作者:吹牛Z
本文转自:数据不吹牛
本文以豆瓣电影(非TOP250)为例,从数据爬取、清洗与分析三个维度入手,详解和还原数据爬取到分析的全链路。阅读全文大概需要5分钟,想直接看结果或下载源码+数据集的旁友可以空降到文末。
旁友,暑假,已经过了一大半了。
这个遥远而炙热的名词,虽然和小Z这个上班狗已经没有任何关系,但在房间穿着裤衩,吹着空调,吃着西瓜,看着电影,依然是假期最好的打开方式。现在裤衩、空调、西瓜都唾手可得,压力全在电影这边了。
关于电影推荐和排行,豆瓣是个好地方,只是电影TOP250排名实在是太经典,经典到有点老套了。
小Z想来点新花样,于是按默认的“评分最高”来排序,Emmm,结果好像比较小众:
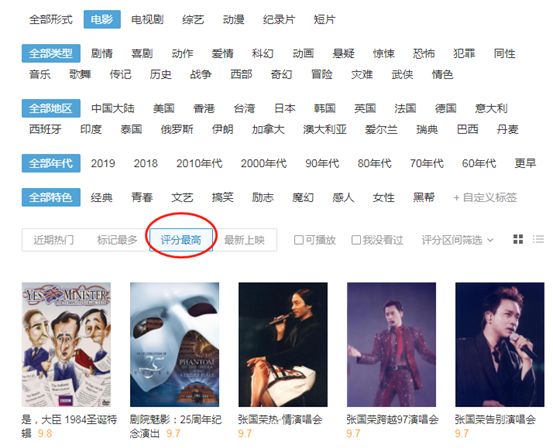
又按年代进行筛选,发现返回的结果和预期差的更远了。
怎么办捏?不如我们自己对豆瓣电影进行更全面的爬取和分析,再DIY评分规则,结合电影上映年代做一个各年代TOP100电影排行榜。

