这里是python3学习笔记的第八篇。初涉爬虫,请多多指教。
最近国自然评审结果出炉,几家实验室欢喜几家愁,今天就通过爬取国自然网页来简单介绍一下python爬虫。今天要用到的包是经常出现的包:
Beautiful Soup 是一个可以从HTML或XML文件中提取数据的Python库.它能够通过你喜欢的转换器实现惯用的文档导航,查找,修改文档的方式.Beautiful Soup会帮你节省数小时甚至数天的工作时间.
首先是是安装python包
urllib库是python内置的,无需我们额外安装。
pip3 install beautifulsoup4,requests
pycharm可以在底下的终端界面安装,安装完可以简单测试一下:
from bs4 import BeautifulSoup
soup = BeautifulSoup('Hello
', 'html.parser')
print(soup.p.string)
---
Hello
一个经典的例子:
html_doc = """
<html><head><title>The Dormouse's storytitle>head>
<body>
<p class="title"><b>The Dormouse's storyb>p>
<p class="story">Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1">
Elsiea>,
<a href="http://example.com/lacie" class="sister" id="link2">Laciea> and
<a href="http://example.com/tillie" class="sister" id="link3">Tilliea>;
and they lived at the bottom of a well.p>
<p class="story">...p>
"""
可以将使用BeautifulSoup 对象按照标准格式输出:
from bs4 import BeautifulSoup
soup = BeautifulSoup(html_doc, 'html.parser')
print(soup.prettify())
同时也包含几个获取元素的方法:
soup.title
# <title>The Dormouse's storytitle>
soup.title.name
# u'title'
soup.title.string
# u'The Dormouse's story'
soup.title.parent.name
# u'head'
soup.p
# <p class="title"><b>The Dormouse's storyb>p>
soup.p['class']
# u'title'
soup.a
# <a class="sister" href="http://example.com/elsie" id="link1">Elsiea>
soup.find_all('a')
