

要不要用准确性换可解释性?这可能是许多资源有限的创业公司,在技术研发中面临的重要问题,同时也是机器学习可解释性研究中的重要议题。
把场景具体化,让我们先来看这样一道选择题。
如果你是一个投资公司老板,针对电话诈骗检测,现在有一个可信度85%,但无法解释的“黑盒”模型,和一个可信度75%,但可解释的机器学习模型摆在你面前,你会选择哪一个?
6月19日下午,AItime第二期以《论道自动机器学习与可解释机器学习》为主题,邀请到美国伊利诺伊大学芝加哥分校(UIC)特聘教授Philip Yu(俞士纶)、美国密歇根大学梅俏竹教授、北京大学的王立威教授和百度高级研究员李兴建进行了一次对谈。
这次的对谈就从这个问题开始。
但最初的最初,让我们先来理清这两个概念:自动机器学习与可解释机器学习。
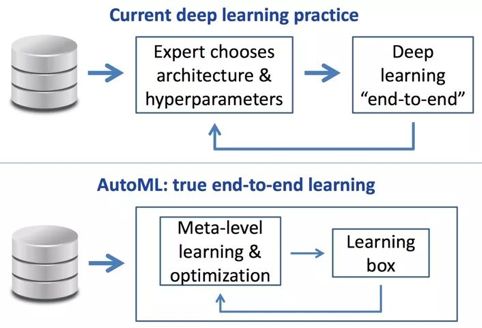
王立威教授首先解释了什么是机器学习自动化。机器学习的应用需要大量的人工干预,比如特征提取、模型选择、参数调节等,深度学习也被戏称为炼丹术。
而AutoML 是试图将这些与特征、模型、优化、评价有关的重要步骤进行自动化地学习,实现从end to end 到learning to learn,使得机器学习模型无需人工干预即可被应用。让机器自己炼丹,让深度学习自动寻找最优框架。
使用AutoML,就像是在使用一个工具,我们只需要将训练数据集传入AutoML,那么这个工具就会自动帮我们生成参数和模型,形成训练模型,这样即使不具备机器学习方面深入的专业知识也可以进行机器学习方面的工作。
可解释机器学习(Explainable ML):信任之后人与机器才能更好地互动

