
本文约2600字,建议阅读5分钟。
如何利用网络上的公开数据构建一个自己的股票证券知识图谱呢?
[ 导读 ]你不理财财不理你,理财是大家早就达成共识的事情。作为新时代的五好青年,又身具机器学习、深度学习、知识图谱的能力,以自己的专业知识创造财富,应该更有意思。但是,股票证券市场信息繁杂,如何利用网络上的公开数据构建一个自己的股票证券知识图谱呢?GitHub的lemonhu同学,开源了一套解决方案。
github地址:
https://github.com/lemonhu/stock-knowledge-graph
作者:lemonhu
结果预览
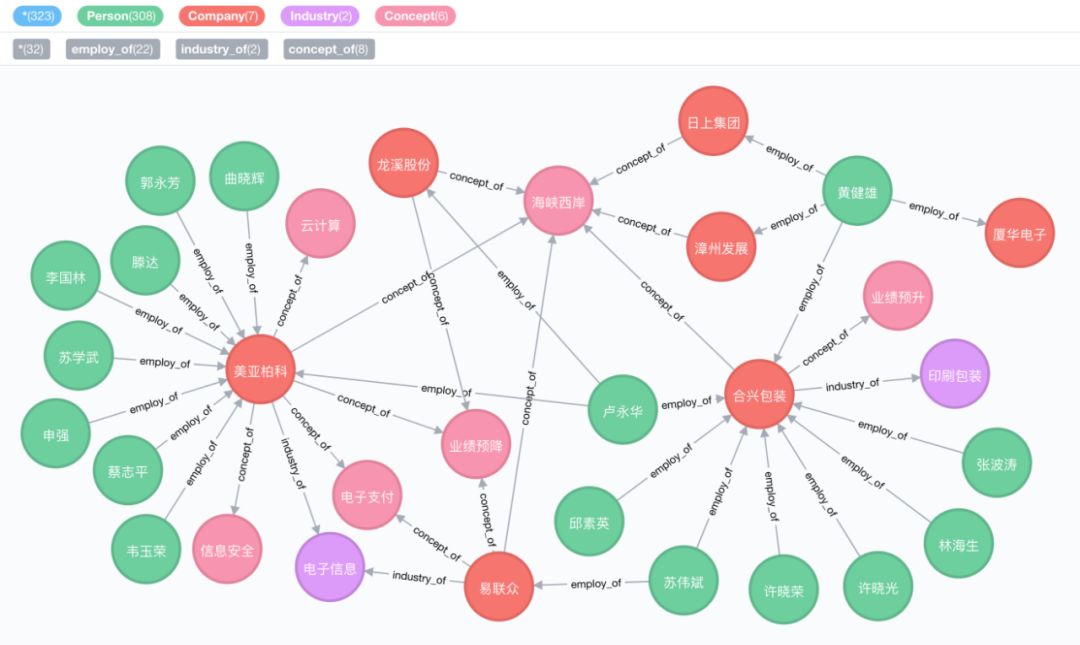
数据源
本项目需要用到两种数据源:一种是公司董事信息,另一种是股票的行业以及概念信息。
公司董事信息
这部分数据包含在data目录下的stockpage压缩文件中,⾥面的每一个文件是以XXXXXX.html命名,其中XXXXXX是股票代码。这部分数据是由同花顺个股的⽹页爬取而来的,执行解压缩命令unzip stockpage.zip即可获取。比如对于600007.html,这部分内容来自于:http://stockpage.10jqka.com.cn/600007/company/#manager
股票行业以及概念信息
这部分信息也可以通过⽹上公开的信息得到。在这里,我们使用Tushare工具来获得,详细细节见之后具体的任务部分。
从⽹页中抽取董事会的信息
在我们给定的html文件中,需要对每一个股票/公司抽取董事会成员的信息,这部分信息包括董事会成员“姓名”、“职务”、“性别”、“年龄”共四个字段。首先,姓名和职务的字段来自于:
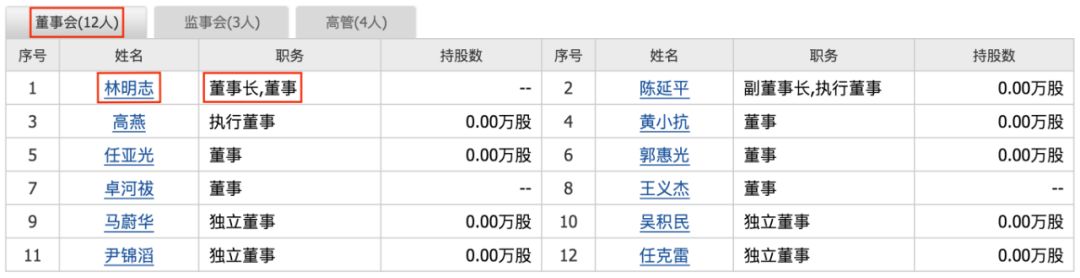
在这里总共有12位董事成员的信息,都需要抽取出来。另外,性别和年龄字段也可以从下附图里抽取出来:
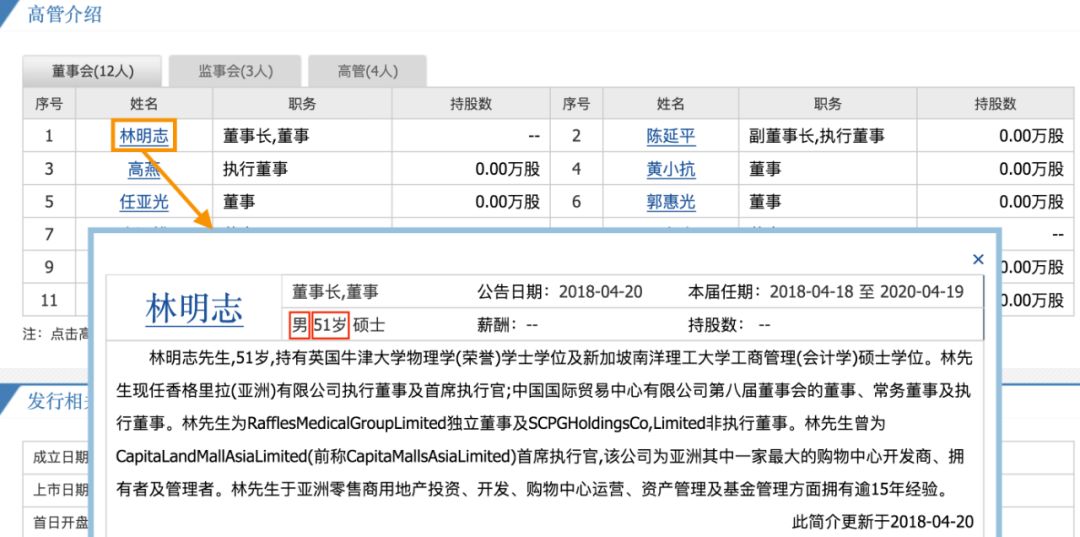
最后,生成一个 executive_prep.csv文件,格式如下:
| 高管姓名 | 性别 | 年龄 | 股票代码 | 职位 |
|---|
| 朴明志 | 男 | 51 | 600007 | 董事⻓/董事 |
| 高燕 | 女 | 60 | 600007 | 执⾏董事 |
| 刘永政 | 男 | 50 | 600008 | 董事⻓/董事 |
| ··· | ··· | ··· | ··· | ··· |
