
标星★公众号 爱你们♥
作者:Fan Zhang
编译:Eva | 公众号翻译部
近期原创文章:

所有模型都是错的,但其中有些是有用的!
大家习惯在微博上浏览查看某些股票专家的观点意见。根据我们的经验,社交媒体的普遍共识通常可以用来预测中国A股未来2-3天内的表现。因此。我们准备研究一下:社交媒体对股票市场的预测能力。
中国A股股票数据:
日权益类数据包括:日期、最高价、最低价、开盘价、收盘价、调整后的收盘价格和成交量。历史权益类数据范围为2014年1月至2017年7月。

表1. 选定的微博财经类账户ID、检索到的推文数量、每个ID的起止日期
社交媒体数据:
微博可以通过API进行访问,但是检索到的微博内容和请求频率对于普通用户是有限的。
例如,如果一个帐户在30分钟内通过API发出的请求超过5000次,则相应的微博帐户将被阻止进一步访问。
由于API账户请求的限制以及不重要的公开账户产生的“噪音”,本项目将会根据交易经验选择20个微博财经账户。一个强有力的假设是,选定的账户是具有清晰市场洞察能力的参与者,从他们的微博推文内容中可以推断出将预测未来的市场走势。
20个选定的有效微博账户ID如表1所示。
检索到的微博推文开始日期均不同。回测区间确定为2016-10-01至2017-07-14。
1、在每个交易日的上午00:00-09:30,从选定的的财经微博账户中获取社交媒体数据。
2、选择交易活跃或者是有被选入投资组合潜力的的四个有代表性的板块。
3、如果至少有3个专家(微博财经账户)同时支持一个特定的板块,则购买该板块表现最优的股票,股票在投资组合中的资金权重相等。
