作者:Jose Garcia
翻译:张睿毅
校对:张一豪
作者给出了假设检验的解读与Python实现的详细的假设检验中的主要操作。
也许所有机器学习的初学者,或者中级水平的学生,或者统计专业的学生,都听说过这个术语,假设检验。我将简要介绍一下这个当我学习时给我带来了麻烦的主题。我把所有这些概念放在一起,并使用python进行示例。什么是假设检验?我们为什么用它?什么是假设的基本条件?什么是假设检验的重要参数?假设检验是一种统计方法,用于使用实验数据进行统计决策。假设检验基本上是我们对人口参数做出的假设。例如:你说班里的学生平均年龄是40岁,或者一个男生要比女生高。我们假设所有这些例子都需要一些统计方法来证明这些。无论我们假设什么是真的,我们都需要一些数学结论。假设检验是统计学中必不可少的过程。假设检验评估关于总体的两个相互排斥的陈述,以确定样本数据最佳支持哪个陈述。当我们说一个发现具有统计学意义时,这要归功于一个假设检验。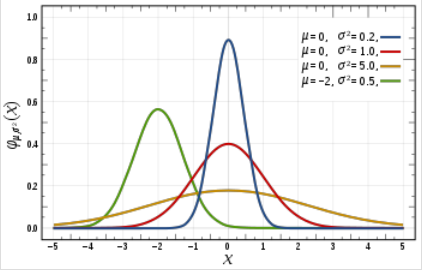
假设的基础是规范化和标准规范化
(链接https://en.wikipedia.org/wiki/Normalization_(statistics);https://stats.stackexchange.com/questions/10289/whats——the——difference——between——normalization——and——standardization)。我们所有的假设都围绕这两个术语的基础。让我们看看这些。
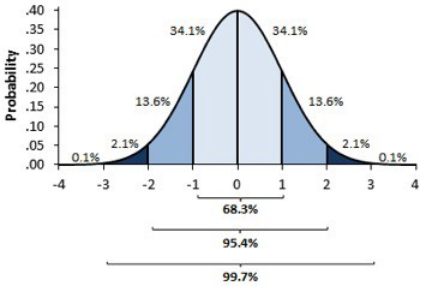
标准化的正态曲线图像和数据分布及每个部分的百分比
你一定想知道这两个图像之间有什么区别,有人可能会说我找不到,而其他人看到的图像会比较平坦,而不是陡峭的。好吧伙计这不是我想要表达的,首先你可以看到有不同的正态曲线所有那些正态曲线可以有不同的均值和方差,如第二张图像,如果你注意到图形是合理分布的,总是均值= 0和方差= 1。当我们使用标准化的正态数据时,z—score的概念就出现了。
如果变量的分布具有正态曲线的形状——一个特殊的钟形曲线,则该变量被称为正态分布或具有正态分布。正态分布图称为正态曲线,它具有以下所有属性:1.均值,中位数和众数是相等。
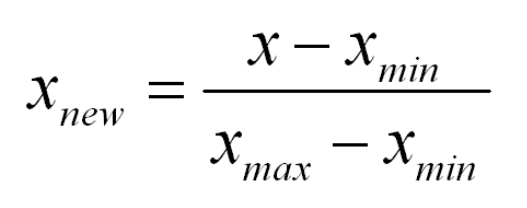
正态分布方程
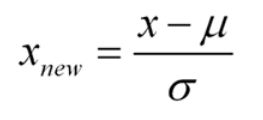
标准化正态分布
在推论统计中,零假设是一种普遍的说法或默认的观点,即两个测量现象之间没有关系,或者分组间没有关联换句话说,它是一个基本假设,或基于领域或问题知识。另一种假设是假设检验中使用的假设与零假设相反。通常认为观察是真实效果的结果(叠加了一定量的偶然的变化)
零假设与备择假设
重要程度:指我们接受或拒绝无效假设的重要程度。接受或拒绝假设不可能100%准确,因此我们选择通常为5%的重要程度。这通常用alpha(数学符号)表示,通常为0.05或5%,这意味着您的输出应该有95%的信心在每个样本中给出类似的结果。I型错误:当我们拒绝零假设时,尽管该假设是正确的。类型I错误由alpha表示。在假设检验中,显示关键区域的正常曲线称为α区域II型错误:当我们接受零假设但它是错误的。II型错误用beta表示。在假设检验中,显示接受区域的正常曲线称为β区域。单尾测试:统计假设的测试,其中拒绝区域仅在采样分布的一侧,称为单尾测试。例如:一所大学有≥4000名学生或数据科学≤80%采用的组织。双尾测试:双尾测试是一种统计测试,其中分布的关键区域是双侧的,并测试样本是否大于或小于某个值范围。如果被测试的样本属于任一关键区域,则接受替代假设而不是零假设。例如:一所大学!= 4000名学生或数据科学!= 80%的组织采用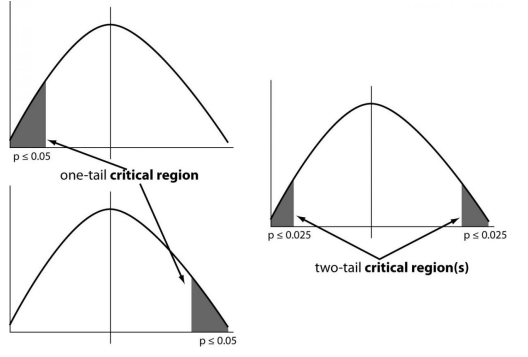
单尾和双尾图像
P值:P值或计算概率是当研究问题的零假设(H 0)为真时,找到观察到的或更极端的结果的概率 —— “极端”程度的定义取决于假设如何被检测。如果您的P值小于选定的显着性水平,那么就拒绝原假设,即接受样本提供合理的证据来支持备选假设。它并不意味着“有意义”或“重要”的差异;这是在考虑结果的真实相关性时决定的。例如:你有一枚硬币而你不知道这是否公平或棘手所以让我们决定零和备择假设H1:硬币是一个狡猾的硬币。并且alpha = 5%或0.05第一次投掷硬币,结果是尾部P值= 50%(头部和尾部的概率相等)第二次抛硬币,结果是尾巴,现在p值= 50/2 = 25%同样地,我们连续6次投掷并得到P值= 1.5%的结果,但是我们将显着性水平设置为95%表示我们允许的5%错误率,在这里我们看到我们超出了那个水平,即我们的零假设不成立,所以我们需要拒绝并提出这个硬币实际上是一个狡猾的硬币。自由度: 现在想象你对期望值没有兴趣,你对数据分析感兴趣。您有一个包含10个值的数据集。如果你没有估算任何东西,每个值都可以取任何数字,对吧?每个值都可以完全自由变化。但是假设您想使用单样本t检验来测试10个值的样本的总体平均值。你现在有一个约束——平均值的估计。究竟是什么约束?通过定义均值,必须保持以下关系:数据中所有值的总和必须等于n x mean,其中n是数据集中的值的数量。
