前言:在前5期推文中我们讲述了如何搭建基于Python的数据科学环境。现万事俱备,只欠代码!众所周知,狗熊会中政委带领大家完成过很多关于火锅吃货的案例,政委可谓是狗熊会的“火锅英雄”。本系列推文的众多部分仍然以火锅团购数据为分析案例,来阐述如何利用Python进行数据科学实践。那么,现在就请大家开始基于数据科学实践的火锅团购分析之旅。本次推文是由程茜与政委共同推出。
提起冬天,大家会想起什么?是银装素裹的景色,亲友相聚的团圆?还是春节假期难得的闲暇?对于吃货如我来说,冬天是最好的季节。冬天里炖的酥烂的羊肉汤,捧在手里香甜诱人的烤红薯,炒栗子,浇着爽辣汤汁的烤鱼等等。冬天吃得多还有一个绝妙的理由:积蓄热量,抵御寒冷(义!正!言!辞!)。冬天里,最不能落下的美食之一,就是本章(也是后续多个章节)要介绍的主题——火锅。火锅,作为一种历史悠久、老少皆宜的美食,全国盛行。冬天和三五好友相约打边炉,才是初冬应有的味道。

如果你是吃货,你是否调研过火锅有多少种呢?你最喜欢吃的是哪一种火锅呢?是以麻、辣为主的川系火锅?还是鲜美清淡的粤系火锅?是传统京味铜炉火锅?又或者是汤汁浓郁的滇味腊排骨火锅?
火锅不仅美味,还带来了巨大的产业。根据《2018中国火锅产业餐饮大数据研究报告》显示, 我国火锅餐饮市场从2014年至今,年增长率均在10%以上,这就导致越来越多的人投身火锅行业。从数据来看,14年至今,全国新增的火锅店面仍然多于关闭的火锅店面,火锅行业仍然在扩张之中。这一现象的直接结果就是本行业出于完全竞争的状态下,各个店家竞争十分激烈。
本文收集了截止2018年8月1日某线上平台在线的西安与郑州的火锅团购产品的销售数据。基于该数据,本书将以火锅行业面对的真实业务问题,例如研究影响火锅团购销量的因素;研究如何为火锅商户设计团购套餐;研究新开火锅店的选址。通过这些真实的业务问题,从而介绍如何使用Python进行数据科学的实践。而本章主要介绍Python语言的基础。
数据分析第一步,干什么?肯定是“读数据”。如果数据都读不进来,也就无法知道数据到底是什么样子,怎么能去分析数据呢。所以,咱们先把火锅团购数据数据读进来,看看火锅团购数据到底都包含了哪些信息。
在数据读入之前,工作路径的设置尤为重要,就像我要想吃火锅,要知道地址一样。这个叫“Python”的人,要去找到“数据”这个火锅,这是后面我们能做一系列研究的基础。所以,先来介绍设置工作路径的方法。
import os
os.getcwd()
os.chdir('XXXXX')
os.getcwd()
例1-1
这里os是python的标准库,import可理解为加载,这样就加载了os库。os.getcwd()查看现在的工作目录。其结果会显示当前的工作目录。不同的数据科学项目应该都存储于不同目录,所以这时候就需要我们根据数据文件的位置来设置自己的工作目录。命令os.chdir就是将工作目录更改成自己数据存放的位置的函数。最后当你设置完以后最好再利用os.getcwd()检查一下路径是否设置成功即可。
围绕着“火锅团购”会有来自团购、评论和店铺这三方面的数据。因此本书会主要使用三个后缀是.xlsx的文件。首先,comment_nm.xlsx这个数据集里记录了团购活动的评论数据。它包含用户对该活动评论的时间、内容、评分以及消费的门店等信息;其次,coupon_nm.xlsx这个数据集里记录了团购活动内容的数据。从这个数据集中可以了解到每个团购活动的举办的地址、店铺、团购内容、价位、团购的购买人数以及评价人数等信息;最后,shops_nm.xlsx这个数据集中记录了店铺的数据。从这个数据集可以更加详细的了解到每家门店的所在城市、具体地址、大众对它的评分、菜品以及该店铺的人均消费等数据。这三张数据表的信息整合后共同记录了每个团购活动的团购信息、大众对该活动的评价以及该团购活动举行的店铺数据。