数据爬取
1、网址规律探究
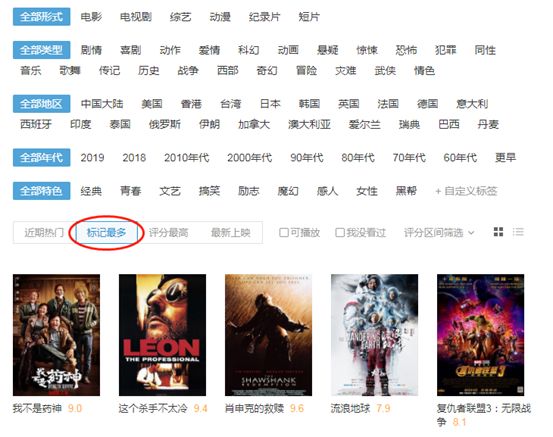
听说看的人越多,评分越有说服力,所以我们进入导航页,选择“标记最多”。(虽然标记的多并不完全等于看的多,但也差不多了)
要找到网址变化规律,常规的套路就是先右键“审查元素”,然后通过不断的点击“加载更多”刷新页面的方式来找规律。
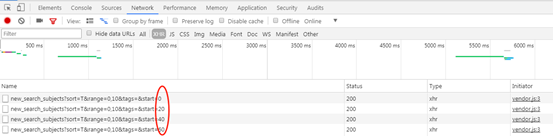
网址规律异常的简单,开头URL不变,每翻一页,start的数值增加20就OK了。
一页是20部电影,开头我们立下的FLAG是要爬取9000部电影,也就是爬取450页。
2、单页解析+循环爬取
豆瓣灰常贴心,每一页都是JSON格式存储的规整数据,爬取和清洗都省了不少事儿:
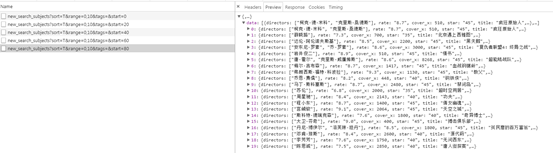
这里我们只需要伪装一下headers里面的user-agent就可以愉快的爬取了:
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'}
直接上单页解析的代码:
def parse_base_info(url,headers): html = requests.get(url,headers = headers) bs = json.loads(html.text) df = pd.DataFrame()for i in bs['data']: casts = i['casts'] #主演 cover = i['cover'] #海报 directors = i['directors'] #导演 m_id = i['id'] #ID rate = i['rate'] #评分 star = i['star'] #标记人数 title = i['title'] #片名 url = i['url'] #网址 cache = pd.DataFrame({'主演':[casts],'海报':[cover],'导演':[directors],'ID':[m_id],'评分':[rate],'标记':[star],'片名':[title],'网址':[url]}) df = pd.concat([df,cache])return df
然后我们写一个循环,构造所需的450个基础网址:
#你想爬取多少页,其实这里对应着加载多少次def format_url(num): urls = [] base_url = 'https://movie.douban.com/j/new_search_subjects?sort=T&range=0,10&tags=%E7%94%B5%E5%BD%B1&start={}'for i in range(0,20 * num,20):
url = base_url.format(i) urls.append(url)return urls
urls = format_url(450)
两个凑一起,跑起来:
result = pd.DataFrame()#看爬取了多少页count = 1for url in urls:df = parse_base_info(url,headers = headers)result = pd.concat([result,df])time.sleep(random.random() + 2)print('I had crawled page of:%d' % count)count += 1
一个大号的功夫,包含电影ID、电影名称、主演、导演、评分、标记人数和具体网址的数据已经爬好了:
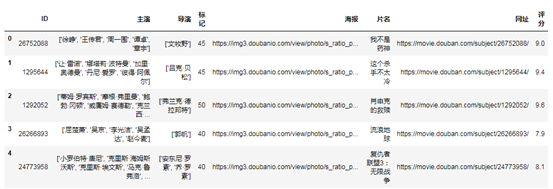
下面,我们还想要批量访问每一部电影,拿到有关电影各星级评分占比等更丰富的信息,后续我们想结合评分分布来进行排序。
3、单部电影详情爬取:
我们打开单部电影的网址,取巧做法是直接右键,查看源代码,看看我们想要的字段在不在源代码中,毕竟,爬静态的源代码是最省力的。

电影名称?在的!导演信息?在的!豆瓣评分?还是在的!一通CTRL+F搜索发现,我们所有需要的字段,全部在源代码中。那爬取起来就太简单了,这里我们用xpath来解析:
def parse_movie_info(url,headers = headers,ip = ''):if ip == '': html = requests.get(url,headers = headers)else: html = requests.get(url,headers = headers,proxies = ip) bs = etree.HTML(html.text)
第二步我们已经拿到了9000部电影所有的网址,只需写个循环,批量访问就可以了。然鹅,尽管设置了访问时间间隔,爬取上千个页面我们就会发现,豆娘还是会把我们给BAN(禁)掉。
回忆一下,我们没有登录,不需要cookies验证,只是因为频繁的访问骚扰到了豆娘。那这个问题还是比较好解决的,此处不留爷,换个IP就留爷。细心的朋友已经发现了,上面针对单部电影的页面解析,有一个默认IP参数,我们只需要在旧IP被禁后,传入新的IP就可以了。
PS:代理IP如果展开讲篇幅太长,网上有许多免费的IP代理(缺点是可用时间短,不稳定)和付费的IP代理(缺点是不免费)。另外,要强调一下这里我们传入的IP长这样:{'https':'https://115.219.79.103:0000'}
movie_result = pd.DataFrame()ip = ''
电影页面数据爬取结果如下:
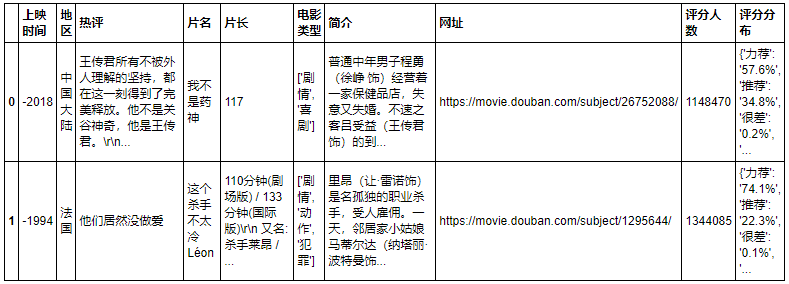

