作者 冯智,百度大数据部可信计算平台负责人,资深软件架构师。
背景:
《经济学人》曾发表封面文章称,数据已经取代了石油,成为了当今世界最有价值的资源。随着大数据技术的发展、应用与落地,大数据中蕴藏的巨大价值,正不断得以挖掘实现。目前,数据已经成为了企业、社会和国家层面重要的战略资源,成为了各类机构,尤其是企业的重要资产,成为了提升机构和公司竞争力的重要武器,甚至成为了国家之间进行竞争博弈的新领域。谁拥有大数据和操控大数据的能力,谁就有可能掌控未来。
随着大数据技术的迅猛发展,各界对大数据安全重要性认识也在不断加深,包括美国、英国、澳大利亚、欧盟和我国在内的很多国家和组织都制定了大数据安全相关的法律法规和政策来推动大数据利用和安全保护,在政府数据开放、数据跨境流通和个人信息保护等方向进行了探索与实践。例如欧盟发布的《通用数据保护条例》(GDPR)、我国颁布的《网络安全法》以及5月13日刚刚发布的GB/T 22239-2019《信息安全技术 网络安全等级保护基本要求》等法规条例,都是在大数据时代下,对数据安全和个人隐私数据保护的强有力的约束和保障。
在欧盟的《通用数据保护条例》GDPR中,明确了数据所有权与使用权的划分——用户具有其数据的所有权,包括知情权、查阅权、纠正权、删除权和数据转移权等多项权利,而对于数据的使用权,则必须在获得用户同意后才可以进行。因此,在遵守相关法律法规的前提下,将数据所有权与使用权的分离,使得企业在数据流通或共享中,对数据可用而不可得(或不可见),成为了大数据领域的重要课题。
同时,人工智能的所需要的数据通常会涉及多个领域,但数据源之间却往往存在着难以打破的壁垒。例如:在基于人工智能产品推荐服务中,产品销售方拥有产品数据、用户购买记录数据,但没有用户购买能力和支付习惯的数据,因此必须要与相关数据方进行合作,融合双方数据,才能取得更好的合作效果。但在大多数情况下,由于法侓法规、隐私安全、行业竞争、行政手续复杂等问题,这种数据融合难以简单地实现,即使是在同一公司的不同部门间,数据融合也面临着重重阻力。在现实中,想要将分散在各地、各个机构的数据进行集中整合利用,所需的成本是非常巨大的。所以,通过对原始数据的整合集中,几乎不能有效地打破数据孤岛,实现数据流通与共享。