注:建议表头最好用相应的英文表示。
获取股票行业和概念的信息
对于这部分信息,我们可以利⽤工具Tushare来获取,官网为http://tushare.org/ ,使用pip命令进行安装即可。下载完之后,在python里即可调用股票行业和概念信息。
参考链接:
http://tushare.org/classifying.html#id2
通过以下的代码获得股票行业信息,并把返回的信息直接存储在stock_industry_prep.csv文件里。

类似的,可以通过以下代码即可获得股票概念信息,并把它们存储在stock_concept_prep.csv文件里。

设计知识图谱
设计一个这样的图谱:
把设计图存储为design.png文件。
注:实体名字和关系名字需要易懂,对于上述的要求,并不一定存在唯一的设计,只要能够覆盖上面这些要求即可。“ST”标记是用来刻画⼀个股票严重亏损的状态,这个可以从给定的股票名字前缀来判断,背景知识可参考百科ST股票,“ST”股票对应列表为['*ST', 'ST', 'S*ST', 'SST']。
创建可以导⼊Neo4j的csv文件
在前两个任务里,我们已经分别生成了 executive_prep.csv, stock_industry_prep.csv, stock_concept_prep.csv,但这些文件不能直接导入到Neo4j数据库。
所以需要做⼀些处理,并生成能够直接导入Neo4j的csv格式。我们需要生成这⼏个文件:
executive.csv, stock.csv, concept.csv, industry.csv, executive_stock.csv, stock_industry.csv, stock_concept.csv。
对于格式的要求,请参考:https://neo4j.com/docs/operations-manual/current/tutorial/import-tool/
利用上面的csv文件生成数据库

这个命令会把所有的数据导入到Neo4j中,数据默认存放在 graph.db 文件夹里。如果graph.db文件夹之前已经有数据存在,则可以选择先删除再执行命令。
把Neo4j服务重启之后,就可以通过localhost:7474观察到知识图谱了。
查询分析
基于构建好的知识图谱,通过编写Cypher语句回答如下问题:
请提供对应的Cypher语句以及答案,并把结果写在result.txt。
实施问题
构建人的实体时,重名问题具体怎么解决?