因此,如果数据集有10个值,则10个值的总和必须等于平均值x 10.如果10个值的平均值为3.5(您可以选择任何数字),则此约束要求10个值的总和必须等于10 x 3.5 = 35。使用该约束,数据集中的第一个值可以自由变化。无论它是什么价值,所有10个数字的总和仍然可以具有35的值。第二个值也可以自由变化,因为无论你选择什么值,它仍然允许所有值的总和的可能性是35岁。T校验(学生T校验)
Z校验
ANOVA校验
卡方检验
T—检验:t检验是一种推论统计量,用于确定在某些特征中可能与两组的均值之间是否存在显着差异。它主要用于数据集,如通过翻转硬币100次记录为结果的数据集,将遵循正态分布并且可能具有未知的方差(链接:https://www.investopedia.com/terms/v/variance.asp)。T检验用作假设检验工具(链接:https://www.investopedia.com/terms/h/hypothesistesting.asp),其允许测试适用于群体的假设。
单样本t检验
双样本t检验
单样本t检验:单样本t检验确定样本均值是否与已知或假设的总体均值具有统计学差异。单样本t检验是参数检验。例如:你有10个年龄,你正在检查平均年龄是否为30岁。 (使用python查看下面的代码)
from scipy.stats import ttest_1sampimport numpy as npages = np.genfromtxt(“ages.csv”)print(ages)ages_mean = np.mean(ages)print(ages_mean)tset, pval = ttest_1samp(ages, 30)print(“p-values”,pval)if pval < 0.05: # alpha value is 0.05 or 5% print(" we are rejecting null hypothesis")else: print("we are accepting null hypothesis”)单样本t测试结果
双样本t检验:独立样本t检验或双样本t检验比较两个独立组的平均值,以确定是否有统计证据表明相关的人口均值存在显着差异。独立样本t检验是参数检验。该测试也称为:独立t检验。
示例:在week1和week2之间是否存在任何关联(代码在下面的python中给出)
from scipy.stats import ttest_indimport numpy as npweek1 = np.genfromtxt
("week1.csv", delimiter=",")
week2 = np.genfromtxt
("week2.csv", delimiter=",")print(week1)
print("week2 data :-\n")print(week2)
week1_mean = np.mean(week1
)week2_mean = np.mean(week2)print
("week1 mean value:",week1_mean)print
("week2 mean value:",week2_mean)
week1_std = np.std(week1)week2_std =
np.std(week2)print("week1 std value:",week1_std)
print("week2 std value:",week2_std)
ttest,pval = ttest_ind(week1,week2)print
("p-value",pval)if pval <0.05: print
("we reject null hypothesis")else: print("we accept null hypothesis”)
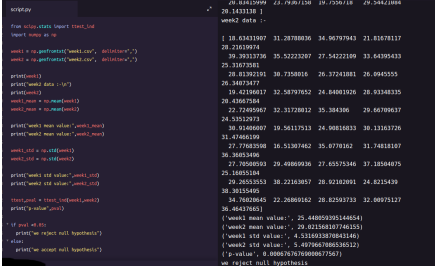
双样本t校验结果
配对样本t检验:配对样本t检验也称为依赖样本t检验。这是一个单变量测试,测试2个相关变量之间的显着差异。这方面的一个例子是,如果您在某些治疗,病症或时间点之前和之后收集个人的血压。import pandas as pd
from scipy import stats
df = pd.read_csv("blood_pressure.csv")
df[['bp_before','bp_after']].describe()
ttest,pval = stats.ttest_rel(df['bp_before'], df['bp_after'])
print(pval)
if pval<0.05:
print("reject null hypothesis")
else:
print("accept null hypothesis")
在统计学中使用几种不同类型的校验(即f检验,卡方检验,t检验)(链接:https://www.statisticshowto.datascie
ncecentral.com/
probability——and——statistics/hypothesis——testing/f——test/
; https://www.statisticshowto.datasciencecentral.
com/probability——and——statistics/chi——square/https://www.statisticshowto.
datasciencecentral.com/
probability——and——statistics/t——test/ )。