# [<a class="sister" href="http://example.com/elsie" id="link1">Elsiea>,
# <a
class="sister" href="http://example.com/lacie" id="link2">Laciea>,
# <a class="sister" href="http://example.com/tillie" id="link3">Tilliea>]
soup.find(id="link3")
# <a class="sister" href="http://example.com/tillie" id="link3">Tilliea>
国自然的小案例:
登入页面
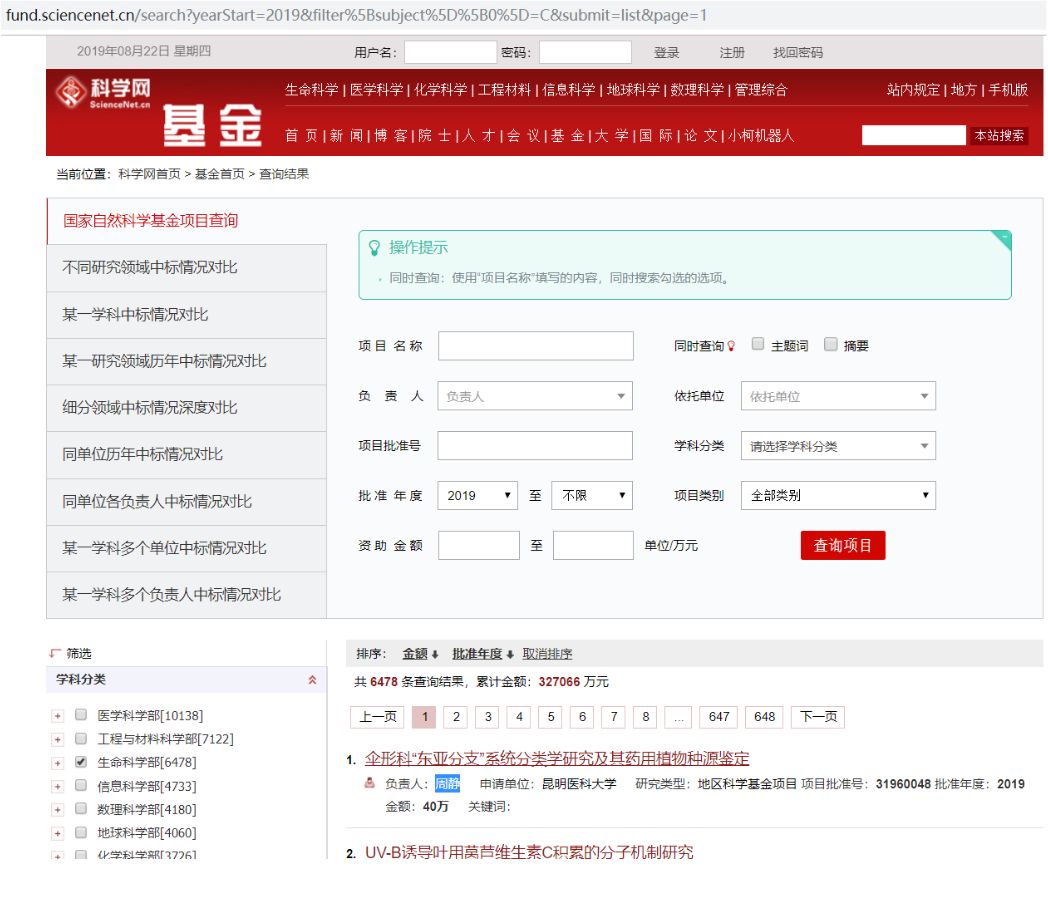
然后右键查看网页源代码:
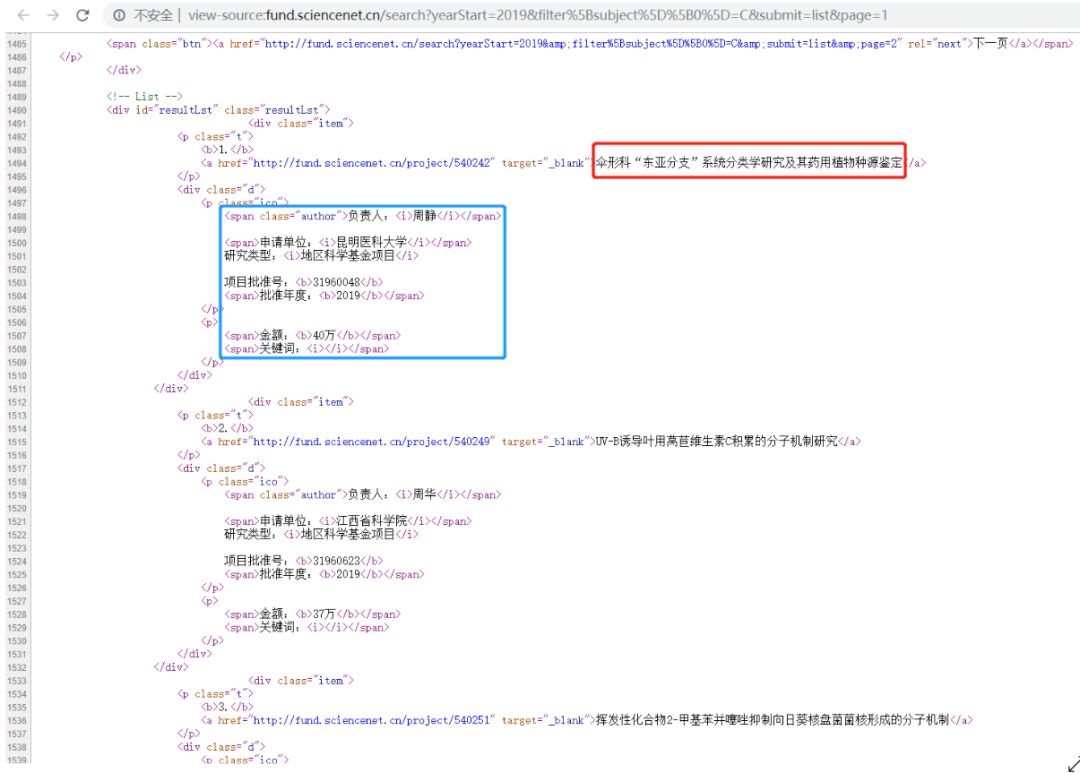
获取上图中的信息,代码如下:
# -*- coding:UTF-8 -*-
from bs4 import BeautifulSoup
import requests
if __name__ == "__main__":
server =
target =
req = requests.get(url=target)
html= req.text
div_bf = BeautifulSoup(html)
div = div_bf.find_all(
a_bf = BeautifulSoup(str(div[0]))
A = a_bf.find_all(
span = a_bf.find_all(
for eachs in A:
print(eachs.string)
for each in span:
i = each.children
for child in i:
print(child.string)
结果如下:
伞形科“东亚分支”系统分类学研究及其药用植物种源鉴定
UV-B诱导叶用莴苣维生素C积累的分子机制研究
...
负责人:
周静
申请单位:
昆明医科大学
批准年度:
2019
金额:
40万
关键词:
None
负责人:
周华
申请单位:
江西省科学院
批准年度:
2019
金额:
37万
关键词:
None
...
由于技术不到家和篇幅问题,并没有完全展示所有抓取到的信息。将其整理成制表符分割的形式就能够用于筛查和统计。然后,网页循环,爬虫能够获取选定条件的完整信息。
最后,专题的内容也整理放送,希望你会有所收获。
三剑客 PyCharm使用 | 编程基础与规范代码 | 列表使用一文就够了 | 元组拆包是个啥?| 字典与FASTA文件序列抽提 | 如何判断序列是否跨过剪切位点
参考资料:
https://beautifulsoup.readthedocs.io/zh_CN/latest/