把简单思路写在result.txt文件中。
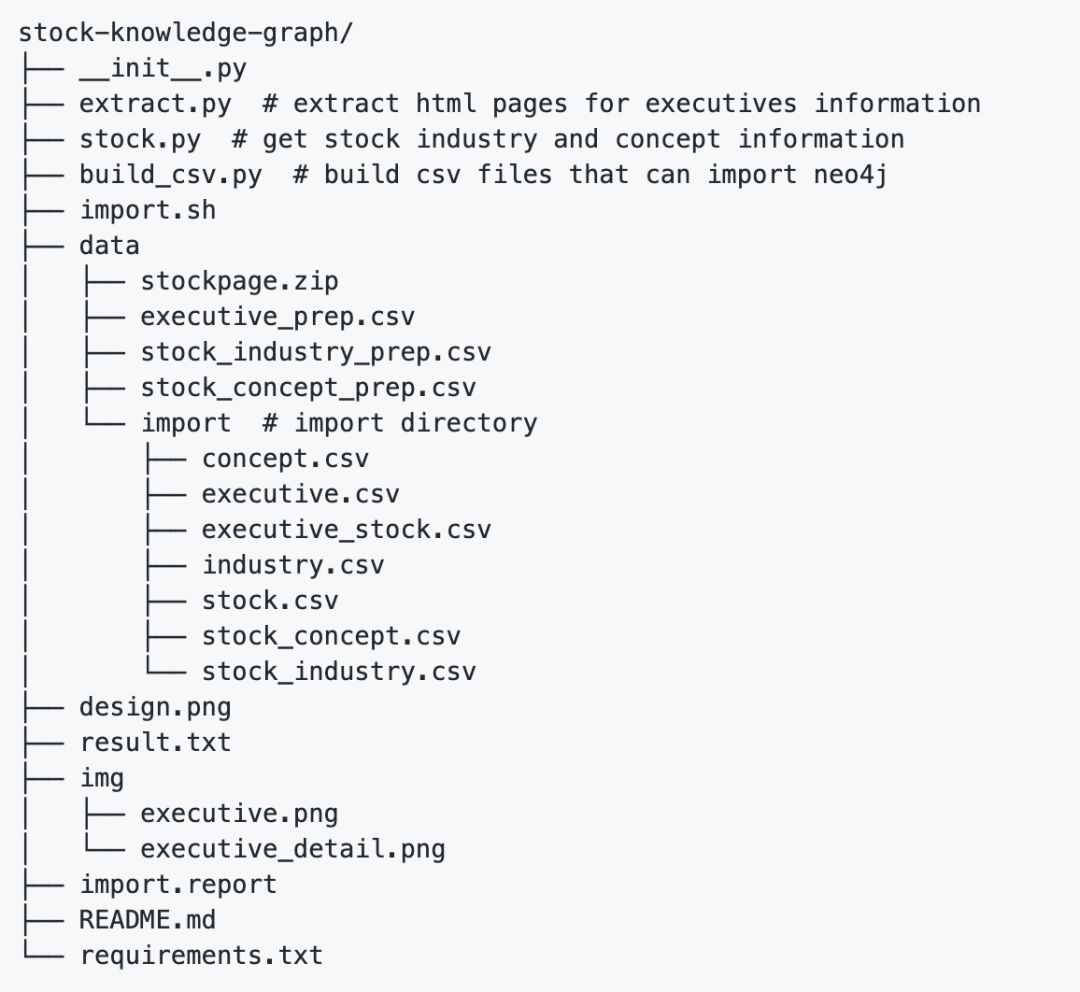
工程目录
编辑:王菁
校对:洪舒越