如何在满足数据安全合规的前提下,设计一个机器学习框架,让人工智能系统能够更加安全高效地使用多方数据,形成数据联邦,解决数据孤岛问题,成了破局关键所在。由此,我们提出一个满足数据安全和隐私保护的解决方案:联邦学习。
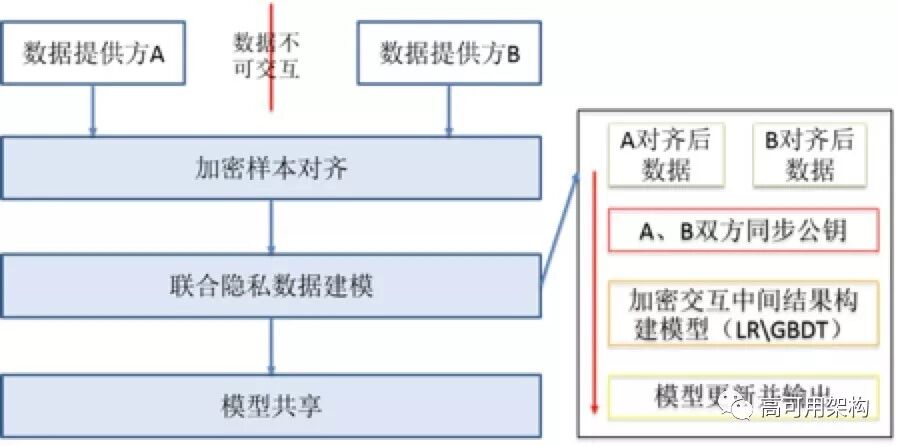
原理:
讲了这么多概念和逻辑。那么接下来,我们更落地一点切入到算法和实现的细节,拿LR和GBDT算法来举例,讲解一下联邦学习算法如何在保护隐私的情况下,完成数据不出本地的建模计算。
基于隐私保护的联邦LR算法实现说明:
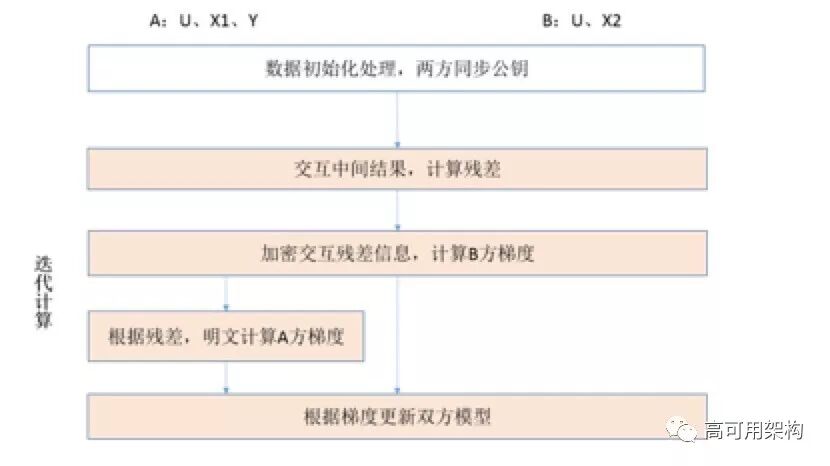
联合建模过程说明:
参与联合建模的两方(A方和B方)分别载入数据,包括:数据ID信息U、数据标签信息 Y、A方特征数据X1,B方特征数据X2,并初始化A、B两方的模型参数W1、W2,A方生成公钥和私钥,并将公钥同步给B方。开始迭代训练数据,更新模型参数。过程如下述步骤说明。
A、B双方各自计算生成残差的中间值,B方将中间值同步到A方,联合计算得到残差,并将残差加密同步到B方;
B方根据密文残差计算密文梯度中间结果,并和A方交互得到本轮的梯度结果gradB;
A方根据残差明文,计算A方的梯度gradA;
A、B双方根据各自的梯度值和学习率,更新模型参数,得到新一轮的模型;
最终输出结果为A、B两方的最优模型参数W,W=W1+W2。
基于隐私保护的GBDT算法实现说明:
如下图所示:
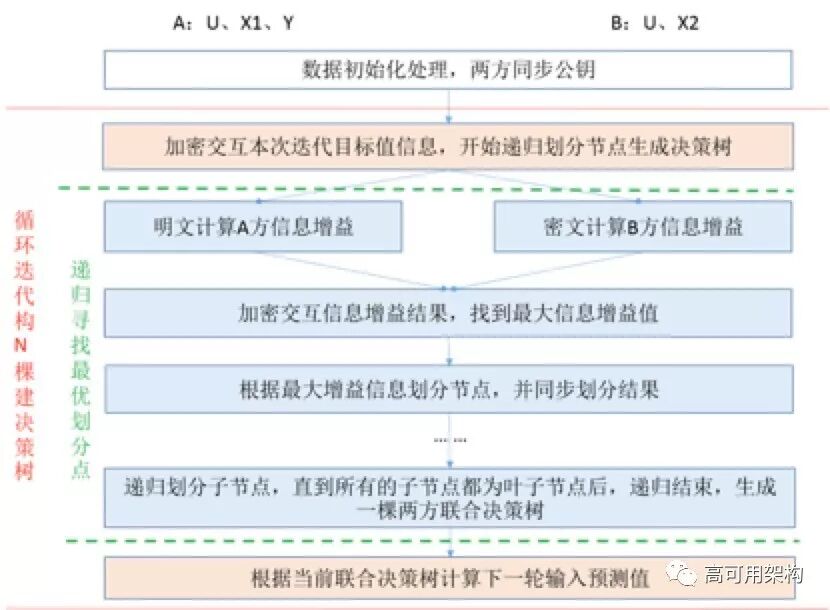
过程实现说明:
参与联合建模的两方(A方和B方)分别载入数据,包括:两方数据ID信息U、数据标签信息 Y、A方特征数据X1,B方特征数据X2。A方生成密钥,并将公钥同步到B方。开始迭代生成N棵决策树,做为模型输出。过程如下述步骤说明;
A方根据标签Y和上一轮决策树的预测值,计算新一轮决策树生成的目标值,并加密同步到B方。然后两方加密交互部分中间结果,递归划分节点,生成决策树,过程如下:
a) A方根据明文目标值计算信息增益;
b) B方根据密文目标值计算信息增益;
c) A、B双方交互中间结果,找到最大信息增益;
d) 根据最大信息增益划分节点,并两方同步划分结果;
e) 继续划分子节点,直到所有的子节点都是叶子节点,结束划分,得到划分的联合决策树结果;
