“网上冲浪”“886”“GG”“沙发”……如果你用过这些,那你可能是7080后;
“杯具”“神马”“浮云”“偷菜”……如果你用过这些,你可能是8090后;
“吃瓜群众”“一亿小目标”“蓝瘦,香菇”“主要看气质”……如果你用过这些,你可能是9000后;
“awsl”“逮虾户”“律师函警告”“挖藕”……如果你了解这些,你可能……
是混b站的吧!

大家好,我是大鹏,一位勉强通过b站会员考试的普通会员。

众所周知,b站弹幕是流行用语爆发的天堂,如果有一天你发现公司群里95、00后说话都听不懂了,来b站看看弹幕是很好的补习方式。可问题是,这么多视频这么多弹幕该从何看起呢?
数据分析师要有数据分析师的亚子,今天我就教大家用Python零基础来爬一爬这个小破站的弹幕,快速学习一些流行用语(完整教程代码会在文末放出)。
平常我们在看视频时,弹幕是出现在视频上的。实际上在网页中,弹幕是被隐藏在源代码中,以XML的数据格式进行加载的:
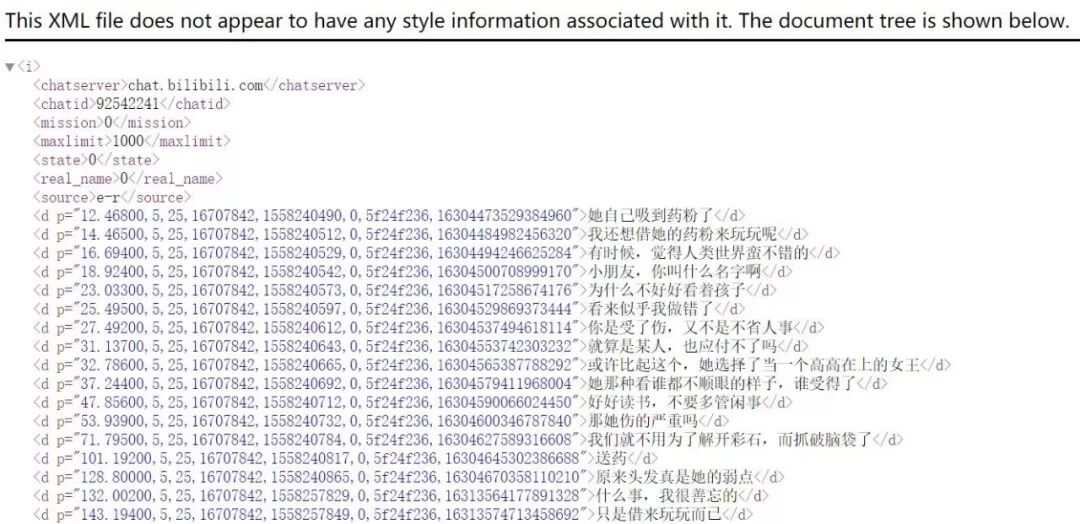
XML和JSON、YAML一样是一种通用的标记信息表达方式,可以简单的理解为一种记录数据的格式。XML和描述网页的语言HTML非常像,所以你会在截图中看到这样的标签。了解更多可以查看教程:https://www.runoob.com/xml/xml-intro.html
那么上图这个弹幕文件的url是什么呢?
