 机器学习时代的回测原则
机器学习时代的回测原则

文献来源:Arnott, Rob, Campbell R. Harvey, and Harry Markowitz. "A Backtesting Protocol in the Era of Machine Learning." The Journal of Financial Data Science(2019): jfds-2019.
推荐原因:在金融领域中,由于没有巨量的数据,在应用机器学习方法时很容易陷入过拟合中,本论文从七个维度给出了我们在实际中应用机器学习的原则和规程,以此来指导我们更好地避免模型过拟合。
在高频交易中,由于巨大的数据量,我们可以通过机器学习来获得较好的效果,但是在一些月频及更低频的金融数据上,数据挖掘很容易陷入过拟合,因此在我们实际应用机器学习技术进行金融数据挖掘时更应该遵循一些原则。
下图展示了一个长达50年美股上市值中性的多空对冲策略。该策略表现非常好:
1. 无论在1963~1988年的样本内测试,还是1989~2015年的样本外测试,该策略的表现都非常出色;
2. 该策略的表现在近期还是非常出色,显示并没有很多人模仿,因此这个“秘密”还相当管用;
3. 该因子能够穿越牛熊,在金融危机时甚至出现了上涨;
4. 该因子和其他主流因子(例如value, size, momentum等)之间的相关系数很低,从资产配置的角度,能够提高投资组合的风险调整后收益;
5. 该因子年换手率仅10%。
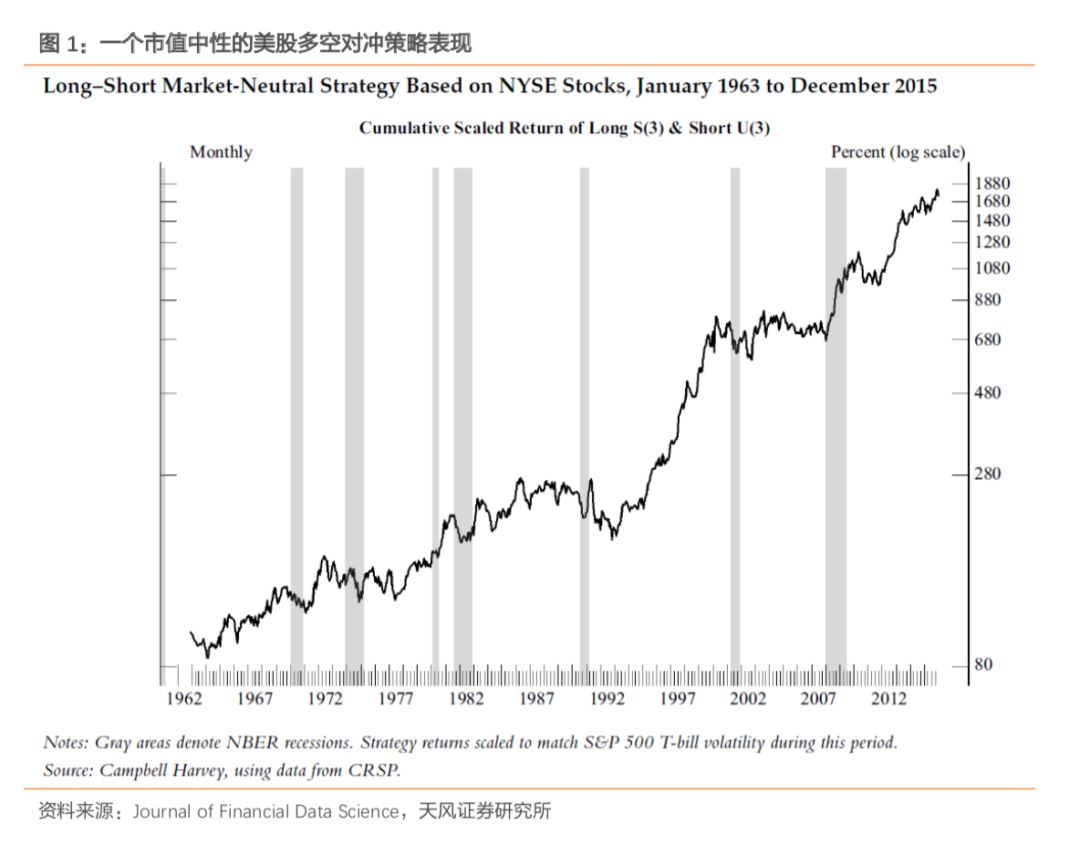
我们看到这样的投资策略,如果不了解其构建逻辑,可能已经迫不及待想要进行投资了。但事实上,该投资策略是数据挖掘的产物,其没有用到任何公司的基本面或技术面的信息,就是单纯买入美国股票代码前三个字母中含有S的股票,并且做空股票代码前三个字母中含有U的股票。
为什么买入首三个字母中带有S的股票,并且做空首三个字母中带有U的股票?原因在于,这是基于大数据机器学习的方法,在成千上万种不同的投资策略中,甄选出来的表现最好的策略之一。我们可以想象一下,我们不停地在英文字母中排列组合,只要可能的组合够多,即使完全源于运气,也可能找出几个看上去非常牛逼的投资策略。虽然该策略是暴力测试出来的,但是由于其历史回测的优良表现,大概率是能够通过交叉验证的。当数据量过少时,经济直觉就会更重要。所以在实际应用机器学习技术时,我们需要一些原则和规程来指导我们更好地避免过拟合。下面我们就从七个方面来逐一介绍。建立先验的理论假设:在物理学的研究中,实验物理学家通常都是不断实验测试数据来啊检验现有的理论,而理论物理学家则基于实验数据来构建更好的模型。这个过程一直采用的是科学方法:首先提出一个理论假设,通过实验来发现和理论不一致的地方,即可证伪性。
这样的一个理论假设能够为我们降低过拟合提供可能,并且它通常都有一个逻辑基础。上面的基于字母的选股就没有一个可靠的逻辑基础。
避免事后解释:在现实中,我们通常都会先看到数据再建立理论,例如上面的基于字母的选股模型,我们可能会自己编造一个理由来说服自己该策略是有效的。任何通过事后回看建立的理论都应该被非常谨慎地对待。
记录历史回测的样本及变量的组合:给定20个随机的选股策略,我们由于运气大概率能得到一个t值大于2的策略。因此在测试多个策略时,t值大于2并不是一个有效的评价指标。我们还需要跟踪记录有多少个类似的策略被回测过。
