
向AI转型的程序员都关注了这个号👇👇👇
机器学习AI算法工程 公众号:datayx
这是Martin Zinkevich在NIPS 2016 Workshop 分享的谷歌机器学习实践的四十三条法则《Rules of Machine Learning:Best Practices for ML Engineering》
Martin Zinkevich google 研究科学家。
机器学习(ML)最优实践方法,浓缩了其多年技术积累与经验,尤其是YouTube、Google Play和Google+ 等平台背后的ML算法开发、维护经历。谷歌于白皮书中总结了四十三条ML黄金法则,旨在帮助已经掌握了基础知识的开发者少走弯路。
术语
实体(Instance):要对其进行预测的事物
标签(Label):预测任务的结果
特征:在预测任务中用到的实体的一个属性
特征集(feature Column):相关特征的一个集合
样例(Example):实体(及它的特征)和标签的集合
模型(Model):关于一个预测任务的一个统计表示。在样例中训练一个模型,然后用这个模型来预测
指标(metric):你关心的一些东西。有可能直接优化。
目标(Objective):你的算法尝试去优化的一个指标
工作流(pipeline):关于一个机器学习算法所有的基础构件。包括从前端收集数据,将数据输入训练数据文件,训练一个或者更多模型,以及将模型导出用于生产。
概述
要想创造出优秀的产品:
你需要以一位优秀工程师的身份去运用机器学习,而不是作为一位伟大的机器学习专家(而事实上你并不是)。
事实上,你所面临的大多数问题都是技术性问题。即便拥有足以媲美机器学习专家的理论知识。要想有所突破,大多数情况下都在依赖示例良好特征而非优秀的机器学习算法。因此,基本方法如下:
1.确保你的 工作流 各连接端十分可靠
2. 树立合理的目标
3. 添加的常识性特征尽量简单
4. 确保你的 工作流 始终可靠
这种方法能带来相当多的盈利,也能在较长时间里令许多人都满意,甚至还可能实现双赢。只有在简单技巧不发挥任何作用的情况下,才考虑使用复杂的一些的方法。方法越复杂,产品最终输出速度慢。
当所有的简单技巧用完后,很可能就要考虑最前沿机器学习术了。
本文档主要由四部分组成:
第一部分:帮助你明白是否到了需要构建一个机器学习系统
第二部分:部署你的第一个工作流
第三部分:往工作流增加新特征时的发布和迭代,以及如何评价模型和训练-服务倾斜(training-serving shew)
第四部分:达到稳定阶段后该继续做什么。
在机器学习之前
法则1:不用害怕发布一款没有用到机器学习的产品
机器学习很酷,但它需要数据。如果不是绝对需要机器学习,那在没有数据前,不要使用它。
法则2:将度量标准的设计和执行置于首位
在定义你的机器学习系统将要做什么前,尽可能的记录你当前的系统“足迹”。原因:
1、在早期,获得系统用户的许可相对容易.
2、如果你认为某些事在将来会重要,那么最好是从现在开始就收集历史数据
3、如果你设计系统时,就已经在心里有度量指标,那么将来一切就会更加的顺畅。特别是你肯定不想为了测量你的指标而需要在日志中执行grep。
4、你能够注意到什么改变了,什么没有变。比如,假如你想要直接优化每日活跃用户。但是,在你早期对系统的管理中,你可能注意到对用户体验的急剧改变,可能并不会明显的改变这个指标。
Google Plus团队测量“转发数”(expands per read)、分享数(reshares per read)、点赞数(plus-ones per read)、评论/阅读比(comments/read)、每个用户的评论数、每个用户的分享数等。这些用来在服务时间衡量一篇帖子的质量。同样,有一个能够将用户聚成组,并实验生成统计结果的实验框架很重要。见法则12
法则3:在机器学习和启发式方法中优先选择机器学习。
机器学习模型更好更新和更容易管理
机器学习阶段1:第一条工作流
认真对待第一条工作流的基础架构建设。虽然发挥想象力构思模型很有意思,但首先得确保你的工作流是可靠的,这样出了问题才容易发现。
法则4:第一个模型要简单,基础架构要正确。
第一个模型对你的产品提高最大,因此它不需要有多神奇。相反,你会碰到比你想象的多的基础架构方面的问题。在别人使用你的神奇的新机器学习系统前,你要决定:
1、如何为学习算法得到样本
2、对于你的系统,“好”、“坏”的定义是什么
3、如何在你的应用中融入你的模型。你可以在线应用你的模型,也可以在离线预先计算好模型,然后将结果保存到表中。比如,你可能想要预分类网页并将结果存入表,也有可能你想直接在线上分类聊天信息。
选择简单的特征,以能够更容易确保:
1、这些特征正确应用于学习算法
2、模型能够学习到合理的权重
3、这些特征正确应用于服务器模型。
你的系统如果能够可靠地遵守这三点,你就完成了大多数工作。你的简单模型能够提供基准指标和基准行为,你可以用来测量更加复杂的模型。
法则5:单独测试基础架构。
确保基础架构是可测试的。系统的学习部分独立封装,因此所有围绕它的都能测试。
法则6:复制工作流时留意丢失的数据
我们有时候会通过复制已经存在的工作流来创建一个新的工作流。在新的工作流中需要的数据,很可能在旧的数据流就丢弃了。比如,仅仅记录那些用户看到过的帖子的数据,那么,如果我们想要建模“为什么一篇特定的帖子没有被用户阅读”时,这些数据就没用了。
法则7:要么把启发式方法转化为特征,要么在外部处理它们
机器学习尝试解决的问题通常并不完全是新的。可以利用到很多已有的规则和启发式方法。当你调整机器学习时,这些相同的启发式方法能提供非常有用的帮助。
监控
一般来说,实施良好的警报监控,例如使警报可操作并具有报表页面。
法则8:了解系统的新鲜度要求
如果系统是一天前的,性能会降低多少?如果是一个星期前,或者1个季度前的呢?知道这些能够帮助你理解监控的优先级。如果模型一天未更新,你的收入会下降10%,那最好是有个工程师持续不断的关注。大多数广告服务系统每天都有新广告要处理,因此必须每日更新。有些需要频繁更新,有些又不需要,这因不同的应用和场景而定。此外,新鲜度也会因时间而异,特别是你的模型会增加或移除特征时。
法则9:导出(发布)你的模型前,务必检查各种问题
将模型导出部署到线上服务。如果这个时候,你的模型出了问题,这就是一个用户看到的问题。但如果是在之前出现问题,那就是一个训练问题,用户并不会发现。
在导出模型前务必进行完整性的检查。特别是要确保对留存的数据,你的模型能够满足性能。如果对数据感觉有问题,就不用导出模型!很多持续部署模型的团队都会在导出前检测AUC。模型问题出现在导出前,会收到警告邮件,但如果模型问题让用户碰到,就可能需要一纸辞退信了。因此,在影响用户前,最好先等一等,有确定把握后,在导出。
法则10:注意隐藏性失败
相对其他类型的系统,机器学习系统出现这种问题的可能性更高。比如关联的某张表不再更新。虽然机器学习还是会照样调整,行为还是表现的很合适,但已经在逐渐衰落。有时候发现了那些已经数月没有更新的表,那这个时候,一个简单的更新要比其他任何改变都能更好的提高性能。比如,由于实现的改变,一个特征的覆盖率会变:比如,开始覆盖90%的样本,突然只能覆盖60%了。google Play做过一个实验,有张表6个月一直不变,仅仅是对这个表更新,就在安装率方面提高了2%。跟踪数据的统计,并且在必要的时候人工检查,你就可以减少这样的错误。
法则11:给特征指定作者和文档
如果系统很大,有很多的特征,务必要知道每个特征的创建者或者管理者。如果理解特征的人要离职,务必确保有其他人理解这个特征。尽管很多的特征的名字已基本描述了特征的意义,但对特征有更新详细的描述,比如,它的来源以及其他它能提供什么帮助等,那就更好了。
你的第一个目标
对于你的系统,你有很多关心的指标。但对于你的机器学习算法,通常你需要一个单一目标——你的算法“尝试”去优化的数字。指标和目标的区别是:指标是你的系统报告的任何数字。这可能重要,也可能不重要。
法则12:不要过分思考你选择直接优化的目标
你有成千上万关心的指标,这些指标也值得你去测试。但是,在机器学习过程的早期,你会发现,即使你并没有直接去优化,他们也都会上升。比如,你关心点击次数,停留时间以及每日活跃用户数。如果仅优化了点击次数,通常也会看到停留时间增加了。
所以,当提高所有的指标都不难的时候,就没必要花心思来如何权衡不同的指标。不过过犹不及:不要混淆了你的目标和系统的整体健康度。
法则13:为你的第一个目标选择一个简单、可观察以及可归因的指标
有时候你自以为你清楚真实的目标,但随着你对数据的观察,对老系统和新的机器学习系统的分析,你会发现你又想要调整。而且,不同的团队成员对于真实目标并不能达成一致。机器学习的目标必须是能很容易测量的,并且一定是“真实”目标的代言。因此,在简单的机器学习目标上训练,并创建一个“决策层”,以允许你在上面增加额外的逻辑(这些逻辑,越简单越好)来形成最后的排序。
最容易建模的是那些可以直接观察并可归属到系统的某个动作的用户行为:
1.排序的链接被点击了吗?
2.排序的物品被下载了吗?
3.排序的物品被转发/回复/邮件订阅了吗?
4.排序的物品被评价了吗?
5.展示的物品是否被标注为垃圾/色情/暴力?
最开始要避免对间接效果建模:
1.用户第2天会来访吗?
2.用户访问时间是多长?
3.每日活跃用户是什么样的?