https://comment.bilibili.com/92542241.xml
它以一个固定的url地址+视频的cid+.xml组成。只要找到你想要的视频cid,替换这个url就可以爬取所有弹幕了(b站大部分网页给出的字幕限制是1000条)。
一个视频的cid在哪里呢?右键网页,打开网页源代码,搜索cid”就能找到:
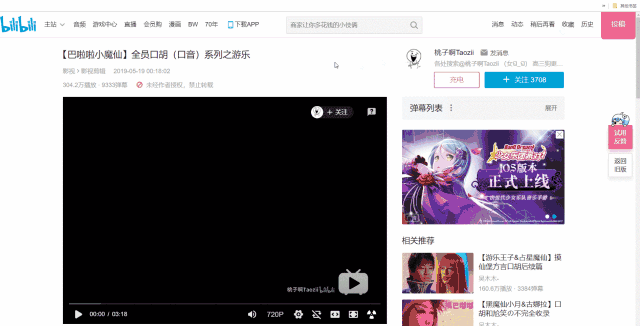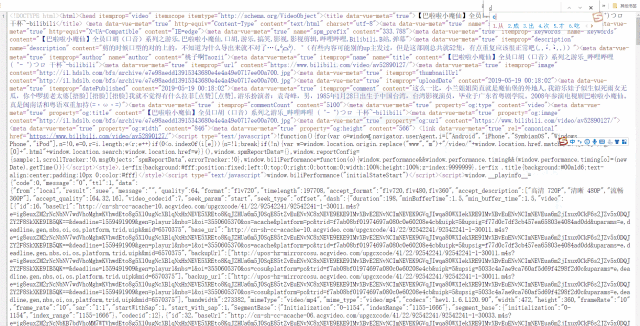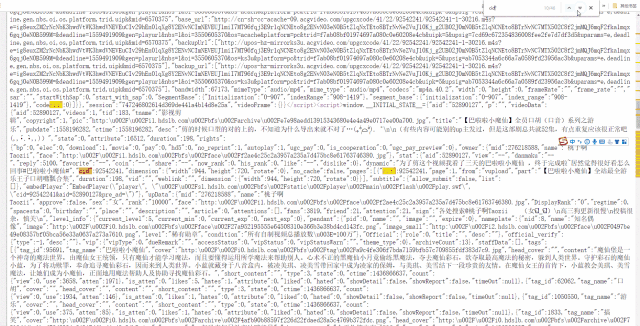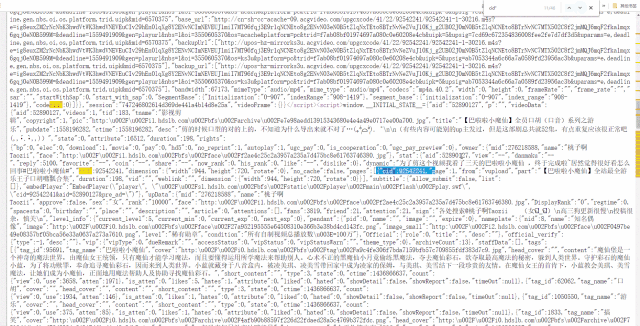
cid在网页源码中是一个很常见的词组,而我们要寻找的正确的cid都会写成"cid":xxxxxxxx的形式。为了缩小搜索范围,在后方加上一个引号会更快搜索到。
有了正确的cid,拼好url,我们就来写爬虫吧!