在下列情况下,您将使用Z测试:
您的样本量大于30。(链接:
https://www.statisticshowto.datasciencecentral.com/probability——and——statistics/find——sample——size/)否则,请使用t检验。
数据点应彼此独立。(链接:
https://www.statisticshowto.datasciencecentral.com/probability——and——statistics/dependent——events——independent/)换句话说,一个数据点不相关或不影响另一个数据点。
您的数据应该是正常分布的。但是,对于大样本量(超过30个),这并不总是重要的。
您的数据应从人口中随机选择,每个项目都有相同的选择机会。
如果可能的话,样本量应该相等。
再举一个例子,我们使用z-test进行血压测量,如156个单样本Z检验。
import pandas as pd
from scipy import statsfrom statsmodels.stats
import weightstats as stestsztest ,pval = stests.ztest(df['bp_before'], x2=None, value=156)
print(float(pval))if pval<0.05:
print("reject null hypothesis")
else:
print("accept null hypothesis")
双样本Z检验 —— 在两个样本z检验中,类似于t检验,我们检查两个独立的数据组并确定两个组的样本均值是否相等。例:我们检查血液之后和血液数据之前的血液数据。(下面是python代码)
ztest ,pval1 = stests.ztest(df['bp_before'],
x2=df['bp_after'],
value=0,alternative='two-sided')print(float(pval1))if pval<0.05:
print("reject null hypothesis")else: print("accept null hypothesis")
ANOVA(F-检验):t检验在处理两组时效果很好,但有时我们想要同时比较两组以上。例如,如果我们想根据种族等某些分类变量来测试选民年龄是否不同,我们必须比较每个级别的平均值或对变量进行分组。我们可以为每对组进行单独的t检验,但是当你进行多次检测时,你会增加误报的可能性。方差分析或ANOVA
(链接:https://en.wikipedia.org/
wiki/Analysis_of_variance)是一种统计推断测试,可让您同时比较多个组。
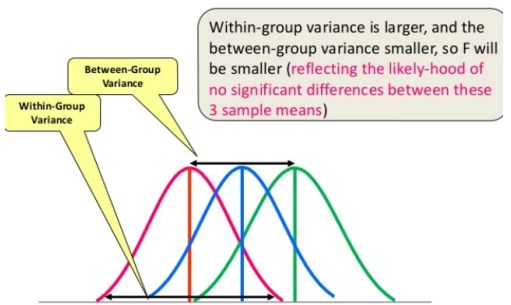
F校验或ANOVA实例图
与z和t分布不同,F分布没有任何负值,因为由于每个偏差的平方,组内变异和组内变异总是正的。单向F检验(ANOVA):根据它们的平均相似度和f分数来判断两个或更多个组是否相似。示例:有3种不同的植物类别及其重量,需要检查所有3组是否相似(下面是python代码)df_anova = pd.read_csv('PlantGrowth.csv')
df_anova = df_anova[['weight','group']]grps = pd.unique(df_anova.group.values)
d_data = {grp:df_anova['weight'][df_anova.group == grp] for grp in grps}
F, p = stats.f_oneway(d_data['ctrl'], d_data['trt1'], d_data['trt2'])
print("p-value for significance is: ", p)
if p<0.05:
print("reject null hypothesis")
else:
print("accept null hypothesis")
双向F检验: 双向F检验是单向检验的扩展(链接:https://stattrek.com/Help/Glossary.aspx?Target=Categorical%20variable),当我们有2个自变量和2个以上的组时使用它。双向F检验并不能说明哪个变量占主导地位。如果我们需要检查个体意义,则需要进行事后测试。现在让我们来看看平均作物产量(不是任何小组的平均作物产量),以及每个因子的平均作物产量,以及组合在一起的因子import statsmodels.api as sm
from statsmodels.formula.api import olsdf_anova2 =
pd.read_csv
("https://raw.githubusercontent.com/Opensourcefordatascience/Data-sets/master/crop_yield.csv")
model = ols('Yield ~ C(Fert)*C(Water)'
, df_anova2).fit()print(f"Overall model F
({model.df_model: .0f},{model.df_resid: .0f}) = {model.fvalue: .3f}, p = {model.f_pvalue: .4f}")