间接效果是非常重要的指标,在A/B test和发布决定的时候可以使用。
最后,不要试图让机器学习来回答以下问题:
1.用户使用你的产品是否开心
2.用户是否有满意的体验
3.产品是否提高了用户的整体幸福感
4.这些是否影响了公司的整体健康度
这些都很重要,但太难评估了。与其如此,不如考虑其他代替的:比如,用户如果高兴,那停留时间就应该更长。如果用户满意,他就会再次造访。
法则14:从一个可解释的模型开始,使调试更容易。
线性回归,逻辑回归和泊松回归直接由概率模型激发。每个预测可解释为概率或期望值。这使得他们比那些使用目标来直接优化分类准确性和排序性能的模型要更容易调试。比如,如果训练时的概率和预测时的概率,或者生产系统上的查看到的概率有偏差,那说明存在某种问题。
比如在线性,逻辑或者泊松回归中,存在数据子集,其中平均预测期望等于平均标记(1-力矩校准或刚刚校准)。如果有一个特征对于每个样例,取值要么为1,有么为0,那为1的那些样例就是校准的。同样,如如果都为1,那所有样例都是校准的。
通常我们会使用这些概率预测来做决策:比如,按期望值(比如,点击/下载等的概率)对贴排序。但是,要记住,当到了要决定选择使用哪个模型的时候,决策就不仅仅是关于提供给模型的数据的概率性了。
法则15:在决策层区分垃圾过滤和质量排名
质量排名是一门艺术,而垃圾过滤是一场战争。那些使用你系统的人非常清楚你采用什么来评价一篇帖子的质量,所以他们会想尽办法来使得他们的帖子具有这些属性。因此,质量排序应该关注对哪些诚实发布的内容进行排序。如果将垃圾邮件排高名次,那质量排序学习器就大打折扣。同理也要将粗俗的内容从质量排序中拿出分开处理。垃圾过滤就是另外一回事。你必须考虑到要生成的特征会经常性的改变。你会输入很多明显的规则到系统中。至少要保证你的模型是每日更新的。同时,要重点考虑内容创建者的信誉问题。
机器学习阶段二:特征工程
将训练数据导入学习系统、完成相关感兴趣指标的评估记录以及搭建服务架构,这些都是机器学习系统生命周期的第一阶段非常重要的任务。当已经具有一个可工作的端对端系统,并且构建了单元测试和系统测试,那么,就进入阶段二了。
在第二阶段,有很多可以很容易就取得的成果。有很多明显能加入系统的特征。因此,在机器学习的第二阶段会涉及到导入尽可能多的特征,并且以最直观地方式组合它们。在此阶段,所有指标应该仍然在上升。将会经常性的发版。这将是一个伟大的时刻,在这个阶段能够吸引很多的工程师来融合所有想要的数据来创建一个了不起的学习系统
法则16:做好发布和迭代的计划
不要期望现在发布的这个模型是最后。因此,考虑你给当前这个模型增加的复杂度会不会减慢后续的发布。很多团队一个季度,甚至很多年才发布一个模型。以下是应该发布新模型的三个基本原因:
1.会不断出现新的特征
2..您正在以新的方式调整规则化和组合旧特征,或者
3.你正在调整目标。
无论如何,对一个模型多点投入总是好的:看看数据反馈示例可以帮助找到新的、旧的以及坏的信号。因此,当你构建你的模型时,想想添加,删除或重组特征是不是很容易。想想创建工作流的新副本并验证其正确性是不是很容易。考虑是否可能有两个或三个副本并行运行。最后,不要担心35的特征16是否会进入此版本的工作流(Finally,don't worry about whether feature 16 of 35 makes it into this version of the pipeline.)。这些,你都会在下个季度得到。
法则17:优先考虑哪些直接观察到和可记录的特征,而不是那些习得的特征。
首先,什么是习得特征?所谓习得特征,就是指外部系统(比如一个无监督聚类系统)生成的特征,或者是学习器自己生成的特征(比如,通过分解模型或者深度学习)。这些特征都有用,但涉及到太多问题,因此不建议在第一个模型中使用。
如果你使用外部系统来创建一个特征,切记这个系统本身是有自己目标的。而它的目标很可能和你目前的目标不相关。这个外部系统可能已经过时了。如果你从外部 系统更新特征,很可能这个特征的含义已经改变。使用外部系统提供的特征,一定要多加小心。
分解模型和深度学习模型最主要的问题是它们是非凸的。因此不能找到最优解,每次迭代找到的局部最小都不同。这种不同让人很难判断一个对系统的影响到底是有意义的,还是只是随机的。一个没有深奥特征的模型能够带来非常好的基准性能。只有当这个基准实现后,才考虑更深奥的方法。
法则18:从不同的上下文环境中提取特征