数据清洗
1、基本信息表和电影内容表合并
base_info表里面是我们批量抓取的电影基本信息,movie_info则是我们进入每一部电影,获取到的感兴趣字段汇总,后面的分析是需要依赖两张表进行的,所以我们合并之:
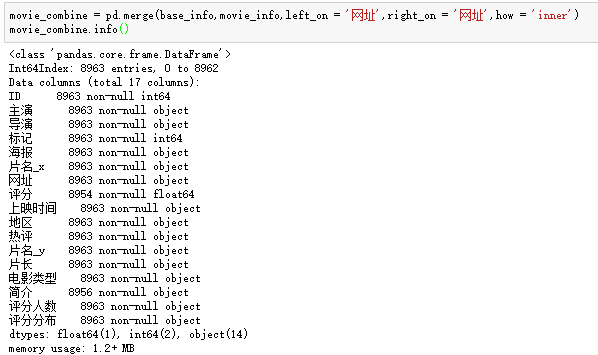
2、电影年份数据清洗:
我们发现之前爬取的上映时间数据不够规整,前面都带了一个“-”:
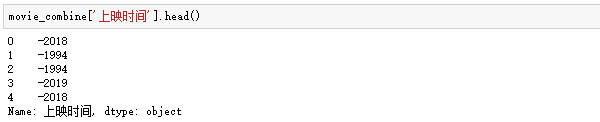
要把前面多余的符号去掉,但发现无论怎么用str.replace返回的都是Nan,原来这里pandas把所有数字默认成负的,所以只需要把这一列所有数字乘-1即可:
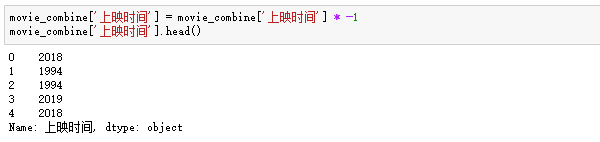
3、评分分布规整:
最终我们是希望能够把电影整体评分(如某电影8.9分)和不同评分等级(5星的占比70%)结合起来分析的。而刚才爬取评分数据的时候,为了偷懒,用的是一个字典把各评分等级和对应的占比给包起来了,然鹅,pandas默认把他当成了字符串,不能直接当做字典处理:

灵光一闪?这种字典形式的字符串,用JSON解析一下不就变字典了?HAVE A TRY:

结果,疯狂报错:

报错貌似在提示我们是最外围的引号错误导致了问题,目前我们用的是双引号("{'a':1}")难道只能用单引号('{'a':1}')?先试试吧:

报错解决了。接下来,我们把字典形式的评分拆成多列,例如每个星级对应一列,且百分比的格式变成数值型的,写个循环函数,用apply应用一下即可:
#把单列字典的评分分布转化成分开的5列,且每一列是数值型的def get_rate(x,types):try:return float(x[types].strip('%'))except:pass movie_combine['5星'] = movie_combine['format_评分'].apply(get_rate,types = '力荐')movie_combine['4星'] = movie_combine['format_评分'].apply(get_rate,types = '推荐')
movie_combine['3星'] = movie_combine['format_评分'].apply(get_rate,types = '还行')movie_combine['2星'] = movie_combine['format_评分'].apply(get_rate,types = '较差')movie_combine['1星'] = movie_combine['format_评分'].apply(get_rate,types = '很差')
现在我们的数据长这样的:
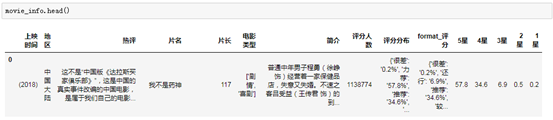
OK,清洗到此告一段落。

