问耕 发自 雁栖湖
量子位 出品 | 公众号 QbitAI

GPT-2,一个逆天的AI。
今年2月,OpenAI首次对外公布了这个模型的存在。GPT-2写起文章来文思泉涌毫无违和感,无需针对性训练就能横扫各种特定领域的语言建模任务,还具备阅读理解、问答、生成文章摘要、翻译等等能力。
但不同寻常的是,这个模型并没有真的开源。OpenAI给的解释是,它太过强大,我们不敢放出完整模型……尽管因此被外界嘲笑,但GPT-2仍然封闭至今。
现在,有人单枪匹马,破解了OpenAI不欲人知的秘密。
而且,是一个大三的学生。
来自慕尼黑工业大学的Connor Leahy同学,在两个月的时间里,付出了200个小时的时间,花费了大约6000人民币,复现了GPT-2项目。
这件事在推特上引发了众多关注。称赞Awesome的有之,深入讨论的有之,甚至连OpenAI的几位资深研究员,都赶来沟通。
另外让人佩服的是,Connor Leahy同学关于机器学习的知识,都是利用空闲时间自学而成。他形容自己是一个充满好奇心的本科生。
“我只是把别人出去撩妹的时间,用来搞AI实验了而已。”

一气之下
GPT-2是OpenAI最棒的研究成果。
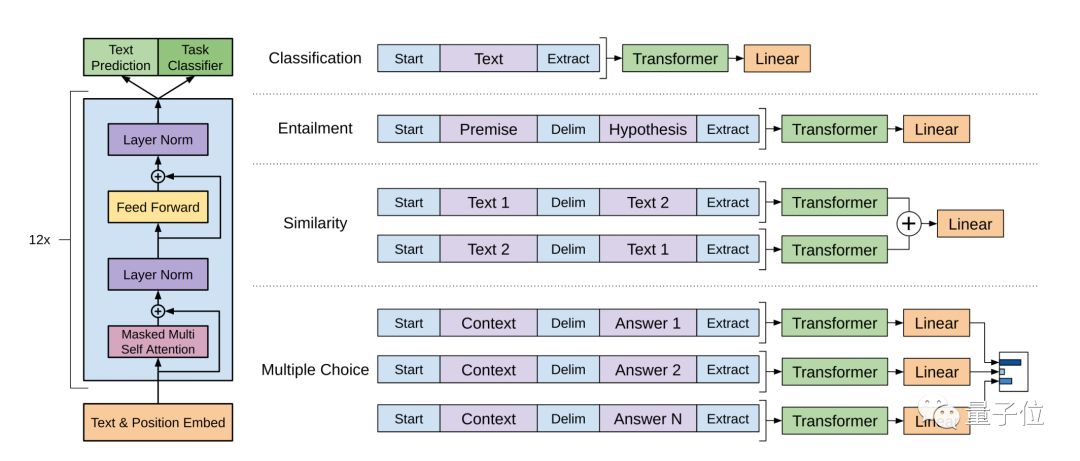
这个模型是GPT的“进化版”,最大区别就在于规模大小。GPT-2参数达到了15亿个,使用了包含800万个网页的数据集来训练,共有40GB。
使用语言建模作为训练信号,以无监督的方式在大型数据集上训练一个Transformer,然后在更小的监督数据集上微调这个模型,以帮助它解决特定任务。
△GPT模型
OpenAI的研究人员表示,在各种特定领域数据集的语言建模测试中,GPT-2都取得了优异的分数。作为一个没有经过任何领域数据专门训练的模型,它的表现,比那些专为特定领域打造的模型还要好。
除了能用于语言建模,GPT-2在问答、阅读理解、摘要生成、翻译等等任务上,无需微调就能取得非常好的成绩。
GPT-2发布后,深度学习之父Hinton献出了他注册Twitter以来的第三次评论:“这应该能让硅谷的独角兽们生成更好的英语了。”
关于这个模型的强大表现,可以参考量子位之前的报道,这里不再赘述。
总之,就是一个字:强。
就是因为强,OpenAI做了一个艰难的决定:不把完整的模型放出来给大家。他们先是放出了不到十分之一规模、1.17亿个参数的小型版本,被吐槽几个月后又放出了3.45亿参数的中型版本。
毫无疑问,GPT-2激发了Connor Leahy同学的好奇心,同时,OpenAI私藏这个模型的决定,也让他非常生气。“信息应该是自由的。”
于是他决定自己动手复现出来。
他不只是因为一时冲动。对于为什么要复现GPT-2,Connor Leahy同学在自己的博客里有长长的思考,其中包括与其害怕AI编造的假新闻,不如积极行动起来,让大家意识到这个问题,勇敢面对然后想办法解决。
当然还有另一个原因,他觉得这么做:
很酷。
复现版GPT-2
“你怎么知道自己成功复现了15亿参数的GPT-2模型?”
这个问题,恐怕绝大多数人都想知道答案。
Connor Leahy同学给出的回应是:两个模型的大小和参数量相同,基于相似的数据源训练,使用了类似的计算资源,而且输出结果质量相仿。
他也给出了两者的一些明确不同,比方:
1、dropout和learning rate官方没有披露,所以设置可能不一样。
2、模型训练使用了Adafactor而不是Adam。Connor Leahy同学不知道怎么把15亿参数+Adam塞进TPU,即便16bit精度也不行。
哎?等下……
一个普普通通的大三学生,怎么能用到TPU搞这种研究?
感谢Google。
Google有一个Tensorflow Research Cloud(TFRC)计划。这个计划面向研究人员,提供1000个Cloud TPU组成的集群,完全免费。这个计划用于支持多种需要大量计算并且无法通过其他途径实现的研究项目。

当时Connor Leahy同学在研究GPT-2复现的时候,遇到了计算资源的瓶颈,然后随口跟TFRC团队提了一嘴,结果却得到了Google慷慨的支持。
实际上,在推进这个项目之前,Connor Leahy同学从来没有使用过TPU。所以,他在博客中热情的对Google团队表达了感谢。
不过,他还是在云端花费了大约600-800欧元(人民币6000元左右),用于创建数据集、测试代码和运行实验。
他用的笔记本是一台旧的ThinkPad。
Connor Leahy同学还对降噪耳机表达了感谢:让我保持宁静。
目前,复现版的GPT-2已经放在GitHub上开源,代码可以在GPU、TPU以及CPU上跑(不建议)。现在作者放出了两个版本,一个是1.17亿参数的小型版本,一个是称为PrettyBig的版本,比3.45亿参数的官方中型版稍大一点,也是目前公开的最大GPT-2模型。
至于15亿参数的完整版,作者计划7月1日发布。
现阶段,Connor Leahy同学邀请大家下载试用,跟他一起讨论复现版GPT-2到底还有什改进空间。在关于这件的博客文章里,他说:我100%能接受大家指出的任何错误,如果你发现问题请与我联系。
关于作者和传送门
Connor Leahy同学2017年考入德国慕尼黑工业大学,目前是一名大三的计算机本科学生。在LinkedIn上,他说自己对人工智能充满热情。
从2018年9月迄今,他还在马克思普朗克研究所实习,也在用来自Google的TPU,研究正经的AI课题。
最后,放一下传送门。
Connor Leahy同学充满思考的博客:
https://medium.com/@NPCollapse/gpt2-counting-consciousness-and-the-curious-hacker-323c6639a3a8
与他在GitHub相见吧:
https://github.com/ConnorJL/GPT2