如果回测时有20个变量,并且回测带有部分变量之间的交互,例如变量1和变量2、变量1和变量3,那么实际的交互关系其实有190种,策略的显著性必须把所有的交互关系都考虑到其中。
注意平行空间问题:如果一个研究者开发了一个策略,并且只测试了一种变量下的结果,他相信一次的结果就可以通过t值为2来判定该策略是否显著。而实际上我们可以想象在平行空间中,另一个研究者实验了20次最后一次才拿到了一个好结果,那么实际上通过t值为2的标准来判定,其显著性是完全不够的。
事前定义数据:测试样本应该事前就确定好并且不能在回测开始后再修改。例如一个模型在1970年以后有效但是以1960年开始没有效,那么这个模型就没有用。
保证数据质量:脏数据会导致错误的结果,数据质量是后续算法的基础。
数据转换的方式:数据的缩放和标准化有时候是必要的,而其转换的方式必须要稳健,不能由于转换方式的微小变动导致结果不稳健。例如有10种缩放的方式,如果研究者选择了表现最好的一种,那么是很危险的。
细心处理异常值:异常值可能对于模型的干扰非常大。通常来说任何数据都不应该被删除,模型应该解释所有数据而不是选择部分数据。去极值的方法也要事前确定,不能出现压缩5%的效果好而压缩1%的效果就不好后就选择5%来压缩的情况。
样本外数据并不是真的样本外:所有的历史数据都是已经发生过的,都是样本内的数据。如果由于某一次样本内好而样本外不好就重新调整样本内外的数据结构,这就是在过拟合。
不可忽略的交易成本和手续费:基于所有学术论文都忽略了交易成本。
而在实际考虑交易成本后,很多模型在样本内外都失效了。
数据的时变性导致过拟合:在金融中,我们处理的不是物理常量,而是与人打交道,而人的偏好是会时变的。由于可获取的数据受限,对于时变的数据很容易导致过拟合。
谨记测不准原理:我们当前发现的市场历史上的无效性可能由于我们的发现及交易导致其在未来变为无效。
克制调整模型的冲动:每个模型都是靠概率取胜,如果一段时间内模型表现不好,我们经常会有不断调整模型来拟合市场近期表现的冲动,从而使模型变得过拟合。
小心维度爆炸:由于数据量受限,维度越高,模型的生命力越小。通过增加维度来提升样本内表现的做法,都会提高模型的复杂度,推升模型过拟合的风险。
追求简洁性:正则化是机器学习中的常用方法。越简单的模型在样本外的表现越不容易过拟合。
寻求可解释的机器学习方法:使用了机器学习算法的量化策略不应该是黑箱。
我们应该尽量了解这个算法的过程及其对结果的影响。
更注重研究的质量:在开发量化策略时,我们应该更注重研究的质量,而不是研究的结果。
小心委派的研究课题:没有人能够在各方面都精通,因此经常会有课题委托。而被委托的研究者通常都倾向于取悦他们的委托方,从而想办法来支持委托方的研究假设。这种倾向可能导致数据挖掘的比例过高从而导致策略在样本外没有好的表现。
在金融领域中,由于没有巨量的数据,在应用机器学习方法时很容易陷入过拟合中,本论文从七个维度给出了我们在实际中应用机器学习的原则和规程,以此来指导我们更好地避免模型过拟合。



风险提示:本报告内容基于相关文献,不构成投资建议。
注:文中报告节选自天风证券研究所已公开发布研究报告,具体报告内容及相关风险提示等详见完整版报告。
证券研究报告
《天风证券-金融工程:海外文献推荐 第97期》
对外发布时间
2019年7月31日(注:报告审核流程结束时间)
报告发布机构
天风证券股份有限公司
(已获中国证监会许可的证券投资咨询业务资格)
本报告分析师
吴先兴 SAC 执业证书编号:S1110516120001