数据分析
大家还记得开头的FLAG吗?我们要制作各年代TOP100电影排行榜。所以直接按照年代划分电影,然后按照电影评分排个序不就完事了!
然鹅这听起来有点话糙理也糙。如果只按照电影的总的评分来排序,会忽视掉内部评分细节的差异性,举个例子,搏击俱乐部:
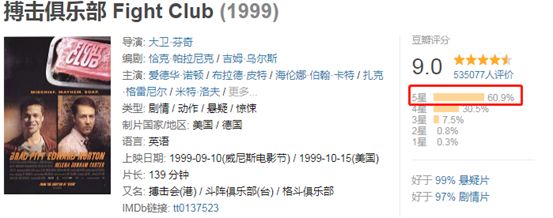
总评分9.0分,打出5星好评的占比60.9%,4星的有30.5%。
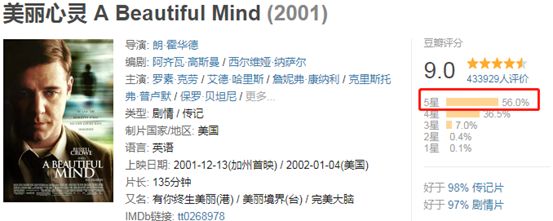
同为9分佳作,给美丽心灵打出5星好评的有56.0%,和搏击俱乐部相比少了4.9%,而4星的人数则高出了6%。可以不负责任的做一个概括:两部都是9分经典,但观众给搏击俱乐部的5星倾向要高于美丽心灵。
GET到这个点,我们就可以对电影评分排序制定一个简单的规则:先按照总评分排序,然后再对比5星人数占比,如果一样就对比4星,以此类推。这个评分排序逻辑用PYTHON做起来不要太简单,一行代码就搞定:
#按照总评分,5星评分人数占比,4星占比,3星..依次类推movie_combine.sort_values(['评分','5星','4星','3星','2星','1星'],ascending = False,inplace = True)
但是仔细看排序结果,我们会发现这样排序的一些小瑕疵,一些高分电影其实是比较小众的,比如“剧院魅影:25周年纪念演出”和“悲惨世界:25周年纪念演唱会”等。
而我们想要找的,是人民群众所喜闻乐见的电影排名,这里只有通过评分人数来代表人民的数量,我们先看一看所有电影的评分人数分布:
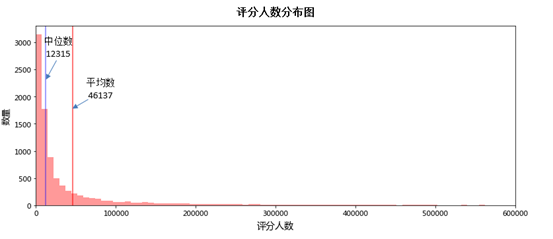
评分人数跨度极大,为了减少极值对于平均的影响,就让中位数来衡量人民群众是否喜闻乐见,所以我们只留下大于中位数的评分。