基本所有初学Python爬虫的人都会接触到requests、BeautifulSoup这两个工具库,这是两个常用基础库。requests用于向网站url发起请求,以获取网页代码;BeautifulSoup用于将HTML/XML内容解析,并提取里面的重要信息。
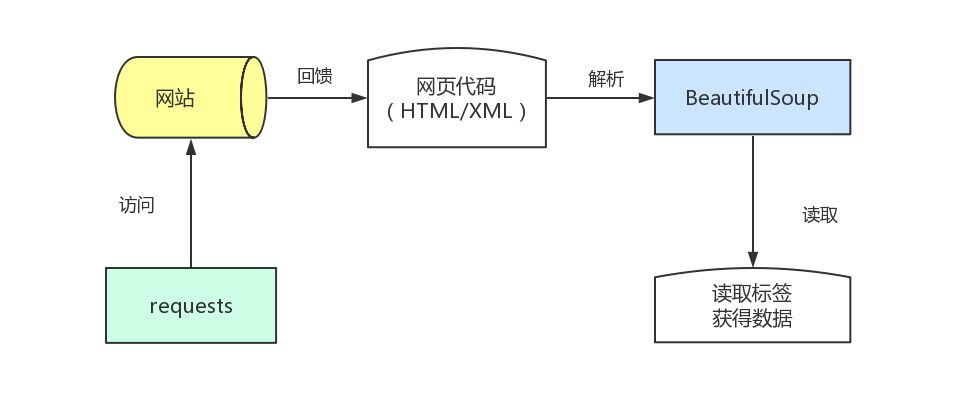
这两个库模拟了人访问网页,读懂网页并复制粘贴出对应信息的过程,能够批量地、快速地完成数据爬取。
观察网页,可以发现,所有的弹幕都放在了标签下,那么我们需要构建一个程序获取所有的标签:

第一步,导入requests库,使用request.get方法访问弹幕url:
import requests
url=r'https://comment.bilibili.com/78830153.xml'
r=requests.get(url)
r.encoding='utf8'
第二步,导入BeautifulSoup库,使用lxml解析器解析页面:
from bs4 import BeautifulSoup
soup=BeautifulSoup(r.text,'lxml')
d=soup.find_all('d')
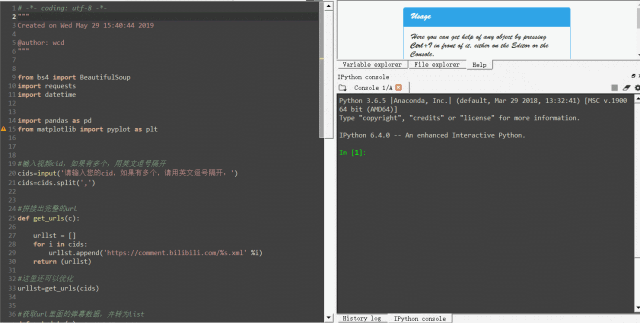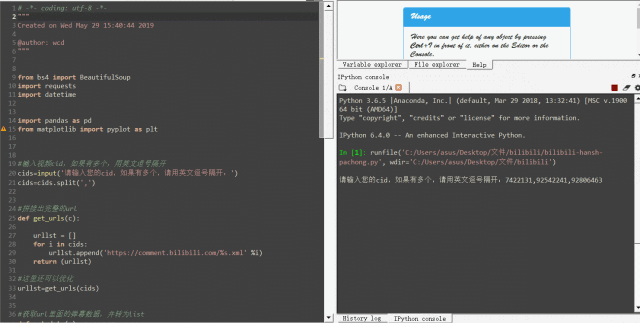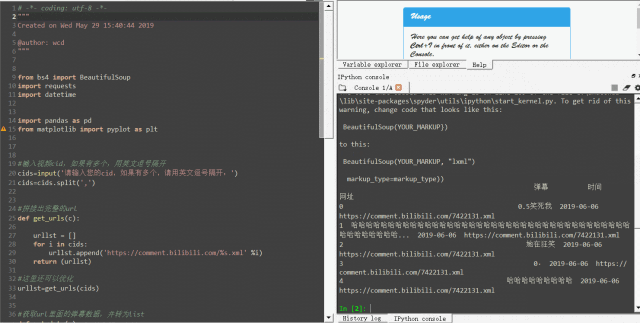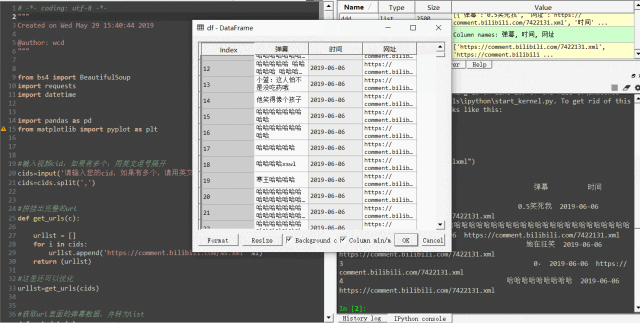
这样操作后,所有藏在d标签里的弹幕内容就被python抓取到了 :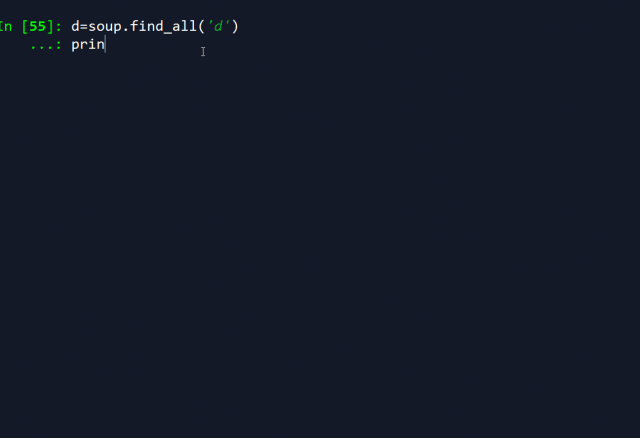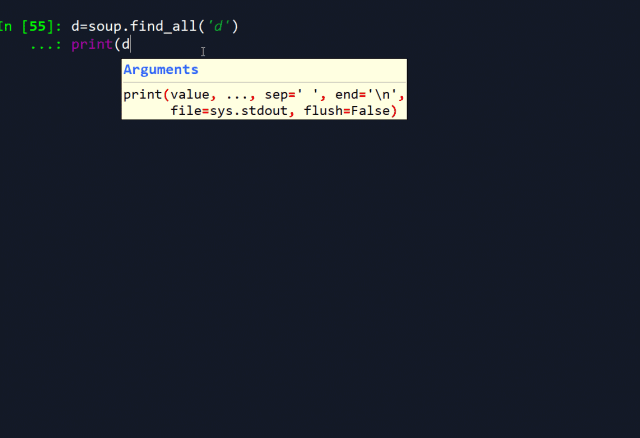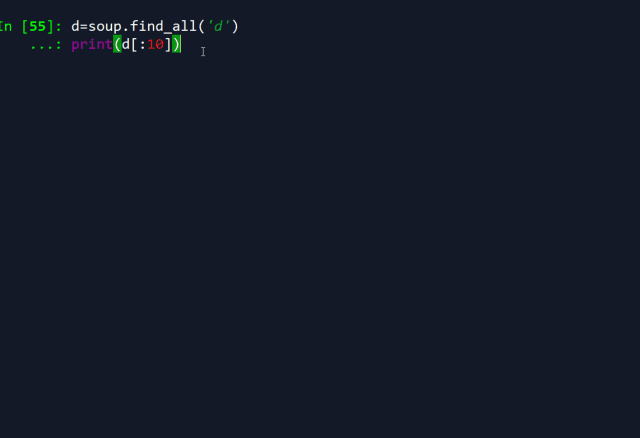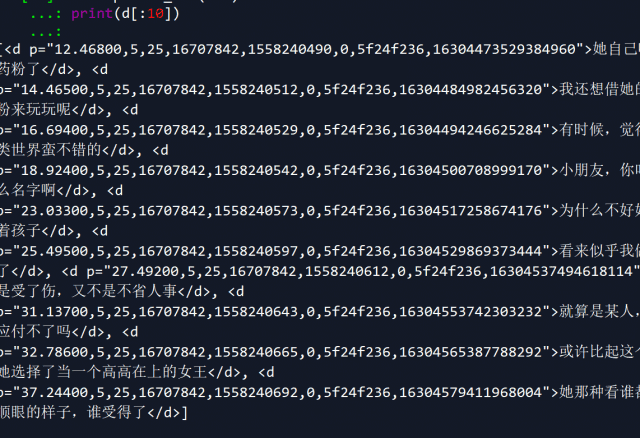
