
标星★公众号 爱你们♥
作者:George Seif、Thomas Wolf、Lukas Frei
编译:1+1=6 | 公众号海外部
近期原创文章:

你可能经常会一次又一次地听到关于Python的抱怨,Python跑起来太慢了!
与许多其他编程语言相比,Python的确很慢。
有几种不同的方法可以使代码提速:
如果你的代码是纯Python。如果你有一个很大的for循环,你只能使用它,而不能放入矩阵中,因为数据必须按顺序处理,那该怎么办?有没有办法加快Python本身的速度?
来吧,看看Cython!

文末下载Cython相关书籍
Cython的核心是Python和C / C++之间的一个中间步骤。它允许N你编写纯Python代码,只需要做一些小修改,然后将其直接翻译成C代码。
Cython 语言是 Python 的一个超集,它包含有两种类型的对象:
你对Python代码所做的唯一调整就是向每个变量添加类型信息。通常,我们可以像这样在Python中声明一个变量:
使用Cython,我们为该变量添加一个类型:
这告诉Cython,变量是浮点数,就像我们在C中所做的一样。对于纯Python,变量的类型是动态确定的。Cython中类型的显式声明使其转为C代码成为可能,因为显式类型声明需要+。
有很多办法来测试、编译和发布 Cython 代码。Cython 甚至可以像 Python 一样直接用于 Jupyter Notebook 中。有很多办法来测试、编译和发布 Cython 代码。Cython 甚至可以像 Python 一样直接用于 Jupyter Notebook 中。
安装Cython只需要一行pip:
使用Cython需要安装C语言编译器,因此,安装过程会根据你当前的操作系统而有所不同。对于Linux,通常使用GNU C编译器(gncc)。对于Mac OS,你可以下载Xcode以获取gncc。而Windows 桌面系统下安装C编译器会更复杂。
使用 %load_ext Cython 指令在 Jupyter notebook 中加载 Cython 扩展。
然后通过指令 %%cython,我们就可以像 Python 一样在 Jupyter notebook 中使用 Cython。
如果在执行 Cython 代码的时候遇到了编译错误,请检查 Jupyter 终端的完整输出信息。
大多数情况下可能都是因为在 %%cython 之后遗漏了 -+ 标签(比如当你使用 spaCy Cython 接口时)。如果编译器报出了关于 Numpy 的错误,那就是遗漏了 import numpy。
如果你要在在IPython中使用Cython:
首先介绍一下IPython Magic命令。Magic命令以百分号开头,通常有2种类型:
首先运行下列语句引入Cython:
然后,当运行Cython代码时,我们需要加入以下Cython 代码:
然后就可以愉快地使用Cython了。
使用Cython时,变量和函数有两组不同的类型。
对于变量,我们有:
cdef int a, b, c
cdef char *s
cdef float x = 0.5 (single precision)
cdef double x = 63.4 (double precision)
cdef list names
cdef dict goals_for_each_play
cdef object card_deck
注意所有这些类型都来自C / C++ !
我们可以方便的向C代码传递和返回结果,Cython会自动为我们做相应的类型转化。
了解了Cython类型之后,我们就可以直接实现加速了!
我们要做的第一件事是设置Python代码基准:用于计算数字阶乘的for循环。原始Python代码如下:
def test(x):
y = 1
for i in range(x+1):
y *= i
return y
Cython的实现过程看起来非常相似。首先,确保Cython代码文件具有 .pyx 扩展名。这些文件将被 Cython 编译器编译成 C 或 C++ 文件,再进一步地被 C 编译器编译成字节码文件。
你也可以使用 pyximport 将一个 .pyx 文件直接加载到 Python 程序中:
import pyximport; pyximport.install()
import my_cython_module
你也可以将自己的 Cython 代码作为 Python 包构建,然后像正常的 Python 包一样将其导入或者发布。不过这种做法需要花费更多的时间,特别是你需要让 Cython 包能够在所有的平台上运行。如果你需要一个参考样例,不妨看看 spaCy 的安装脚本:
https://github.com/explosion/spaCy/blob/master/setup.py?source=post_page---------------------------
最终 Python 解释器将能够调用这些字节码文件。对代码本身的惟一更改是,我们已经声明了每个变量和函数的类型。
cpdef int test(int x):
cdef int y = 1
cdef int i
for i in
range(x+1):
y *= i
return y
注意函数有一个cpdef来确保我们可以从Python调用它。另外看看我们的循环变量 i 是如何具有类型的。你需要为函数中的所有变量设置类型,以便C编译器知道使用哪种类型!
接下来,创建一个 setup.py 文件,该文件将Cython代码编译为C代码:
from distutils.core import setup
from Cython.Build import cythonize
setup(ext_modules = cythonize('run_cython.pyx'))
并执行编译:
python setup.py build_ext --inplace
Boom!我们的C代码已经编译好,可以使用了!
你将看到,在Cython代码所在的文件夹中,拥有运行C代码所需的所有文件,包括 run_cython.c 文件。如果你感兴趣,可以查看一下Cython生成的C代码!
现在我们准备测试新的C代码!查看下面的代码,它将执行一个速度测试,将原始Python代码与Cython代码进行比较。
现在我们准备测试我们新的超快速C代码了!查看下面的代码,它执行速度测试以将原始Python代码与Cython代码进行比较。
import run_python
import run_cython
import time
number = 10
start = time.time()
run_python.test(number)
end = time.time()
py_time = end - start
print("Python time = {}".format(py_time))
start = time.time()
run_cython.test(number)
end = time.time()
cy_time = end - start
print("Cython time = {}".format(cy_time))
print("Speedup = {}".format(py_time / cy_time))
Cython可以让你在几乎所有原始Python代码上获得良好的加速,而不需要太多额外的工作。需要注意的关键是,循环次数越多,处理的数据越多,Cython可以提供的帮助就越多。