4、以开盘价买入持有一天,在第二天开盘时卖出。
该项目的具体流程图如图1所示。
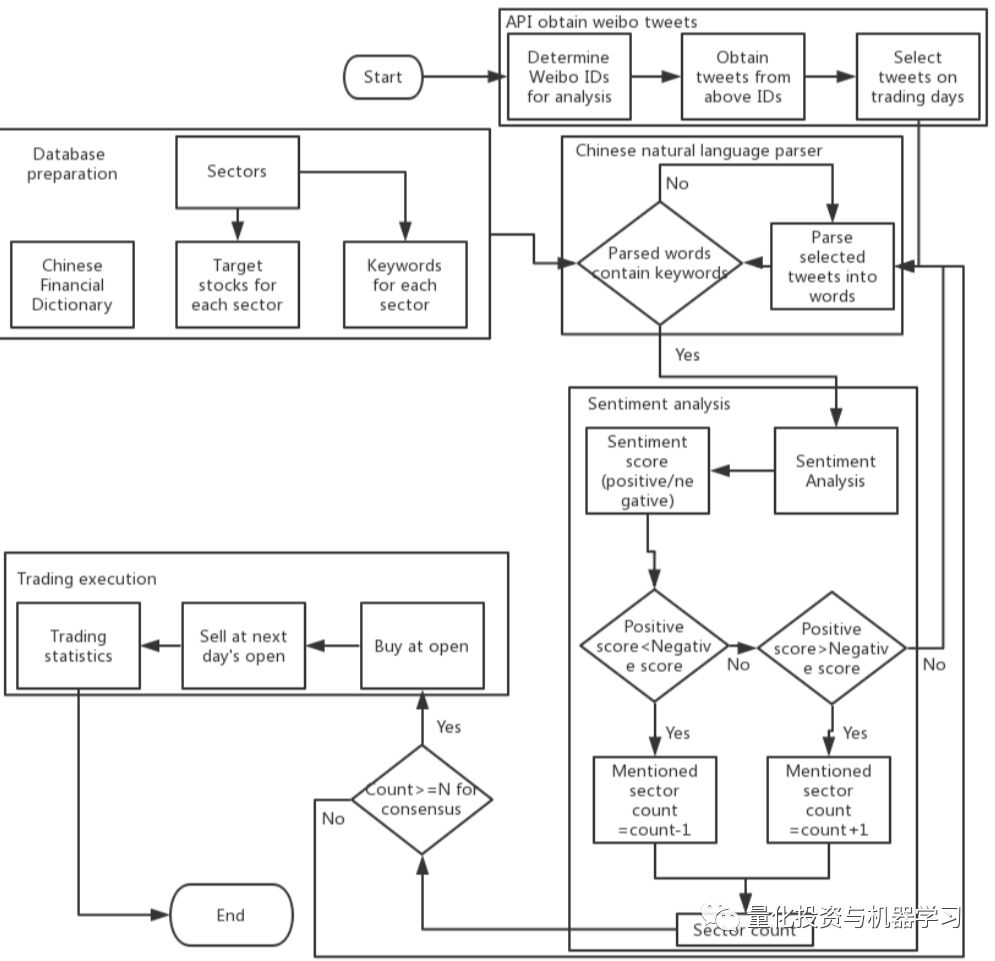
图1. 项目流程图:通过API、数据库、中文自然语言解析器、情绪分析、交易执行等来获取微博推文内容
板块的选择:人工智能(AI)、银行、锂和证券。之所以选择这些板块是因为它们是经常在微博上被讨论,并且它们对应的关键字易于使用自然语言处理技术进行解析,从而避免了在分析的微博推文中出现歧义。每个部门的中文关键词如表2所示。
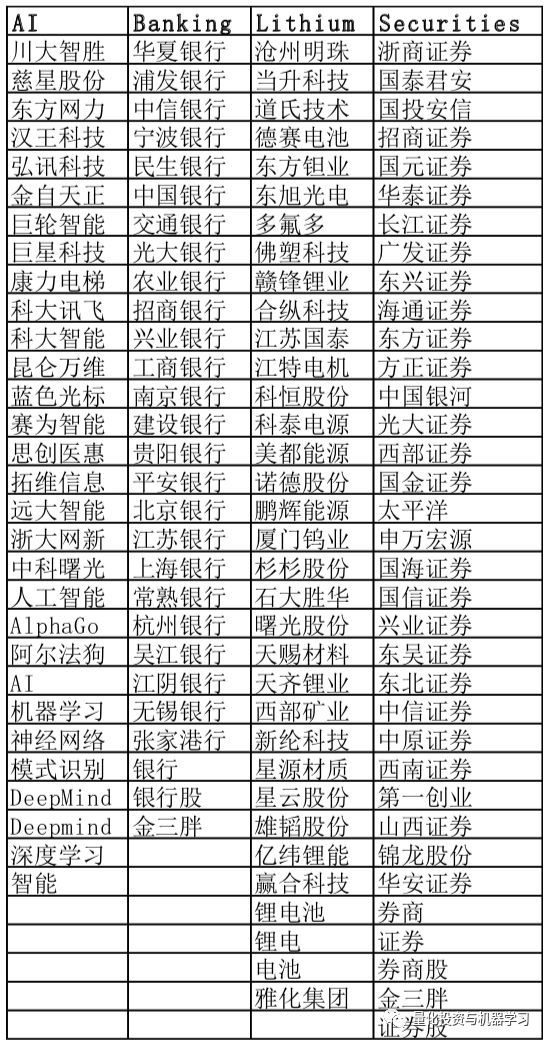
表2. 关键词:人工智能,银行,锂和证券
在每一个板块中,如果相关板块受到微博上专家的“青睐”,那么只购买最具代表性并且活跃交易的五家股票。每个板块的选定股票如表3所示:

表3. 为每个行业选择有代表性的股票
虽然有多个中文自然语言解析器可用,但没有一个软件包是为中国金融市场设计的。很多金融关键词并没有被地正确解析。例如,股票 “中国银行”将被分为“中国”和“银行”,而不是作为一个整体来确认。由于缺乏金融关键词数据库,这种错误的分析会给交易决策带来错误的信息。
因此,以下为这一公开中文语法分析器(HANLAP)4的修正:该项目构建了4952个金融关键词的中文金融词典,包括所有交易的A股股票和微博上使用的大多数俚语/行话。
修改后的中国金融解析器显著提高了交易中的解析性能。
地址:
https://github.com/hankcs/HanLP