解析完成后,接下来第三步就是运用Python基础函数中的for函数,将单条数据装进字典,再将所有字典装进一个列表:
dlst=[]
n=0
for i in d:
n+=1
danmuku={}
danmuku['弹幕']=i.text
danmuku['网址']=url
danmuku['时间']=datetime.date.today()
dlst.append(danmuku) print('获取了%i条数据' %n)
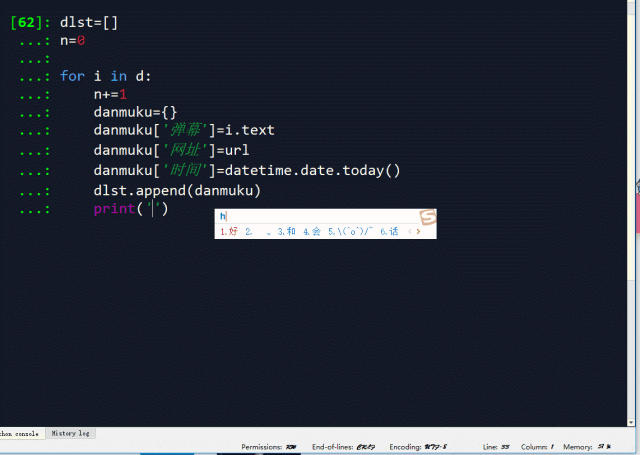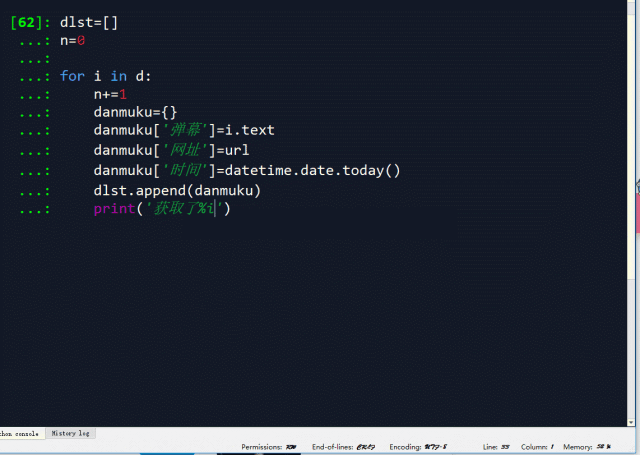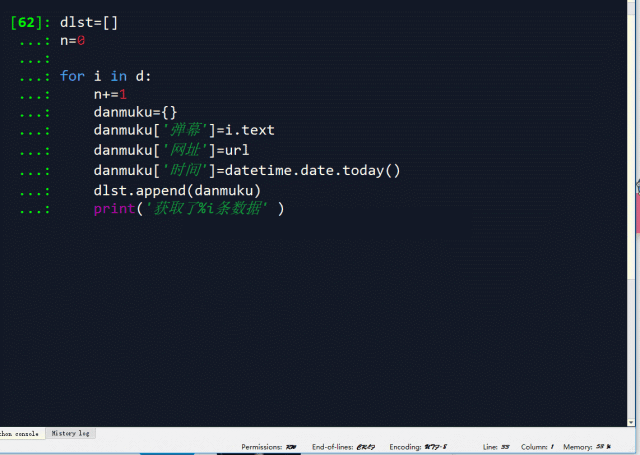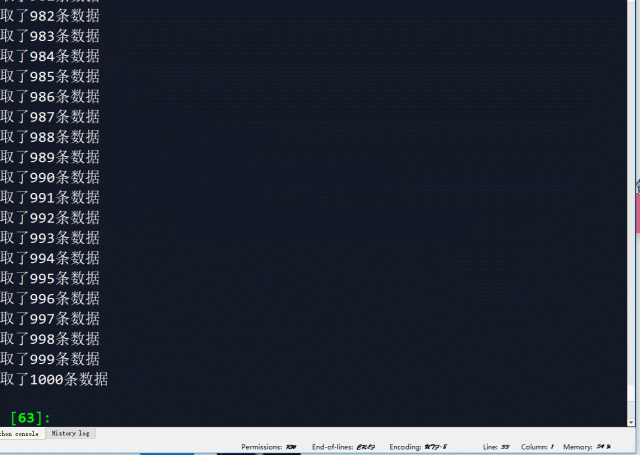
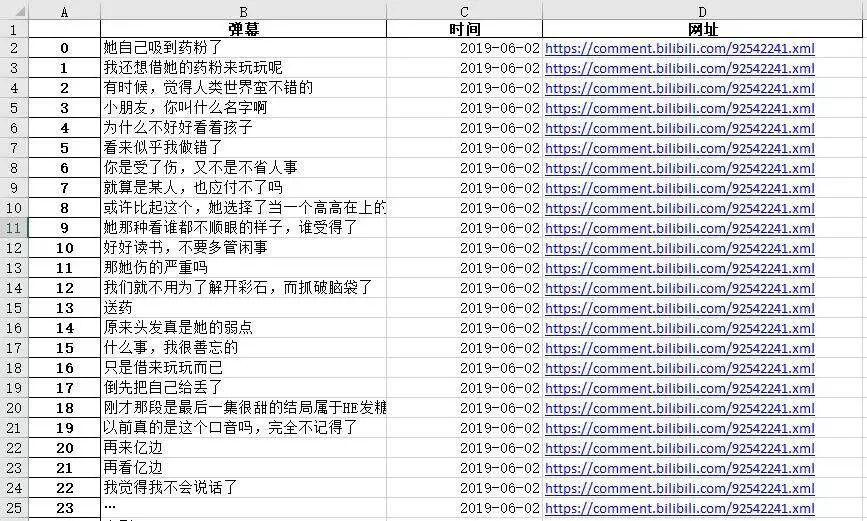
此时整理好的弹幕数据如下,是不是已经有点常见的excel数据的意思了? 
