,只要把红酒的商标拍照上传,过一会儿它就会告诉我,它的品牌产地在哪里,最重要的是它告诉我其它消费者对它的评价,甚至给我一个建议的销售价格。请你思考一下要实现这样的产品,背后需要什么样的技术方案,它所涉及到的核心的模型是什么,它的Y和X分别是什么?
本讲内容就到这里了,更多深度学习的应用案例以及详细讲解,请大家移步阅读原文,到狗熊会个人会员平台,观看王老师的视频讲解。
本讲内容整理:高天悦、水妈
视频制作:高天辰