随着AutoML学习模型的发展,机器学习的黑箱似乎在越来越大。这种缺乏解释的情况既是一个现实问题,也是一个伦理问题。所以近年,很多研究者呼吁我们需要可解释机器学习。
梅俏竹教授在解释XML的时候强调,辩题的核心还是在于AI和人的关系。我们大多同意未来的世界是AI与人共同合作,AI目前肯定还是做不到取代人。AutoML与XML其实并不矛盾,问题在于合作中如何人要如何达成对于AI的信任。
基于人工智能的结果越重要,对可解释人工智能的需求就越大。高风险的情况下,比如自动驾驶和医疗领域,人们可能需要明确地解释是如何得出特定结果的。而相对低风险的人工智能系统可能就更适合黑盒模型,人们很难理解其结果。
场景问题是大家公认的导致可解释问题重要的一个原因。我们可以容忍机器没有理由地给我们错误推荐了一首不喜欢的歌,但是把重大的投资问题或者医疗建议交由机器决定的时候,我们希望可以得到充分的解释说明。
解释是跨多个行业和科学学科的负责任的、开放的数据科学的核心。
俞士纶教授提到对可解释人工智能的需求与人类的影响会同步上升,比如医生应用机器评估数据并得出决策数据,但是机器无法回答病人的疑问。以及在过滤假新闻的时候,机器在作出粗略判断和初步筛选之后,还是需要人类解释其中细微差别。
Hans是一匹聪明的马,人们以为它会计算加法,因为有人说2+3的时候,它就会敲5下蹄子。但后来人们发现,它只是单纯地在敲蹄子,直到人们的表情发生改变就停下来。如果没有可解释性,任何人都无法保证高正确率模型其实只是另一匹Hans。
李兴建工程师说道,可解释也是企业实际应用非常关心的问题。如果人工智能系统出错,构建者需要理解为什么会这样做,这样才能改进和修复。如果他们的人工智能服务在黑盒中存在并运行,他们就无法了解如何调试和改进它。
但很有意思的事,解释可能无法穷尽。
王立威教授提出一个有趣的例子。机器作出判断,这是一只猫。如果我们要寻求解释,问为什么这是一只猫,机器可能回答,因为它有皮毛,有四只猫爪……我们再问,那为什么这是皮毛?
当然机器还可以继续解释,但是解释的结果可能会更加复杂,比直接告诉你这是皮毛要曲折得多。
人类大脑是非常有限的,而现在的数据太多了。我们没有那么多脑容量去研究所有东西的可解释性。世界上有那么多应用、网站,我们每天用 Facebook、Google 的时候,也不会想着去寻求它们背后的可解释性。
对于医疗行业的可解释机器学习的应用王立威教授也提出完全不同的想法,他认为只有在开始阶段,医生不够信任系统的时候可解释才重要。而当系统性能足够优化,可解释就不再重要。在不可解释上做的能超过人类,这就是未来机器学习的可为之处。
Geoffrey Hinton 曾经大胆宣称,纠结深度学习(可与不可)解释性问题根本是一个伪命题。为什么一定要存在识别数字的理论才能证明我们擅长识别数字?难道非要通透骑车每一个细节的物理力学,才能证明自己会骑车?其实不是神经网络需要理论解释,而是人类克制不住自己讲故事的冲动,理论再合理也只是主观判断,并不能帮助我们理解为什么。
王立威教授表示赞同,以历史做类比。历史书上简单归纳出的胜败输赢难道就是真实的历史吗,不过是人类编造出的故事。真实的历史复杂,现实生活复杂,只言片语的解释和理论不过是管窥蠡测。
通过神经网络反思人的思维,同一个网络框架,初始点不同结果可能完全不同。解释可能会有两套截然不同的解释,就像对同一件事不同的人可能会有不同的解释。
一个人都无法完全理解另一个人,更何况与人的思维完全不同的机器?即使把alpha go下围棋中的所有数据告诉人也没有用,因为机器每一步的判断所用的数据是百万量级,而人最多处理到百的程度。就算打开黑匣,一千个人可能会看到一千种解释。
俞士纶教授认为Hinton的说法还是有些激进,解释不仅是为了说服,解释的形式和含义都非常之广,就算是autoML我们还是要朝着可解释的方向不断推进。
梅俏竹教授则认为单纯讨论autoML还是XML是没有意义的,就像我们判断autoML好不好,怎么算是一个好的推荐算法?如果机器中午十二点推荐你去吃午饭,的确它的准确率是百分之百,但是对于用户来说这是完全没有意义的一个推荐。评判需要加入人的因素进行考量,还是要看人机配合得怎么样,加入用户体验。
autoML的能耗问题:ACL论文痛批其捡芝麻丢西瓜
最近一份提交到自然语言处理顶会ACL 2019的论文引起热议,研究人员对几种常见的NLP模型进行碳排放评估后发现,像Transformer、GPT-2等流行的深度神经网络的训练过程可以排放超过62.6万磅的二氧化碳当量,几乎是美国汽车平均寿命期内排放量(包括制造过程)的五倍。
某些模型可能经过了千百次的训练之后取得最优成果,但是实际进展非常微小,而背后的代价是不成比例的计算量和碳排放。
李文钰提出业界现在的解决办法有比如共享参数、热启动,利用之前训练好的参数,避免再从头训练一个模型。
真正的autoML应该是在大型数据集上搜索,操作类型,拓扑结构,加上人的先验知识,未来希望找到又小又高效的好的模型。我们希望用机器代替节约人力,但是人也要去限制一些盲目搜索,节约成本的约束。

几位教授最后都同意autoML和XML在未来是可以结合的。不管是autoML还是XML,现在还是在底层信号的层面运作,比如识别图像、文本,关键还是在知识层面,我们需要的是对整个网络结构更高层、更进一步的理解。
梅教授提出过犹不及,有三条走得太过的路是炼金、观星和算命。
炼金就是走极端的autoML之路。不要为了全自动就抛开所有代价去追求自动化,最后你也无法保证炼出来的是金子还是破铁;
观星,扩大范围,如果非要在一大堆的变量中拼命找联系,总能找寻到一二;
而算命的原理是找一些你愿意听的说,讲你爱听的故事,观星和算命都是在可解释的道路上走得太远。
最后的最后,梅教授也提醒大家,解释性可以解释部分问题,关于伦理,关于道德,但是它不是万能药。不要纠结于理解,为了理解而理解。
编辑:文婧