数据介绍清楚了以后,接下来面临的问题是如何读入这些xlsx、csv等格式的数据呢。这里大家先“不求甚解”,记住会用一种叫做Pandas的Python模块中的函数读取。而对于Pandas的具体内容会在后面的章节有详细讲解。
import pandas as pd
coupon=pd.read_excel("https://github.com/xiangyuchang/xiangyuchang.github.io/blob/master/BearData/coupon_nm.xlsx?raw=true")
coupon.head()
例2-1
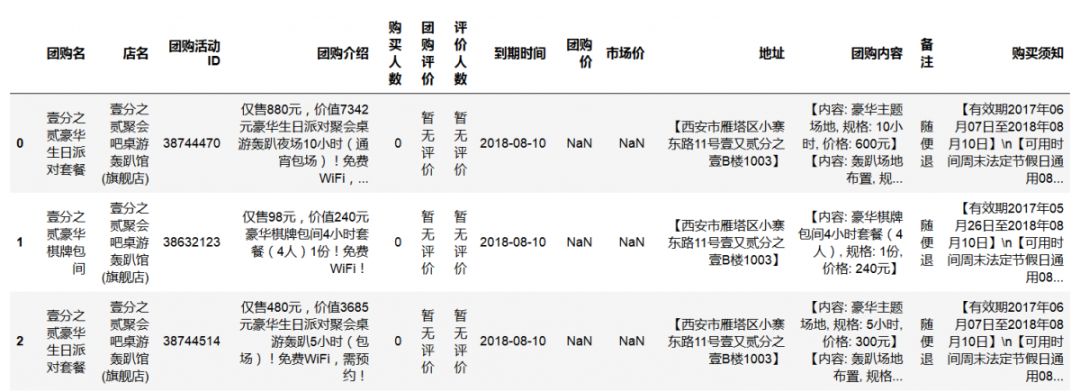
图2-1
从这份数据可以观察到每个团购举行的店铺,内容介绍,购买人数,评价人数,价格,地址等信息。如果coupo是csv文件,也可很方便的读入。注意这里的编码方式是'gbk'。
import pandas as pd
coupon_nm=pd.read_csv("https://github.com/xiangyuchang/xiangyuchang.github.io/blob/master/BearData/coupon_nm.csv?raw=true",encoding='gbk')
coupon_nm.head()
例2-2
图2-2
虽然火锅数据是读进来了,但是这些都是后缀是xlsx或者csv的数据文件。这时候有的读者会说其他存储类型的数据如何读取呢?下面来介绍Python中对于txt文件的读写,常常用的内置函数。
Open是Python中的内置函数,其正确的使用逻辑是:打开文件;读取文件内容;关闭文件。注意:文件使用完毕之后一般需要关闭。因为文件对象会占用系统资源,并且操作系统在同一时间内能够打开的文件数量有限。Open函数使用的基本语法为:
f = open(, )
其中,打开模式用于控制使用何种方式打开文件。Open函数提供了7种基本的打开模式,如下表。
表 3-1

下面利用Open函数新建一个名为food的txt文件,然后写入所需要的内容。
f = open("food.txt", "w")
f.write("西安火锅真棒。\n我喜欢西安的火锅!!\n")
f.close()
例3-1
这样就会在工作目录下发现有一个food.txt文件,并且利用了f.write函数在新建的food.txt文件中写入了两行话,分别是“西安火锅真棒”,“我喜欢西安的火锅!!”。如图3-1:

图3-1
最后利用f.close把文件关闭。在这个过程中,读者需要注意如果food文件在目录中存在了,这个时候如果我们还以“w”的模式打开,那么原来文件中的内容会被清空。Python还有很多文件读取的方法,这里就先不一一赘述了。等到需要用的时候将会仔细讲解。
作业:当然是赶紧把运行代码把数据下载下来,读入到自己的Jupyter Notebook中熟悉一下火锅团购数据(鼓励去吃一顿)。后面的所有讲解都需要用到这个数据哦。









