作者:Michael Copeland
翻译:杨光
校对:丁楠雅
资深科技编辑Michael copeland解释了深度学习的基本原理。就像在学校上课一样,神经网络在“训练”阶段得到的教育跟大多数人一样——学会去做一份工作。更具体的说,经过训练的神经网络可以利用自己学到的知识在数字世界中发挥作用,例如:识别图像、口语、判断血液疾病、或是换位思考,你可以将其称之为——被简化过的应用程序形式。这种更快速、高效的神经网络基于训练来推断出所呈现的新数据,在AI词典中,被称之为“推理”。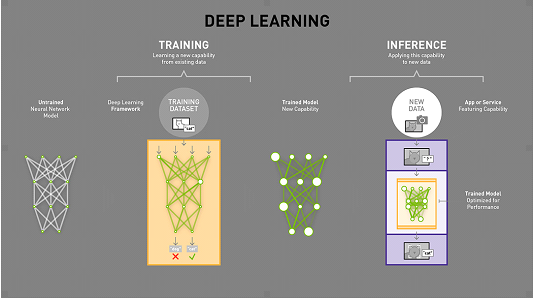
推理是在深入学习训练中所学到的并会投入使用的地方。
没有训练就不会有推理。可以理解,这就是我们在大多数情况下获得并使用知识的方式。就像我们不能拉着我们所有的老师、一些超载的书架以及红砖校园来阅读莎士比亚的十四行诗一样,推理并不需要其训练方案的所有基础设施来做好它的工作。因此,让我们分解推理从训练到推理的过程,以及在人工智能的大背景下应该如何发挥作用。
虽然我们的目标是一致的——知识——神经网络的教育过程或训练(谢天谢地)并不像我们自己那样。神经网络在我们生物学的大脑上松散地建模——神经元之间的所有相互连接。与我们的大脑不同,任何神经元可以和任何神经元有确定物理距离的连接,人造神经网络有单独的层,连接和数据传输的方向。
当训练的神经网络,训练数据被放到网络的第一层和独立神经元中,并且独立神经元根据正在执行的任务为输入的分配权重——这是多么正确或者不正确。在图像识别网络中,第一层可能会寻找边缘。接下来可能会找这些边缘如何形成形状——矩形或圆形。第三层可能会寻找特定的功能——例如闪亮的眼睛和按钮式鼻子。每一层都把图像传递给下一层,直到最终层并且最终输出由所有的这些权重的总和确定。但是这些训练不同于我们自己。我们就说定义猫咪图片的任务吧。神经网络得到所有的这些训练图像,将它们做一个权重并且得出是否是猫的结论。从训练算法中得到的回答只是“对”或“错”。如果算法告知神经网络这是错的,就没有得到正确的回答是什么。错误是神经网络层的后向传播和它要去猜其他的东西。每次尝试必须考虑其他的属性——在我们的“猫性”示例属性——并且在每一层更高或更低权衡被检查过的属性。然后再猜一遍。再一遍。再又一遍。直到它有正确的权重并且每一次训练得到正确的回答。这是一只猫。
训练可以教深度学习网络,以便在网络被用于检测更广阔世界中的猫之前,在一个限制的集合中去正确地标注猫的图片。现在你有一个数据结构,并且根据你在传输训练数据时所学到的内容,平衡了所有权重。这真是一个美丽的调整。问题是,它在小号计算方面也是一个怪物。Andrew Ng曾在谷歌和斯坦福大学打磨自己的人工智能,现在是百度硅谷实验室的首席科学家。他说训练百度的其中一个中文语音识别模型不仅需要4TB的训练数据,还需要20个计算机——在整个训练周期中,这是200亿次数学运算。正尝试在智能手机上运行。适当加权的神经网络的本质是一个笨蛋,大量的数据库。你需要放些什么才能让那个傻瓜学习——类比在我们的教育中所有的那些铅笔,书本,教师的肮脏外表——比你完成特定任务需要的多。难道毕业的重点不是摆脱所有的这些东西吗?重点是如果有人要在现实世界中使用所有的训练,你需要一个快速的应用可以留存学习并快速应用于从来没见过的数据。这是推论:采用较小批量真实世界的数据并快速返回相同的正确答案(实际上是某些事的正确预测)。虽然这是计算机科学领域的全新领域,但主要有两种方法可以采用这种笨重的神经网络并对其进行修改,以提高在其他网络上的运行速度。
推理怎么用?只要打开你的手机。推理被用于深度学习从语义识别去分类你的快照。第一种方法是查看神经网络中经过训练后未激活的部分。这些部分不是必须的,可以“修剪”掉。第二种方法是训中将多层神经网络融合成单个计算步骤的方式。它类似于数字图像中发生的压缩。设计师可能致力于生成巨大,漂亮,百万像素快读和高度的图片,但是当它们放到网上时,它们会转为一个jpeg。他几乎完全相同,人眼无法区分,但是分辨率更小。类似的推理你也会获得几乎与预测相同的准确度,但是对于运行性能进行简化,压缩和优化。这意味着我们所有人都在使用推理。你的智能手机的语音助手使用推理,Google的语音识别,图像搜索和垃圾邮件过滤的应用程序也是如此。百度也在语音识别,恶意软件检测和垃圾邮件过滤上使用推理。Facebook的图像识别和Amazon和Netflix的推荐引擎都依赖于推理。GPU,多亏它们的并行计算能力——或者一次做多件事的能力——在训练和推理上都很好。系统在GPU上训练也允许计算机去判定模式和物体——或在一些情况比人类更好(见“人工智能用GPUs加速:新的计算模式”)。在训练完成后,网络被部署到“推理”领域——依据“推理”结果进行数据分类。这里也一样,GPUs——和他们的并行计算能力——在他们依据训练好的网络运行百万计算去辨别已知的模式和物体提供了优势。你可以看到这些模式和应用将被更小,更快和更精确。训练会不那么繁琐,推理会为我们生活的方方面面带来新的应用。原文标题:
What’s the Difference Between Deep Learning Training and Inference?
原文链接:
https://blogs.nvidia.com/blog/2016/08/22/difference-deep-learning-training-inference-ai/编辑:于腾凯
校对:林亦霖
工作内容:将选取好的外文前沿文章准确地翻译成流畅的中文。如果你是数据科学/统计学/计算机专业的留学生,或在海外从事相关工作,或对自己外语水平有信心的朋友,数据派翻译组欢迎你们加入!
你能得到:提高对于数据科学前沿的认知,提高对外文新闻来源渠道的认知,海外的朋友可以和国内技术应用发展保持联系,数据派团队产学研的背景为志愿者带来好的发展机遇。
其他福利:和来自于名企的数据科学工作者,北大清华以及海外等名校学生共同合作、交流。
点击文末“阅读原文”加入数据派团队~

点击“阅读原文”拥抱组织