res = sm.stats.anova_lm(model, typ= 2)res
(链接:https://stattrek.com/Help/
Glossary.aspx?Target=Categorical%20variable),将应用此测试。它用于确定两个变量之间是否存在显着关联。
例如,在选举调查中,选民可能按性别(男性或女性)和投票偏好(民主党,共和党或独立团体)进行分类。我们可以使用卡方检验来确定独立性,以确定性别是否与投票偏好相关df_chi = pd.read_csv('chi-test.csv')
contingency_table=pd.crosstab(df_chi["Gender"],df_chi["Shopping?"])
print('contingency_table :-\n',contingency_table)
#Observed ValuesObserved_Values = contingency_table.values print
("Observed Values :
\n",Observed_Values)b=stats.chi2_contingency(contingency_table)
Expected_Values = b[3]print
("Expected Values :-\n",Expected_Values)
no_of_rows=len(contingency_table.iloc[0:2,0])
no_of_columns=len(contingency_table.iloc[0,0:2])ddof=(no_of_rows-1)*(no_of_columns-1)print
("Degree of Freedom:-",ddof
)alpha = 0.05from scipy.stats import chi2chi_square=sum([(o-e)
**2./e for o,e in zip(Observed_Values,Expected_Values)])
chi_square_statistic=chi_square[0]+chi_square[1]print
("chi-square statistic:-",chi_square_statistic)
critical_value=chi2.ppf(q=1-alpha,df=ddof)print
('critical_value:',critical_value)
#p-valuep_value=1-chi2.cdf(x=chi_square_statistic,df=ddof)
print('p-value:',p_value)print('Significance level: ',alpha)
print('Degree of Freedom: ',ddof)
print('chi-square statistic:',chi_square_statistic)
print('critical_value:',critical_value)print('p-value:',p_value)
if chi_square_statistic>=critical_value: print
("Reject H0,There is a relationship
between 2 categorical variables")
else: print("Retain H0,There is no relationship
between 2 categorical variables")
if p_value<=alpha: print
("Reject H0,There is a relationship
between 2 categorical variables")else: print
("Retain H0,There is no relationship between 2 categorical variables")
原文链接:
https://towardsdatascience.com/hypothesis-testing-in-machine-learning-using-python-a0dc89e169ce编辑:于腾凯
校对:林亦霖
张睿毅,北京邮电大学大二物联网在读。我是一个爱自由的人。在邮电大学读第一年书我就四处跑去蹭课,折腾整一年惊觉,与其在当下焦虑,不如在前辈中沉淀。于是在大二以来,坚持读书,不敢稍歇。资本主义国家的科学观不断刷新我的认知框架,同时因为出国考试很早出分,也更早地感受到自己才是那个一直被束缚着的人。太多真英雄在社会上各自闪耀着光芒。这才开始,立志终身向遇到的每一个人学习。做一个纯粹的计算机科学里面的小学生。喜欢算法,数据挖掘,图像识别,自然语言处理,神经网络,人工智能等方向。
工作内容:需要一颗细致的心,将选取好的外文文章翻译成流畅的中文。如果你是数据科学/统计学/计算机类的留学生,或在海外从事相关工作,或对自己外语水平有信心的朋友欢迎加入翻译小组。
你能得到:定期的翻译培训提高志愿者的翻译水平,提高对于数据科学前沿的认知,海外的朋友可以和国内技术应用发展保持联系,THU数据派产学研的背景为志愿者带来好的发展机遇。
其他福利:来自于名企的数据科学工作者,北大清华以及海外等名校学生他们都将成为你在翻译小组的伙伴。
点击文末“阅读原文”加入数据派团队~

点击“阅读原文”拥抱组织