那我们就把它变得更加像excel数据吧!第四步导入大名鼎鼎的pandas库,一行代码将列表数据转为DataFrame数据,并保存到本地,爬虫的大体框架就完成了:
import pandas as pd
df=pd.DataFrame(dlst)
df.to_excel('b站弹幕数据.xlsx')
没错,这个爬虫还存在很多可以优化的地方,比如是不是可以爬取多个弹幕?是不是可以封装起来,输入cid就出来结果呢?
当然可以。只要我们熟练掌握def定义函数功能,就可以把上述的爬虫功能写成一个爬取函数:
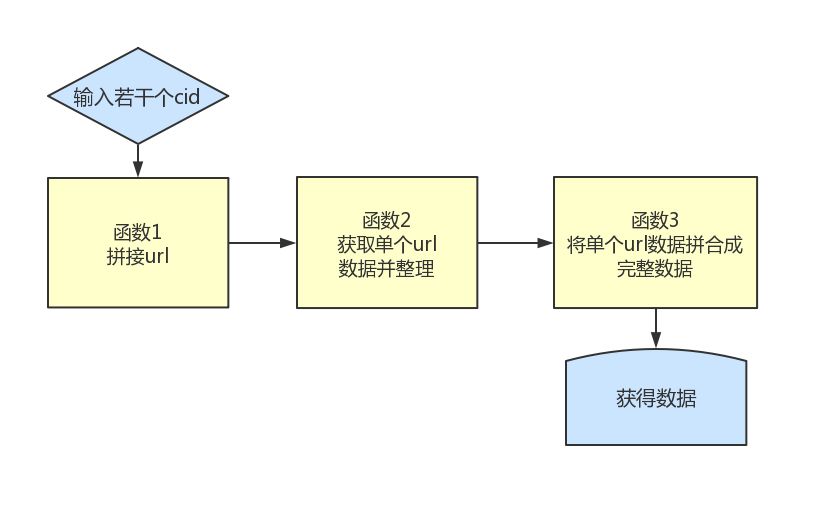
一键爬取一时爽,一直一键一直爽,完整代码就在文末,大家自己爽吧。
鬼畜区出来的流行词永远是最有脑洞的,所以本文以最近很鬼畜的“巴啦啦小魔仙口胡”视频弹幕为例,教授流行用语:

首先看看,发弹幕的小伙伴有多少是话痨呢?
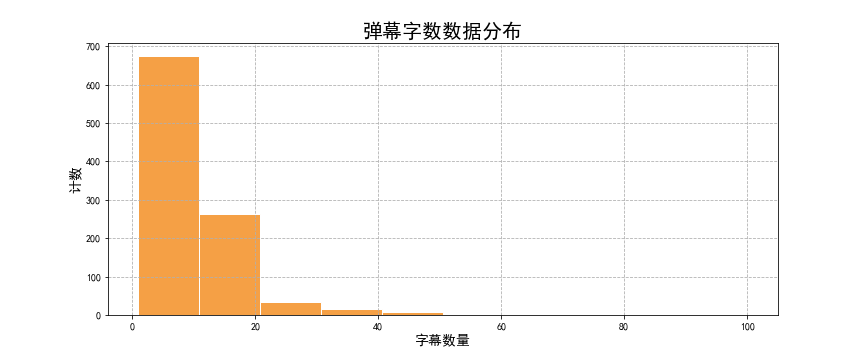
虽然大部分的弹幕都在10个字内解决,但平均来看大家会使用9.8个左右的字表达吐槽,最长的一位同学弹幕字数长达100字。10个字在平时说话可能就是一个短句,但是放在弹幕上已经是很长的一串了,看来刷弹的话痨还是很多的。
那么这些话痨都在说什么呢?
字数最多的前二十位同学就是在笑,沉浸式的大笑,果然人类的本质就是复读机:

既然说到复读机,除了哈哈哈以外,还有哪些词是经常被复读的呢?

“合影”“亚子”“雨女无瓜”“名场面”……不得不说这个小破站的网友脑洞清奇。有了这个,妈妈再也不愁我跟不上00后的步伐了。

我知道,你一定想问,零基础真的能快速学会Python技巧,做一些好玩的事情吗?那么来网易云课堂听我的免费Python直播课程,你能学到更多有意思的技能!
扫码即可领取本文代码,免费直播课程

直播详情