通常情况下,机器学习只占到一个大系统中的很小一部分,因此你必须要试着从不同角度审视一个用户行为。比如热门推荐这一场景,一般情况下论坛里“热门推荐”里的帖子都会有许多评论、分享和阅读量,如果利用这些统计数据对模型展开训练,然后对一个新帖子进行优化,就有可能使其成为热门帖子。另一方面,YouTube上自动播放的下一个视频也有许多选择,例如可以根据大部分用户的观看顺序推荐,或者根据用户评分推荐等。总之,如果你将一个用户行为用作模型的标记(label),那么在不同的上下文条件下审视这一行为,可能会得到更丰富的特征(feature),也就更利于模型的训练。需要注意的是这与个性化不同:个性化是确定用户是否在特定的上下文环境中喜欢某一内容,并发现哪些用户喜欢,喜欢的程度如何。
法则19:尽量选择更具体的特征
在海量数据的支持下,即使学习数百万个简单的特征也比仅仅学习几个复杂的特征要容易实现。由于被检索的文本标识与规范化的查询并不会提供太多的归一化信息,只会调整头部查询中的标记排序。因此你不必担心虽然整体的数据覆盖率高达90%以上,但针对每个特征组里的单一特征却没有多少训练数据可用的情况。另外,你也可以尝试正则化的方法来增加每个特征所对应的样例数。
法则20:以合理的方式组合、修改现有的特征
有很多组合和修改特征的方式。类似TensorFlow的机器学习系统能够通过‘transformations’(转换)来预处理数据。最基本的两种方式是:“离散化”(discretizations)和“交叉”(crosses)
离散化:将一个值为连续的特征拆分成很多独立的特征。比如年龄,1~18作为1个特征,18~35作为1个特征等等。不要过分考虑边界,通常基本的分位点就能达到最好。
交叉:合并多个特征。在TensorFlow的术语中,特征栏是一组相似的特征,比如{男性,女性},{美国,加拿大,墨西哥}等。这里的交叉是指将两个或多个特征栏合并,例如{男性,女性}×{美国,加拿大,墨西哥}的结果就是一个交叉(a cross),也就构成了一个新的特征栏。假设你利用TensorFlow框架创建了这样一个交叉,其中也就包含了{男性,加拿大}的特征,因此这一特征也就会出现在男性加拿大人的样例中。需要注意的是,交叉方法中合并的特征栏越多,所需要的训练数据量就越大。
如果通过交叉法生成的特征栏特别庞大,那么就可能引起过拟合。
例如,假设你正在进行某种搜索,并且在查询请求和文档中都具有一个包含关键字的特征栏。那么假如你选择用交叉法组合这两个特征栏,这样得到的新特征栏就会非常庞大,它内部包含了许多特征。当这种情况发生在文本搜索场景时,有两种可行的应对方法。最常用的是点乘法(dot product),点乘法最常见的处理方式就是统计查询请求和文档中共同的所有特征词,然后对特征离散化。另一个方法是交集(intersection),比如当且仅当关键词同时出现在文档和查询结果中时,我们才能获取所需的特征。
法则21:通过线性模型学到的特征权重的数目,大致与数据量成正比
许多人都认为从一千个样例中并不能得到什么可靠的训练结果,或者由于选择了某种特定的模型,就必须获取一百万个样例,否则就没法展开模型训练。这里需要指出的是,数据量的大小是和需要训练的特征数正相关的:
1) 假如你在处理一个搜索排名问题,文档和查询请求中包含了数百万个不同的关键词,并且有一千个被标记的样例,那么你应该用上文提到的点乘法处理这些特征。这样就能得到一千个样例,对应了十几个特征。
2) 如你有一百万个样例,那么通过正则化和特征选择的方式就可以交叉处理文档和查询请求中的特征栏,这可能会产生数百万的特征数,但再次使用正则化可以大大减少冗余特征。这样就可能得到一千万个样例,对应了十万个特征。
3) 如果你有数十亿或数百亿个样例,那同样可以通过特征选择或正则化的方法交叉处理文档和查询请求中的特征栏。这样就可能得到十亿个样例,对应了一千万个特征。
法则22:清理不再需要的特征
不再使用的特征,在技术上就是一个累赘。如果一个特征不再使用,并且也没办法和其他的特征组合,那就清理掉!你必须确保系统清洁,以满足能尽可能快的尝试最有希望得出结果的特征。对于那些清理掉的,如果有天需要,也可以再加回来。
至于保持和添加什么特征,权衡的一个重要指标是覆盖率。比如,如果某些特征只覆盖了8%的用户,那保留还是不保留都不会带来什么影响。
另一方面,增删特征时也要考虑其对应的数据量。例如你有一个只覆盖了1%数据的特征,但有90%的包含这一特征的样例都通过了训练,那么这就是一个很好的特征,应该添加。
对系统的人工分析
在进入机器学习第三阶段前,有一些在机器学习课程上学习不到的内容也非常值得关注:如何检测一个模型并改进它。这与其说是门科学,还不如说是一门艺术。这里再介绍几种要避免的反模式(anti-patterns)
法则23:你并不是一个典型的终端用户
这可能是让一个团队陷入困境的最简单的方法。虽然fishfooding(只在团队内部使用原型)和dogfooding(只在公司内部使用原型)都有许多优点,但无论哪一种,开发者都应该首先确认这种方式是否符合性能要求。要避免使用一个明显不好的改变,同时,任何看起来合理的产品策略也应该进一步的测试,不管是通过让非专业人士来回答问题,还是通过一个队真实用户的线上实验。这样做的原因主要有两点:
首先,你离实现的代码太近了。你只会看到帖子的特定的一面,或者你很容易受到情感影响(比如,认知性偏差)。
其次,作为开发工程师,时间太宝贵。并且有时候还没什么效果。
如果你真的想要获取用户反馈,那么应该采用用户体验法(user experience methodologies)。在流程早期创建用户角色(详情见Bill Buxton的《Designing User ExperienCES》一书),然后进行可用性测试(详情见Steve Krug的《Do not Make Me Think》一书)。这里的用户角色涉及创建假想用户。例如,如果你的团队都是男性,那设计一个35岁的女性用户角色所带来的效果要比设计几个25~40岁的男性用户的效果强很多。当然,让用户实测产品并观察他们的反应也是很不错的方法。
法则24:测量模型间的差异
在将你的模型发布上线前,一个最简单,有时也是最有效的测试是比较你当前的模型和已经交付的模型生产的结果之间的差异。如果差异很小,那不再需要做实验,你也知道你这个模型不会带来什么改变。如果差异很大,那就要继续确定这种改变是不是好的。检查对等差分很大的查询能帮助理解改变的性质(是变好,还是变坏)。但是,前提是一定要确保你的系统是稳定的。确保一个模型和它本身比较,这个差异很小(理想情况应该是无任何差异)。
法则25:选择模型的时候,实用的性能要比预测能力更重要
你可能会用你的模型来预测点击率(CTR)。当最终的关键问题是你要使用你的预测的场景。如果你用来对文本排序,那最终排序的质量可不仅仅是预测本身。如果你用来排查垃圾文件,那预测的精度显然更重要。大多数情况下,这两类功能应该是一致的,如果他们存在不一致,则意味着系统可能存在某种小增益。因此,假如一个改进措施可以解决日志丢失的问题,但却造成了系统性能的下降,那就不要采用它。当这种情况频繁发生时,通常应该重新审视你的建模目标。
法则26:从误差中查找新模式、创建新特征
假设你的模型在某个样例中预测错误。在分类任务中,这可能是误报或漏报。在排名任务中,这可能是一个正向判断弱于逆向判断的组。但更重要的是,在这个样例中机器学习系统知道它错了,需要修正。如果你此时给模型一个允许它修复的特征,那么模型将尝试自行修复这个错误。
另一方面,如果你尝试基于未出错的样例创建特征,那么该特征将很可能被系统忽略。例如,假设在谷歌Play商店的应用搜索中,有人搜索“免费游戏”,但其中一个排名靠前的搜索结果却是一款其他App,所以你为其他App创建了一个特征。但如果你将其他App的安装数最大化,即人们在搜索免费游戏时安装了其他App,那么这个其他App的特征就不会产生其应有的效果。
所以,正确的做法是一旦出现样例错误,那么应该在当前的特征集之外寻找解决方案。例如,如果你的系统降低了内容较长的帖子的排名,那就应该普遍增加帖子的长度。而且也不要拘泥于太具体的细节。例如你要增加帖子的长度,就不要猜测长度的具体含义,而应该直接添加几个相关的特征,交给模型自行处理,这才是最简单有效的方法。
法则27:尝试量化观察到的异常行为
有时候团队成员会对一些没有被现有的损失函数覆盖的系统属性感到无能为力,但这时抱怨是没用的,而是应该尽一切努力将抱怨转换成实实在在的数字。比如,如果应用检索展示了太多的不好应用,那就应该考虑人工评审来识别这些应用。如果问题可以量化,接下来就可以将其用作特征、目标或者指标。总之,先量化,再优化
法则28:注意短期行为和长期行为的差别
假设你有一个新系统,它可以查看每个doc_id和exact_query,然后根据每个文档的每次查询行为计算其点击率。你发现它的行为几乎与当前系统的并行和A/B测试结果完全相同,而且它很简单,于是你启动了这个系统。却没有新的应用显示,为什么?由于你的系统只基于自己的历史查询记录显示文档,所以不知道应该显示一个新的文档。
要了解一个系统在长期行为中如何工作的唯一办法,就是让它只基于当前的模型数据展开训练。这一点非常困难。
离线训练和实际线上服务间的偏差
引起这种偏差的原因有:
1)训练工作流和服务工作流处理数据的方式不一样;
2)训练和服务使用的数据不同;
3)算法和模型间循的一个循环反馈。
法则29:确保训练和实际服务接近的最好方式是保存服务时间时使用到的那些特征,然后在后续的训练中采用这些特征
即使你不能对每个样例都这样做,做一小部分也比什么也不做好,这样你就可以验证服务和训练之间的一致性(见规则37)。在谷歌采取了这项措施的团队有时候会对其效果感到惊讶。比如YouTube主页在服务时会切换到日志记录特征,这不仅大大提高了服务质量,而且减少了代码复杂度。目前有许多团队都已经在其基础设施上采用了这种策略。