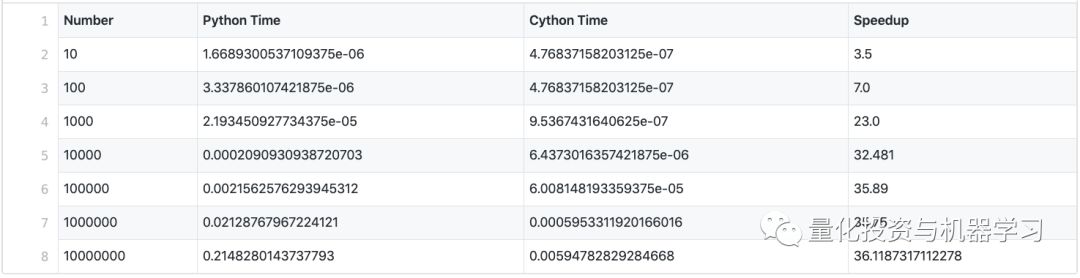
查看下表,该表显示了Cython为不同的阶乘值提供的速度我们使用Cython获得了超过 36倍 的加速!
当我们在操作字符串时,要如何在 Cython 中设计一个更加高效的循环呢?spaCy是个不错的选择!
spaCy 中所有的unicode字符串(the text of a token, its lower case text, its lemma form, POS tag label, parse tree dependency label, Named-Entity tags…)都被存储在一个称为 StringStore 的数据结构中,它通过一个64位哈希码进行索引,例如C类型的 uint64_t。

