01
前言
大家先看两个故障,带着问题去思考:
【故障诊断 - 案例 A】首先大致看一下分片未分配原因:

结果显示分片大都是因为 node_left 导致未分配,然后通过 explain API 查看分片 myindex[3] 不自动分配的具体原因:

我们在 explain api 中指定了只显示 分片 myindex[3] 的信息,诊断结果的主要信息如下:

意味着 Elasticsearch 找到了这个分片在磁盘的数据,但是由于分片数据不是最新的,无法将其分配为主分片。
【故障诊断 - 案例 B】分片分配失败,查看日志有如下报错:

产生该错误的原因是副分片与主分片 sync_id 相同,但是 doc 数量不一样,导致 recovery 失败。造成 sync_id 相同,但 doc 数量不同的原因可能有多种,例如下面的情况:
1. 写入过程使用自动生成 docid
2. 主分片写 doc 完成,转发请求到副分片
3. 在此期间,并行的一条 delete by query 删除了主分片上刚刚写完的 doc,同时副分片也执行了这个删除请求
4. 主分片转发的索引请求到达副分片,由于是自动生成 id 的,副分片将直接写入该 doc,不做检查。最终导致副分片与主分片 doc 数量不一致。
A、B 两个案例的解决方式如何?别急,我们先梳理一下 RED 与 YELLOW 问题
02
正文:RED 与 YELLOW
集群 RED 和 YELLOW 是 Elasticsearch 集群最常见的问题之一,无论 RED 还是 YELLOW,原因只有一个:有部分分片没有分配。
如果有一个以上的主分片没有被分配,集群以及相关索引被标记为 RED 状态,如果所有主分片都已成功分配,有部分副分片没有被分配,集群以及相关索引被标记为 YELLOW 状态。
对于集群 RED 或 YELLOW 的问题诊断推荐使用 Cluster Allocation Explain API,该 API 可以给出造成分片未分配的具体原因。例如,如下请求可以返回第一个未分配的分片的具体原因:

也可以只查看特定分片未分配的原因:
引用一个官网的例子,API 的返回信息如下:
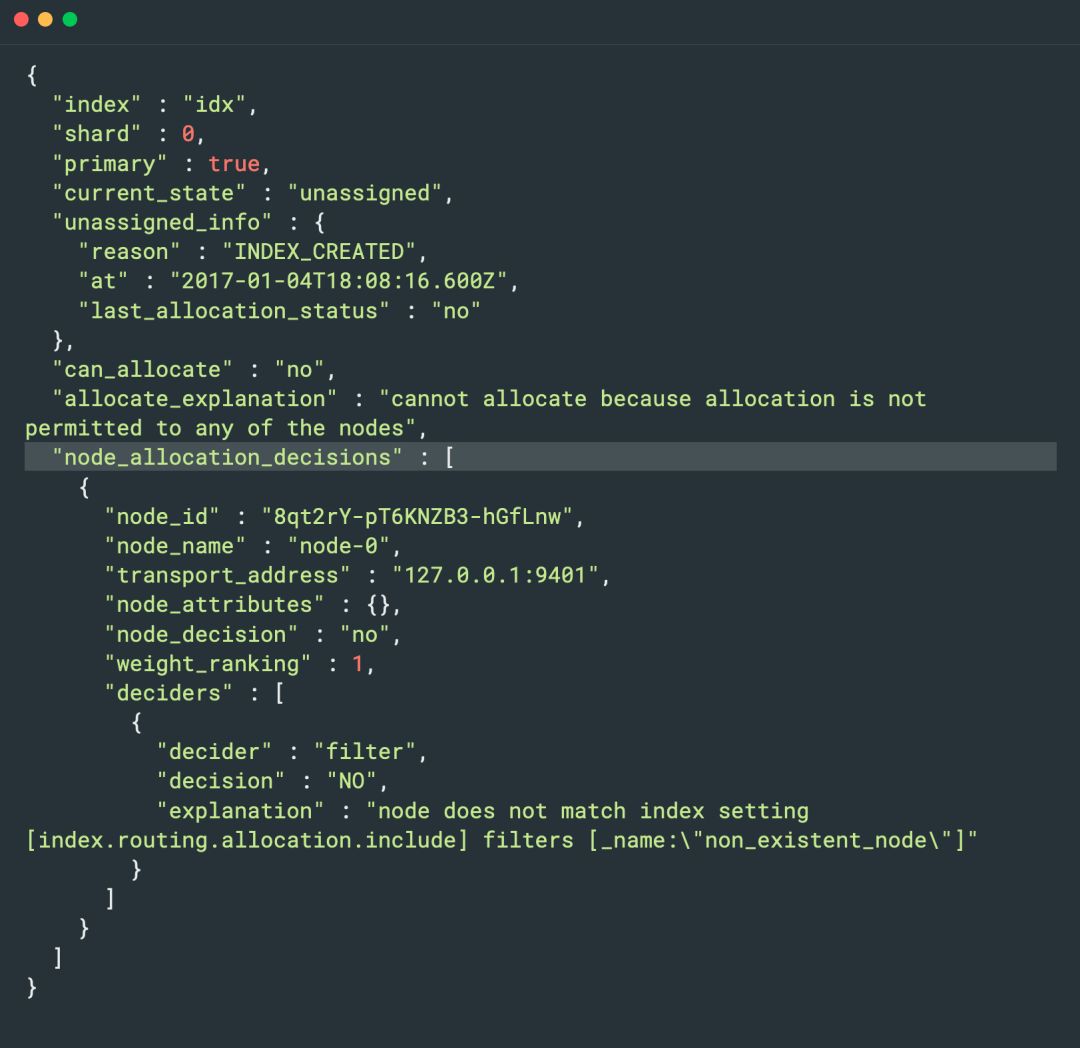
在返回结果中给出了导致分片未分配的详细信息,reason 给出了分片最初未分配的原因,可以理解成 unassigned 是什么操作触发的;
allocate_explanation 则进一步的说明,该分片无法被分配到任何节点,而无法分配的具体原因在 deciders 的 explanation 信息中详细描述。这些信息足够我们诊断问题。
分片没有被分配的最初原因有下列类型:
1. INDEX_CREATED
由于 create index api 创建索引导致,索引创建过程中,把索引的全部分片分配完毕需要一个过程,在全部分片分配完毕之前,该索引会处于短暂的 RED 或 YELLOW 状态。因此监控系统如果发现集群 RED,不一定代表出现了故障。
2. CLUSTER_RECOVERED
集群完全重启时,所有分片都被标记为未分配状态,因此在集群完全重启时的启动阶段,reason属于此种类型。
3. INDEX_REOPENED
open 一个之前 close 的索引, reopen 操作会将索引分配重新分配。
4. DANGLING_INDEX_IMPORTED
正在导入一个 dangling index,什么是 dangling index?
磁盘中存在,而集群状态中不存在的索引称为 dangling index,例如从别的集群拷贝了一个索引的数据目录到当前集群,Elasticsearch 会将这个索引加载到集群中,因此会涉及到为 dangling index 分配分片的过程。
5. NEW_INDEX_RESTORED
从快照恢复到一个新索引。
6. EXISTING_INDEX_RESTORED
从快照恢复到一个关闭状态的索引。
7. REPLICA_ADDED
增加分片副本。
8. ALLOCATION_FAILED
由于分配失败导致。
9. NODE_LEFT
由于节点离线。
10. REROUTE_CANCELLED
由于显式的cancel reroute命令。
11. REINITIALIZED
由于分片从 started 状态转换到 initializing 状态。
12. REALLOCATED_REPLICA
由于迁移分片副本。
13. PRIMARY_FAILED
初始化副分片时,主分片失效。
14. FORCED_EMPTY_PRIMARY
强制分配一个空的主分片。
15. MANUAL_ALLOCATION
手工强制分配分片。
03
解决方式
对于不同原因导致的未分配要采取对应的处理措施,因此需要具体问题具体分析。需要注意的是每个索引也有 GREEN,YELLOW,RED 状态,只有全部索引都 GREEN 时集群才 GREEN,只要有一个索引 RED 或 YELLOW,集群就会处于 RED 或 YELLOW。
如果是一些测试索引导致的 RED,你直接简单地删除这个索引。
因此单个的未分配分片就会导致集群 RED 或 YELLOW,一些常见的未分配原因如下:
分配主分片时,由于找不到最新的分片数据,导致主分片未分配,这种要观察是否有节点离线,极端情况下只能手工分片陈旧的分片为主分片,这会导致丢失一些新入库的数据。
集群 RED 或 YELLOW 时,一般我们首先需要看一下是否有节点离线,对于节点无法启动或无法加入集群的问题我们单独讨论。下面我们分享一些 RED 与 YELLOW 的案例及相应的处理方式。
04
总结
关于前言中的 【案例 A、B 】的故障,大家应该有了一些思路了。
如果有大家想了解故障案例具体的解决方案,请扫码这个课程 👇

集群 RED 与 YELLOW 是运维过程中最常见的问题,除了集群故障,正常的创建索引,增加副分片数量等操作都会导致集群 RED 或 YELLOW。
在这种情况下,短暂的 RED与 YELLOW 属于正常现象,如果你监控集群颜色,需要考虑到这一点,可以参考持续时间,Explain API的具体原因等因素制定报警规则。
集群颜色问题是最常见,也是最简单的问题,在我们处理过的其他问题中,大部分都是内存问题。
如果大家有更多问题,欢迎订阅课程后进《高可用 Elasticsearch 集群》的读者群问题交流。