接着,看看历年电影数量分布情况:
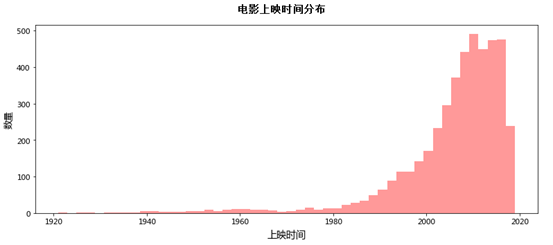
直到2000年初,筛选后的电影年上映数才逼近200,更早时期的电影好像20年加起来还不到100部。为了让结果更加直观,我们来按年代统计电影的上映时间。这里涉及到给每部电影上映时间进行归类,有点棘手啊...
绞尽脑细胞,终于找到了一个比较讨巧的办法,先构造年代标签,再借用cut函数按十年的间隔切分上映时间,最后把标签传入参数。
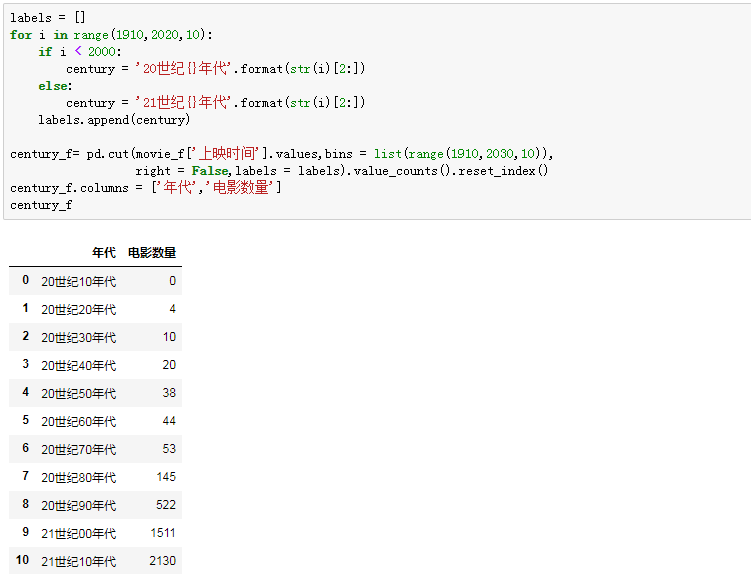
得勒!数据直观的反映出各年代上映量,20世纪80年代前真的是少得可怜。看到这里,不由想到我们最开始立的那个“制作年代TOP100榜单”的FLAG,因为早期电影量的贫乏,是完全站不住脚的了。
不慌,一个优秀的数据分析师,一定是本着具体问题具体分析的精神来调整FLAG的:
- 基于年代上映量数据,我们从20世纪30年代开始制作排名;
- 为了避免有些年代电影过少,优化成各年代TOP 10%的电影推荐;
- 同时,为了避免近年电影过多,每个年代推荐的上限数不超过100部。
看到这三个条件,连一向自傲的潘大师(pandas)都不禁长叹了口气。然鹅大师之所以是大师,就是因为在他眼里没有什么是不可能的。思考1分钟后,确定了灵活筛选的套路:
final_rank = pd.DataFrame()for century,count in zip(century_f.index,century_f.values): f1 = movie_f2.loc[movie_f['年代'] == century,:] #1000部以下的,取TOP10% if count < 1000: return_num = int(count * 0.1) #1000部以上的,取前100部 else: return_num = 100 f2 = f1.iloc[:return_num,:] final_rank = pd.concat([final_rank,f2])
根据上一步构造的century_f变量,结合每个年代上映电影量,不足1000部的筛选前10%,超过1000部的只筛选前100部,结果,就呼之而出了。
在附上代码和榜单之前,我预感到大部分旁友是和我一样懒的(不会仔细看榜单),所以先整理出各年代TOP5电影(有些年代不足TOP5),做一个精华版的历史电影排行榜奉上:

从峰回路转、结尾让人大呼牛逼的《控方证人》,到为无罪真理而辩的《十二怒汉》,再到家庭为重不怒自威的《教父》系列、重新诠释希望和坚韧的《肖申克的救赎》以及将励志提升到新高度的《阿甘正传》(小Z阅片尚浅,榜单上只看过这些)。
每一部好的电影,都是一块从高空坠落的石头,它总能在人们的心湖上激起水花和涟漪,引起人们对生活、社会以及人性的思考。而烂片,就是从高空坠落的空矿泉水瓶,它坠势汹汹,但最终只会浮在水面,让看过的人心存芥蒂,感觉灵魂受到污染。
有了新的电影排名榜单,再也不用担心剧荒了。
爬取、清洗、分析每一步详解代码和完整的电影排序名单
后台回复“豆瓣电影”即可获取