法则30:给抽样数据按重要性赋权重,不要随意丢弃它们
当数据太多的时候,总会忍不住想要丢弃一些,以减轻负担。这绝对是个错误。有好几个团队就因为这样,而引起了不少问题(见规则6)。尽管那些从来没有展示给用户的数据的确可以丢弃,但对于其他的数据,最好还是对重要性赋权。比如如果你绝对以30%的概率对样例X抽样,那最后给它一个10/3的权重。使用重要性加权并不影响规则14中讨论的校准属性。
法则31:注意在训练和服务时都会使用的表中的数据是可能变化的
因为表中的特征可能会改变,在训练时和服务时的值不一样,这会造成,哪怕对于相同的文章,你的模型在训练时预测的结果和服务时预测的结果都会不一样。避免这类问题最简单的方式是在服务时将特征写入日志(参阅法则32)。如果表的数据变化的缓慢,你也可以通过每小时或者每天给表建快照的方式来保证尽可能接近的数据。但这也不能完全解决这种问题。
法则32:尽量在训练工作流和服务工作流间重用代码
首先需要明确一点:批处理和在线处理并不一样。在线处理中,你必须及时处理每一个请求(比如,必须为每个查询单独查找),而批处理,你可以合并完成。服务时,你要做的是在线处理,而训练是批处理任务。尽管如此,还是有很多可以重用代码的地方。比如说,你可以创建特定于系统的对象,其中的所有联结和查询结果都以人类可读的方式存储,错误也可以被简单地测试。然后,一旦在服务或训练期间收集了所有信息,你就可以通过一种通用方法在这个特定对象和机器学习系统需要的格式之间形成互通,训练和服务的偏差也得以消除。因此,尽量不要在训练时和服务时使用不同的变成语言,毕竟这样会让你没法重用代码。
法则33:训练采用的数据和测试采用的数据不同(比如,按时间上,如果你用1月5日前的所有的数据训练,那测试数据应该用1月6日及之后的)
通常,在评测你的模型的时候,采用你训练时用的数据之后生成的数据能更好反映实际线上的结果。因为可能存在每日效应(daily effects),你可能没有预测实际的点击率和转化率。但AUC应该是接近的。
法则34:在二进制分类过滤的应用场景中(例如垃圾邮件检测),不要为了纯净的数据做太大的性能牺牲
一般在过滤应用场景中,反面样例并不会对用户展示。不过假如你的过滤器在服务过程中阻止了75%的反面样例,那么你可能需要从向用户显示的实例中提取额外的训练数据并展开训练。比如说,用户将系统认可的邮件标记为垃圾邮件,那么你可能就需要从中学习。
但这种方法同时也引入了采样偏差。如果改为在服务期间将所有流量的1%标记为“暂停”,并将所有这样的样例发送给用户,那你就能收集更纯净的数据。现在你的过滤器阻止了至少74%的反面样例,这些样例可以成为训练数据。
需要注意的是,如果你的过滤器阻止了95%或更多的反面样例,那这种方法可能就不太适用。不过即使如此,如果你想衡量服务的性能,可以选择做出更细致的采样(例如0.1%或0.001%),一万个例子足以准确地估计性能。
法则35:注意排序问题的固有偏差
当你彻底改变排序算法时,一方面会引起完全不同的排序结果,另一方面也可能在很大程度上改变算法未来可能要处理的数据。这会引入一些固有偏差,因此你必须事先充分认识到这一点。以下这些方法可以有效帮你优化训练数据。
1.对涵盖更多查询的特征进行更高的正则化,而不是那些只覆盖单一查询的特征。这种方式使得模型更偏好那些针对个别查询的特征,而不是那些能够泛化到全部查询的特征。这种方式能够帮助阻止非常流行的结果进入不相关查询。这点和更传统的建议不一样,传统建议应该对更独特的特征集进行更高的正则化。
2.只允许特征具有正向权重,这样一来就能保证任何好特征都会比未知特征合适。
3.不要有那些仅仅偏文档(document-only)的特征。这是法则1的极端版本。比如,不管搜索请求是什么,即使一个给定的应用程序是当前的热门下载,你也不会想在所有地方都显示它。没有仅仅偏文档类特征,这会很容易实现。
法则36:避免具有位置特征的反馈回路
内容的位置会显著影响用户与它交互的可能性。很明显,如果你把一个App置顶,那它一定会更频繁地被点击。处理这类问题的一个有效方法是加入位置特征,即关于页面中的内容的位置特征。假如你用位置类特征训练模型,那模型就会更偏向“1st-position”这类的特征。因而对于那些“1st-position”是True的样例的其他因子(特征),你的模型会赋予更低的权重。而在服务的时候,你不会给任何实体位置特征,或者你会给他们所有相同的默认特征。因为在你决定按什么顺序排序展示前,你已经给定了候选集。
切记,将任何位置特征和模型的其他特征保持一定的分离是非常重要的。因为位置特征在训练和测试时不一样。理想的模型是位置特征函数和其他特征的函数的和。比如,不要将位置特征和文本特征交叉。