情绪分析是通过一个商业软件包进行的:BosonNLP。对于每一条微博,情绪分为正倾向和负倾向两个分数,两个分数之和为1。例如,“这顿饭不错”的情绪分数是0.98和0.02,这意味着这一陈述是强烈的正面,两个分数加起来是1。
地址:
https://bosonnlp.com/

情绪分析结果的一个样本快照如图2所示。
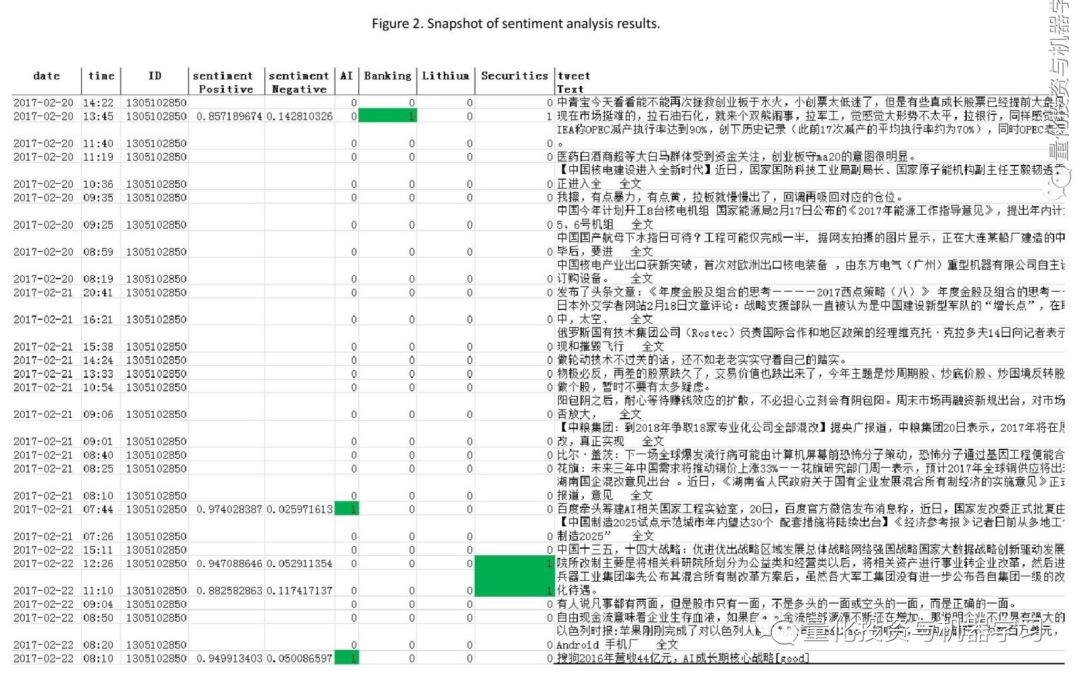
对于买入信号的标准设置为:在上午00:00-09:30期间,至少有三个微博ID在某一天支持该板块。
1、从2016-10-01至2017-07-14,中国市场共计有188个交易日。
2、期间出现了四次交易机会:两个是关于人工智能的,另外两个是关于证券。
3、四笔交易中有三笔产生正的收益。
4、具体的交易记录见图表4。
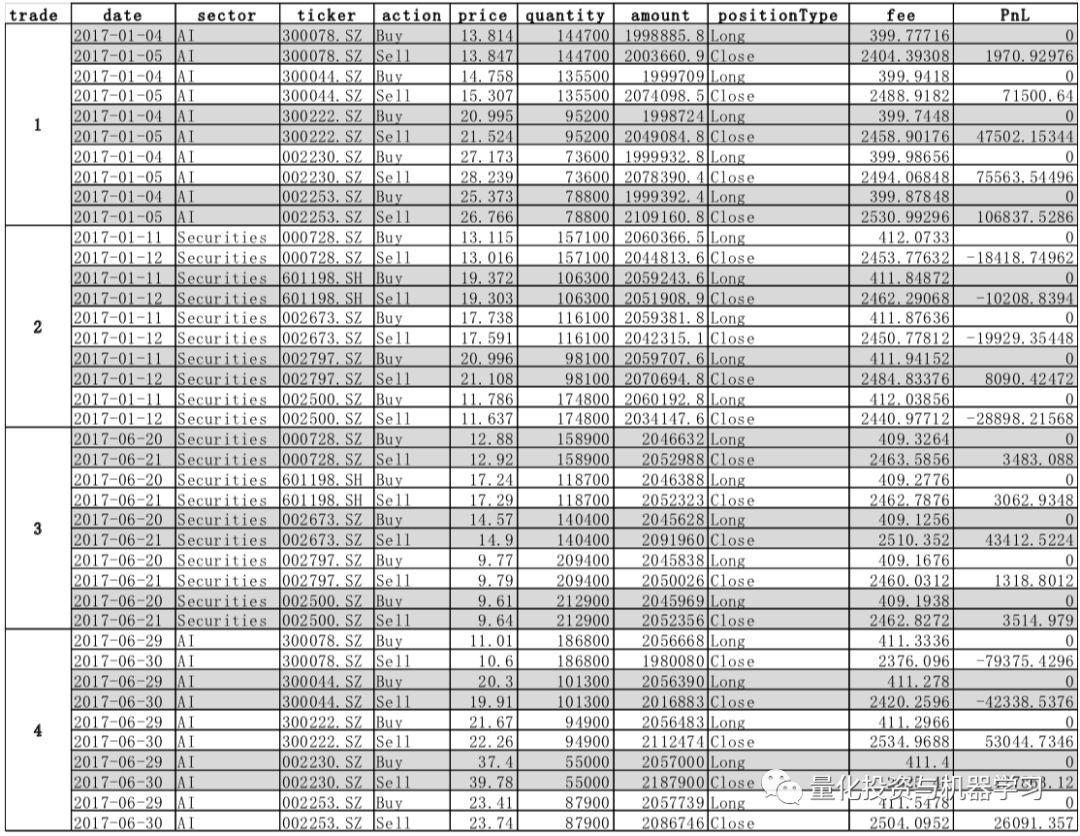
表4. 2016-10-01 至 2017-07-14期间交易回测记录
该策略实现了3.74%的回报率(年化回报率5.14%),夏普比率为0.86。具体表现如图3所示。
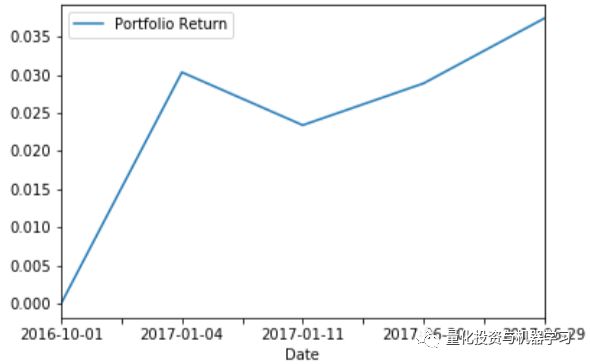
图3. 组合的收益率表现基于至少3个微博财经账户的推荐
场景1:
如果将买入信号的标准从3个微博ID放宽到2个微博ID,则策略表现呈现为负的收益率,-9.83%(图4)。微博推文获取时间段是在每个交易日的上午00:00-09:30之间。
图4 组合的收益率表现基于至少2个微博财经账户的推荐(上午00:00-09:30)。

图4
场景2:
如果将买入信号的标准设置为4个微博ID而不是3个微博ID,则在此期间未检测到任何交易机会。微博推文获取时间段是在每个交易日的上午00:00-09:30之间。
场景3:
微博推文获取的时间段从00:00-09:30扩展到00:00-14:575,那么符合买入信号标准的微博ID数量增加到8个和10个,以第一天的收盘价买入,在第二天以开盘价卖出,投资组合获得负的收益率,分别为-3.07%和-0.61%(图5和图6)。
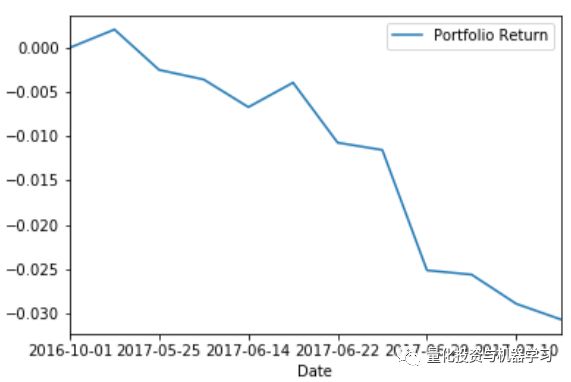
图5
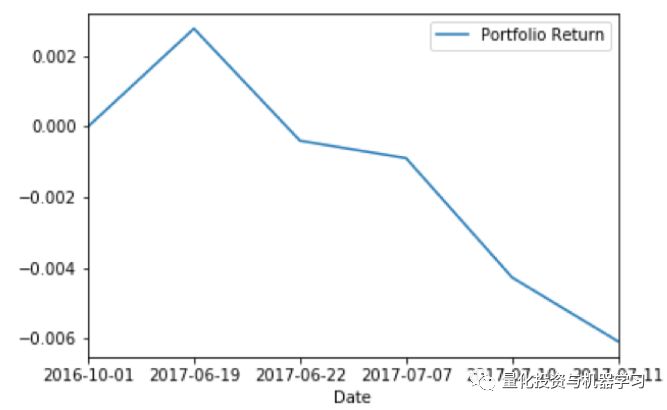
图6
通过进一步分析可以得知,将获取微博消息的时间区间延长至14:57后产生的负收益率可能是因为:在交易期间,大多数选定的微博ID都会对当天表现良好的板块发表评论,他们是在板块上涨后才对此板块进行评论;也就是说,他们在交易时间的微博推文很可能是回顾性的,而不是带有预测性的。因此,基于日内交易时间发布的微博推文而作出的交易决策很有可能失败。
一个更全面的微博推文数据库将会使得该策略的回测结果更加可靠和具有统计说服力。
每条微博文章中提到的时间可以是不同的时间段:过去(昨天、上周)、短期(1天)、中期(几周)或长期(几个月)。精准的处理时间可能会显著提高策略的准确性。


微博Aaaa股
—End—
量化投资与机器学习微信公众号,是业内垂直于Quant、MFE、CST等专业的主流量化自媒体。公众号拥有来自公募、私募、券商、银行、海外等众多圈内10W+关注者。每日发布行业前沿研究成果和最新资讯。