3. 从根据当前生成的联合决策树计算预测值做为下一棵决策树生成的输入值。
最终输入的模型结果为N棵A、B两方联合的决策树。
百度点石-数盾产品:
为更加有效地进行隐私数据保护与安全计算,百度大数据基于多年积累,协同安全部等多部门,打造出数盾多方计算平台,将“大数据+安全”进行技术落地。将联邦学习,可信计算环境(TEE),多方计算从学术,理论层面进行工程化与产品化。虽然我们的联邦学习技术在不断打磨和完善,但是有了产品的支持,可以让技术有针对的场景进行调优和升级。
针对于联邦学习技术:我们提炼出可信的数据分析(trustDA)和可信的机器学习(trustML)两类应用场景。
trustDA(可信数据分析):
trustDA可以在隐私数据不泄露情况下支持两方进行联合安全SQL查询、统计支持求交、表达式计算、常用函数计算等;用户可以利用trustDA所提供的分析能力,探索分析计算表数据,获取所需要的数据结果。
trustML(可信机器学习):
trustML支持联邦式机器学习建模、两方按任意方式隐私数据融合,可同时保护模型、样本、Label三方数据隐私;支持多种联邦算法包括LR、GBDT和NN等。用户在建模场景下,可以利用trustML所提供的能力,完成机器学习模型的训练和预测。
点石-数盾的产品,也参加了信通院的多方计算相关产品评测,希望和业界的产品同台竞技,与业界同仁们互相交流,为隐私保护下的数据联合计算贡献一部分力量。
GIAC全球互联网架构大会深圳站将于2019年6月举行,组委会更是重磅打造3个AI专场:AI(上午场)、AI(下午场)、大数据应用。此次AI专场由百度大数据实验室主任浣军、科大讯飞副总裁刘鹏、爱因互动CTO洪强宁领衔打造。在议题设置方面,联席主席与GIAC组委会为求精益求精,反复推敲,从多个维度考量,囊括了语音识别、自动驾驶、计算机视觉、智慧城市、机器人等等领域,从AI大厂和AI独角兽中精选,包括Google、百度、微软、阿里、中科院、商汤科技、图森未来、搜狗、趣头条等等。既有国内外大厂,又有AI领头羊;既有学术风气,又有工程落地;既有算法历险,也有深度实践。参加2019年GIAC深圳站,可以了解业界动态,和业界专家近距离接触。
参加 GIAC,盘点2019年最新技术,目前购买8折优惠 ,多人购买有更多优惠。识别二维码了解大会更多详情。