法则37:测量训练/服务偏差
很多情况会引起偏差。大致上分为一些几种:
1.训练数据和测试数据的性能之间的差异。一般来说,这总是存在的,但并不总是坏事。
2.测试数据和新时间生成数据之间的性能差异。同样,这也总是存在的。你应该调整正则化来最大化新时间数据上的性能。但是,如果这种性能差异很大,那可能说明采用了一些时间敏感性的特征,且模型的性能下降了。
3.新时间数据和线上数据上的性能差异。如果你将模型应用于训练数据的样例,也应用于相同的服务样例,则它们应该给出完全相同的结果(详见规则5)。因此,如果出现这个差异可能意味着出现了工程上的异常。
机器学习第三阶段
有一些信息暗示第二阶段已经结束。首先,月增长开始减弱。你开始要考虑在一些指标间权衡:在某些测试中,一些指标增长了,而有些却下降了。这将会变得越来越有趣。增长越来越难实现,必须要考虑更加复杂的机器学习。
警告:相对于前面两个阶段,这部分会有很多开放式的法则。第一阶段和第二阶段的机器学习总是快乐的。当到了第三阶段,团队就不能不去找到他们自己的途径了。
法则38:如果目标不协调,并成为问题,就不要在新特征上浪费时间
当达到度量瓶颈,你的团队开始关注 ML 系统目标范围之外的问题。如同之前提到的,如果产品目标没有包括在算法目标之内,你就得修改其中一个。比如说,你也许优化的是点击数、点赞或者下载量,但发布决策还是依赖于人类评估者。
法则39:模型发布决策是长期产品目标的代理
艾丽斯有一个降低安装预测逻辑损失的想法。她增加了一个特征,然后逻辑损失下降了。当线上测试的时候,她看到实际的安装率增加了。但当她召集发布复盘会议时,有人指出每日活跃用户数下降了5%。于是团队决定不发布该模型。艾丽斯很失望,但意识到发布决策依赖于多个指标,而仅仅只有一些是机器学习能够直接优化的。
真实的世界不是网络游戏:这里没有“攻击值”和“血量”来衡量你的产品的健康状况。团队只能靠收集统计数据来有效的预测系统在将来会如何。他们必须关心用户粘性、1 DAU,30 DAU,收入以及广告主的利益。这些 A/B 测试中的指标,实际上只是长期目标的代理:让用户满意、增加用户、让合作方满意还有利润;即便这时你还可以考虑高品质、有使用价值的产品的代理,以及五年后一个繁荣的企业的代理。
做出发布决策唯一容易的是当所有指标都变好的时候(或者至少没有变化)。当团队在复杂 ML 算法和简单启发式算法之间有选择时;如果简单的启发式算法在这些指标上做得更好;那么应当选择启发式。另外,所有指标数值并没有明确的孰重孰轻。考虑以下更具体的两种情形:
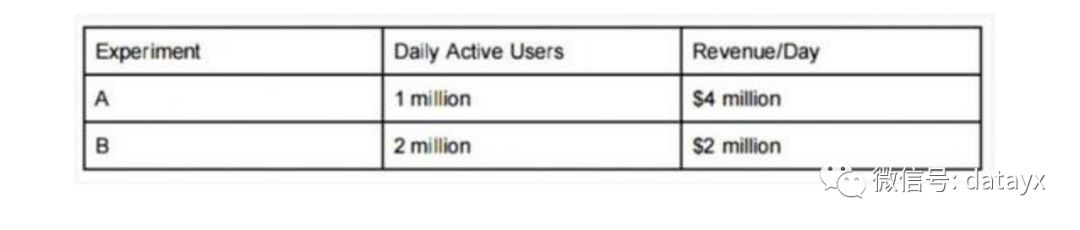
如果现有系统是 A ,团队不会想要转移到 B。如果现有系统是 B,团队也不会想要转到 A。这看起来与理性决策相抵触:但是,对指标变化的预期情形或许会发生,或许不会。因此任意一种改变都有相当大的风险。每一个指标覆盖了一些团队所关注的风险。但没有指标能覆盖团队的首要关切——“我的产品在五年后会怎样?”
另一方面,个体更倾向于那些他们能够直接优化的单一目标。大多数机器学习工具也如此。在这样的环境下,一个能够创造新特征的工程师总能够稳定的输出产品发布。有一种叫做多目标学习的机器学习类型开始处理这类问题。比如,给每个目标设定最低界限,然后优化指标的线性组合。但即便如此,也不是所有指标都能轻易表达为 ML 目标:如果一篇文章被点击了,或者一个app被安装了,这可能是只是因为这个内容被展示了。但要想搞清楚为什么一个用户访问你的网站就更难了。如何完整预测一个网站将来是否能成功是一个AI完全(AI-complete)问题。就和计算机视觉或者自然语言处理一样难。
法则40:保证集成模型(ensemble)的简洁
接收原始特征、直接对内容排序的统一模型,是最容易理解、最容易修补漏洞的模型。但是,一个集成模型(一个把其他模型得分组合在一起的“模型”)的效果会更好。为保持简洁,每个模型应该要么是一个只接收其他模型的输入的集成模型,要么是一个有多种特征的基础模型,但不能两者皆是。如果你有单独训练、基于其它模型的模型,把它们组合到一起会导致不好的行为。
只使用简单模型来集成那些仅仅把你的基础模型输出当做输入。你同样想要给这些集成模型加上属性。比如,基础模型生成得分的提高,不应该降低集成模型的分数。另外,如果连入模型在语义上可解释(比如校准了的)就最好了,这样其下层模型的改变不会影响集成模型。此外,强行让下层分类器预测的概率升高,不会降低集成模型的预测概率。
法则41:当碰到性能瓶颈,与其精炼已有的信息,不如寻找有质量的新信息源
你已经给用户增加了人工统计属性信息,给文本中的词增加了一些信息,经历了模板探索并且实施了正则化。然后,几乎有好几个季度你的关键指标都没有过提高超过1%了。现在该怎么办?