StringStore对象实现了Python unicode字符串与 64 位哈希码之前的查找映射。
它可以spaCy的任何地方和任意对象进行访问,例如 npl.vocab.strings、doc.vocab.strings 或者 span.doc.vocab.string。
当某模块需要在某些标记上获得更快的处理速度时,可以使用C语言类型的64位哈希码代替字符串来实现。调用StringStore查找表将返回与该哈希码相关联的Python unicode字符串。
但是spaCy能做的可不仅仅只有这些,它还允许我们访问文档和词汇表完全填充的C语言类型结构,我们可以在Cython循环中使用这些结构,而不必去构建自己的结构。
spaCy拓展:
https://spacy.io/api/cython?source=post_page---------------------------
建立一个脚本用于创建一个包含有 10 份文档的列表,每份文档都大概含有 17 万个单词,采用 spaCy 进行分析。当然我们也可以对 17 万份文档(每份文档包含 10 个单词)进行分析,但是这样做会导致创建的过程非常慢,所以我们还是选择了 10 份文档。
我们想要在这个数据集上展开某些自然语言处理任务。例如,我们可以统计数据集中单词「run」作为名词出现的次数(例如,被 spaCy 标记为「NN」词性标签)。
采用Python循环来实现上述分析过程非常简单和直观:
import urllib.request
import spacy
with urllib.request.urlopen('https://raw.githubusercontent.com/pytorch/examples/master/word_language_model/data/wikitext-2/valid.txt') as response:
text = response.read()
nlp = spacy.load('en')
doc_list = list(nlp(text[:800000].decode('utf8')) for i in range(10))
这段代码至少需要运行 1.4 秒才能获得答案。如果我们的数据集中包含有数以百万计的文档,为了获得答案,我们也许需要花费超过一天的时间。
我们也许能够采用多线程来实现加速,但是在Python中这种做法并不是那么明智,因为你还需要处理全局解释器锁(GIL)。在Cython中可以无视GIL的存在而尽情使用线程加速。但不能再使用Python中的字典和列表,因为Python中的变量都自动带了锁(GIL)。还好Cython已经封装了C++标准库中的容器:deque,list,map,pair,queue,set,stack,vector。完全可以替代Python的dict, list, set等。
我们使用Cython就可以解决这个,但不能再使用Python中的字典和列表,因为Python中的变量都自动带了锁(GIL)。还好Cython已经封装了C++标准库中的容器:deque,list,map,pair,queue,set,stack,vector。完全可以替代Python的dict, list, set等。
另外请注意,Cython也可以使用多线程!Cython在后台可以直接调用OpenMP。
https://cython.readthedocs.io/en/latest/src/userguide/parallelism.html?source=post_page---------------------------
现在让我们尝试使用spaCy和Cython来加速 Python 代码。
首先需要考虑好数据结构,我们需要一个C类型的数组来存储数据,需要指针来指向每个文档的 TokenC 数组。我们还需要将测试字符(「run」和「NN」)转成 64 位哈希码。
当所有需要处理的数据都变成了C类型对象,我们就可以以纯C语言的速度对数据集进行迭代。
以下是被转换成Cython和spaCy的实现:
%%cython -+
import numpy
from cymem.cymem cimport Pool
from spacy.tokens.doc cimport Doc
from spacy.typedefs cimport hash_t
from spacy.structs cimport TokenC
cdef struct DocElement:
TokenC* c
int length
cdef int fast_loop(DocElement* docs, int n_docs, hash_t word, hash_t tag):
cdef int n_out = 0
for doc in docs[:n_docs]:
for c in doc.c[:doc.length]:
if c.lex.lower == word and c.tag == tag:
n_out += 1
return n_out
def main_nlp_fast(doc_list):
cdef int i, n_out, n_docs = len(doc_list)
cdef Pool mem = Pool()
cdef DocElement* docs = mem.alloc(n_docs, sizeof(DocElement))
cdef Doc doc
for i, doc in enumerate(doc_list):
docs[i].c = doc.c
docs[i].length = (doc).length
word_hash = doc.vocab.strings.add('run')
tag_hash = doc.vocab.strings.add('NN')
n_out = fast_loop(docs, n_docs, word_hash, tag_hash)
在Jupyter notebook上,这段Cython代码运行了大概20毫秒,比之前的纯Python循环快了大概 80倍。
使用Jupyter notebook单元编写模块的速度很可观,它可以与其它 Python 模块和函数自然地连接:在 20 毫秒内扫描大约 170 万个单词,这意味着我们每秒能够处理高达 8 千万个单词。
如果你已经了解C语言,Cython还允许访问C代码,而Cython的创建者还没有为这些代码添加现成的声明。例如,使用以下代码,可以为C函数生成Python包装器并将其添加到模块dict中。
%%cython
cdef extern from "math.h":
cpdef double sin(double x)
1、.pyx中用CDEF定义的东西,除类以外对的.py都是不可见的。
2、.c中是不能操作C类型的,如果想在.py中操作C类型就要在.pyx中从python对象转成C类型或者用含有set / get方法的C类型包裹类。
3、虽然Cython能对Python的str和C的“char *”之间进行自动类型转换,但是对于“char a [n]”这种固定长度的字符串是无法自动转换的。需要使用Cython的libc.string .strcpy进行显式拷贝。
4、回调函数需要用函数包裹,再通过C的“void *”强制转换后才能传入C函数。
0、其他:

https://cython.org/?source=post_page---------------------------
1、官方文档:
2、参考书籍(文末下载):


Cython资料
—End—
量化投资与机器学习微信公众号,是业内垂直于Quant、MFE、CST、AI等专业的主流量化自媒体。公众号拥有来自公募、私募、券商、银行、海外等众多圈内10W+关注者。每日发布行业前沿研究成果和最新量化资讯。