现在是到了为完全不同的特征(比如,用户昨天,上周或者去年访问过的文档,或者来自不同属性的数据)构建基础架构的时候了。为你的公司使用维基数据(wikidata)实体或者一些内部的东西(比如谷歌的知识图,Google’s knowledge graph)。你或许需要使用深度学习。开始调整你对投资回报的期望,并作出相应努力。如同所有工程项目,你需要平衡新增加的特征与提高的复杂度。
法则42:不要期望多样性、个性化、相关性和受欢迎程度之间有紧密联系
一系列内容的多样性能意味着许多东西,内容来源的多样性最为普遍。个性化意味着每个用户都能获得它自己感兴趣的结果。相关性意味着一个特定的查询对于某个查询总比其他更合适。显然,这三个属性的定义和标准都不相同。
问题是标准很难打破。
注意:如果你的系统在统计点击量、耗费时间、浏览数、点赞数、分享数等等,你事实上在衡量内容的受欢迎程度。有团队试图学习具备多样性的个性化模型。为个性化,他们加入允许系统进行个性化的特征(有的特征代表用户兴趣),或者加入多样性(表示该文档与其它返回文档有相同特征的特征,比如作者和内容),然后发现这些特征比他们预想的得到更低的权重(有时是不同的信号)。
这不意味着多样性、个性化和相关性就不重要。就像之前的规则指出的,你可以通过后处理来增加多样性或者相关性。如果你看到更长远的目标增长了,那至少你可以声称,除了受欢迎度,多样性/相关性是有价值的。你可以继续使用后处理,或者你也可以基于多样性或相关性直接修改你的目标。
法则43:不同产品中,你的朋友总是同一个,你的兴趣不会如此
谷歌的 ML 团队 常常把一个预测某产品联系紧密程度(the closeness of a connection in one product)的模型,应用在另一个产品上,然后发现效果很好。另一方面,我见过好几个在产品线的个性化特征上苦苦挣扎的团队。是的,之前看起来它应该能奏效。但现在看来它不会了。有时候起作用的是——用某属性的原始数据来预测另一个属性的行为。即便知道某用户存在另一个属性能凑效的历史,也要记住这一点。比如说,两个产品上用户活动的存在或许就自身说明了问题。
阅读过本文的人还看了以下:
分享《深度学习入门:基于Python的理论与实现》高清中文版PDF+源代码
《21个项目玩转深度学习:基于TensorFlow的实践详解》完整版PDF+附书代码
《深度学习之pytorch》pdf+附书源码
李沐大神开源《动手学深度学习》,加州伯克利深度学习(2019春)教材
笔记、代码清晰易懂!李航《统计学习方法》最新资源全套!
《神经网络与深度学习》最新2018版中英PDF+源码
将机器学习模型部署为REST API
FashionAI服装属性标签图像识别Top1-5方案分享
重要开源!CNN-RNN-CTC 实现手写汉字识别
yolo3 检测出图像中的不规则汉字
同样是机器学习算法工程师,你的面试为什么过不了?
前海征信大数据算法:风险概率预测
【Keras】完整实现‘交通标志’分类、‘票据’分类两个项目,让你掌握深度学习图像分类
VGG16迁移学习,实现医学图像识别分类工程项目
特征工程(一)
特征工程(二) :文本数据的展开、过滤和分块
特征工程(三):特征缩放,从词袋到 TF-IDF
特征工程(四): 类别特征
特征工程(五): PCA 降维
特征工程(六): 非线性特征提取和模型堆叠
特征工程(七):图像特征提取和深度学习
如何利用全新的决策树集成级联结构gcForest做特征工程并打分?
Machine Learning Yearning 中文翻译稿
蚂蚁金服2018秋招-算法工程师(共四面)通过
全球AI挑战-场景分类的比赛源码(多模型融合)
斯坦福CS230官方指南:CNN、RNN及使用技巧速查(打印收藏)
python+flask搭建CNN在线识别手写中文网站
中科院Kaggle全球文本匹配竞赛华人第1名团队-深度学习与特征工程
不断更新资源
深度学习、机器学习、数据分析、python
搜索公众号添加: datayx

长按图片,识别二维码,点关注
AI项目体验
https://loveai.tech









